


서비스를 운영하다 보면 원인 미상의 이유로 application이 kill 되는 경우가 있다. 하지만 운영하는 입장에서 이유를 모른다고 application 재시작만 할 수는 없다.
이러한 문제가 생겼을 때 중요한 것은 root cause가 무엇인지, 그래서 무엇을 고쳐야 하는지 문제를 “특정” 하는 것이다.
로그, 모니터링 툴을 통해서도 원인을 특정하지 못한다면, 마지막 방법으로 heap dump를 살펴보는 것을 선택하는데 어떻게 접근 하는지 정리해두고자 한다. 최소한 긴급한 상황에 재시작 전, heap dump를 받아서 분석하면 문제 해결에 더욱 가까워 질 것이다.
Heap dump란 무엇인가?
Java, Kotlin 을 통해 클래스의 instance를 생성한다면 그것은 heap memory에 올라온다.
Heap dump는 특정 “시점”에 heap memory에 무엇이 저장되어 있는지 snapshot을 찍어 상세하게 살펴보고자 할 때 heap dump를 선택하게 된다.
이러한 heap 영역엔 JVM에 어플리케이션이 start up 하면서 개수 혹은 크기가 늘어나고 줄어드는 하나의 시점의 상태를 살펴볼 수 있게된다.
좀 더 상세하게 아래와 같은 정보를 확인할 수 있다.
•
Address type
•
Class name, size
•
Instance가 참조하고 있거나, 참조되는 곳
또한 heap dump는 2가지 형태가 있다.
•
Classic format
◦
ASCII로 작성되어 human readable 하다.
•
Portable heap dump format
◦
Default, binary로 구성되어 있어 분석 툴을 이용해야 확인할 수 있다.
Tools
Optimize java 에서 보면 Visual VM이 나오고 이것으로 충분히 분석할 수 있지만, 현업에서 가장 먼저 알게된 툴은 MAT(eclipse) 이다.

Heap dump 생성하기
만약 Spring actuator 를 사용한다면, heap dump를 받을 수 있도록 option을 추가할 수 있으며, API endpoint를 통해 다운받을 수 있다.
만약 actuator로 이러한 설정을 추가해두지 않았다면, command line 으로 heap dump를 추출할 수 있다.
jmap -dump:[live],format=b,file=<file-path> <pid>
Shell
복사
•
live 살아있는 객체만 print 한다.
•
format -b binary 형태로 받겠다.
•
file dump의 위치
•
pid Java process ID
jmap -dump:live,format=b,file=/tmp/dump.hprof 12587
Shell
복사
/tmp/dump.hprof 에 PID 12587 java application의 힙 덤프를 받는다.
이렇게 만들어진 heap dump가 만약 pod에 있다면 다음의 명령어로 local file system에 옮길 수 있다.
kubectl cp <file-spec-src> <file-spec-dest> [options]
Shell
복사
Kubectl cp 의 매뉴얼
OutOfMemoryError의 Root Cause 찾아내기
이렇게 heap의 snapshot을 생성한다면 위에서 언급한 tool을 사용해 원인을 찾아야 한다.
필자는 MAT를 더 자주 사용하기 때문에 MAT 기준으로 설명하겠다.
Heap dump를 MAT로 불러오기
이 내용은 간단하다. 저장된 heap dump 파일을 file → open 으로 찾아오면 된다. 상세한 설명은 MAT의 공식 문서 링크를 두겠다.
일단 Dump 파일을 열면 아래와 같은 overview가 나타난다.
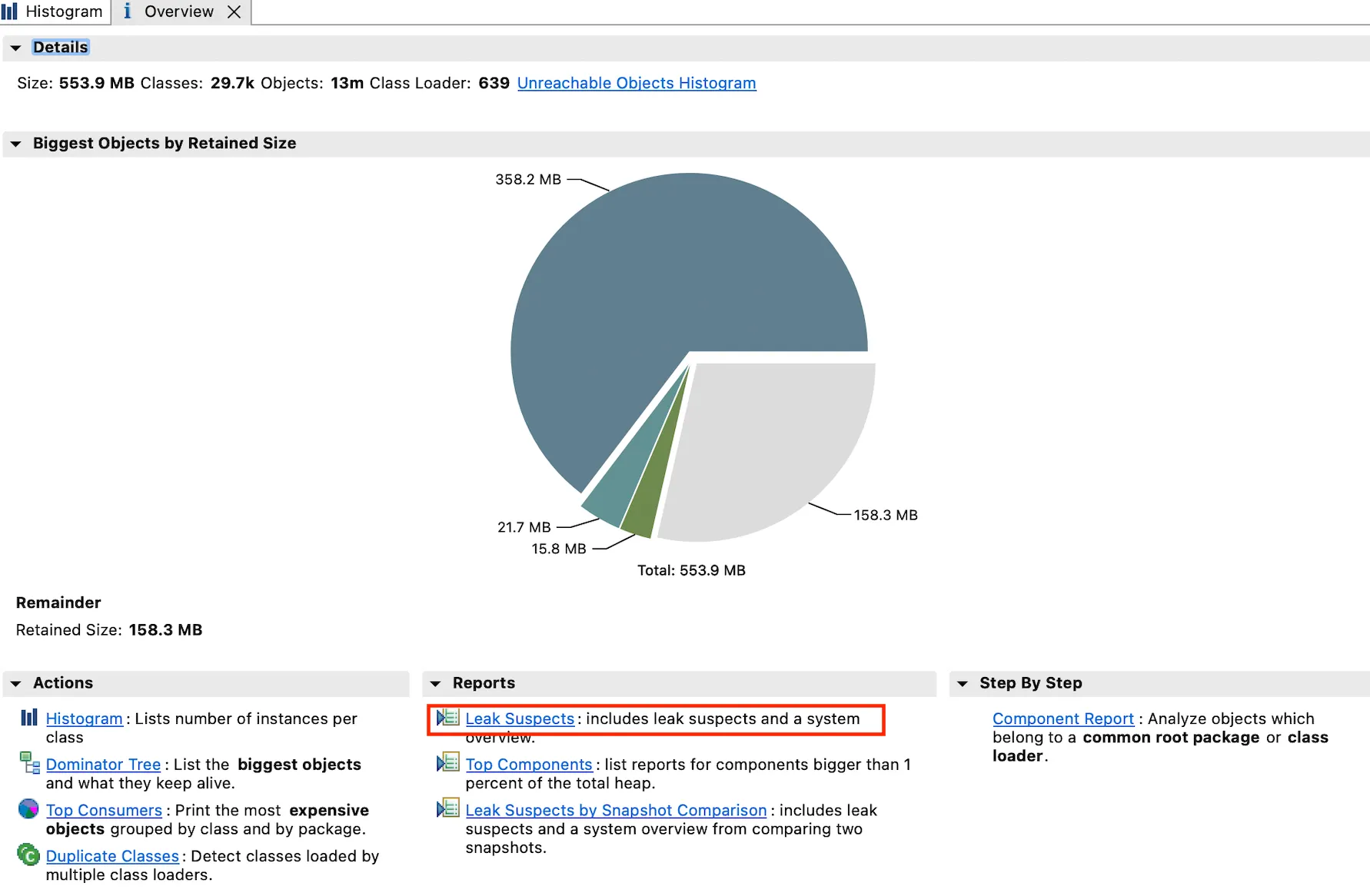
여기서 reports 부분의 Leak suspects 를 클릭하면 아래와 같은 화면이 나타난다.
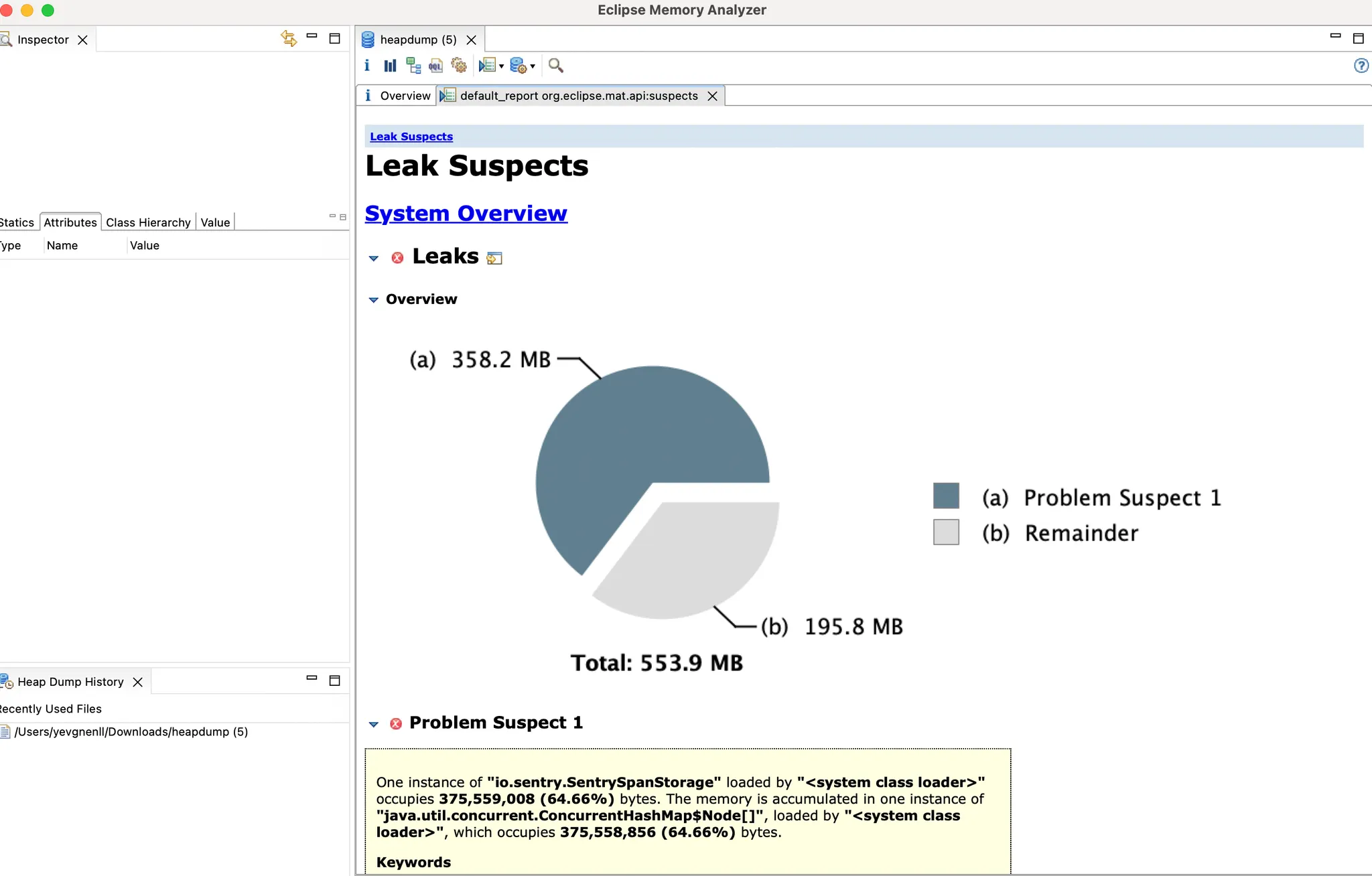
범례를 보면 (a) Problem suspect 1 과 (b) Remainder 가 있다.
Leak suspects (누출 원인) report 이다.
즉, (a) Problem suspect 1 이라는 부분이 현재 메모리가 부족하게 된 원인이라 볼 수 있다.
필자는 7년차의 개발자로 여태까지 약 6번의 문제를 heap dump로 해결하였는데 이 모든 케이스의 공통점은 (a) Problem suspect 1 이 무엇이고 왜 생겼는지 살펴보면 문제가 해결되었다.

Problem suspect 1 의 객체가 생성된 이유에 집중하는 것이 더 합리적인 이유.
GC는 이미 훌륭하고 상당히 검증되었다. 때문에 garbage collect 에서 문제가 되기보다, 개발자가 의도하지 않았지만 과도하게 생성되는 객체가 누수의 원인이 되는것으로 여겨진다. (한때 함께 일한 개발자는 셰난도어 부터는 굳이 공부하거나 분석할 필요가 없을 수준으로 매우 뛰어나다고 한다. 그래도 공부는 해두자)
물론 suspects가 2개 이상일 수 있다.
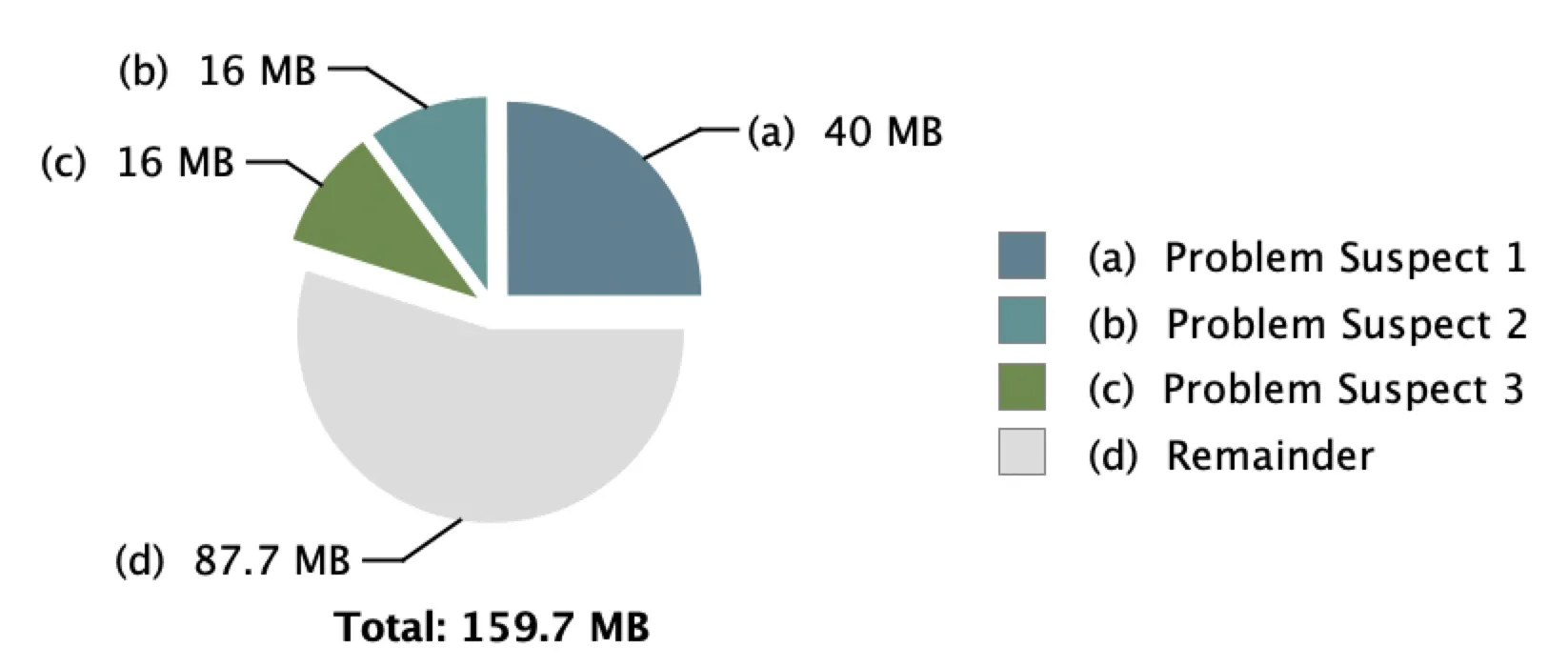
그렇다면 더 상세한 분석이 필요하다.
어디서 만들어진 클래스인가?
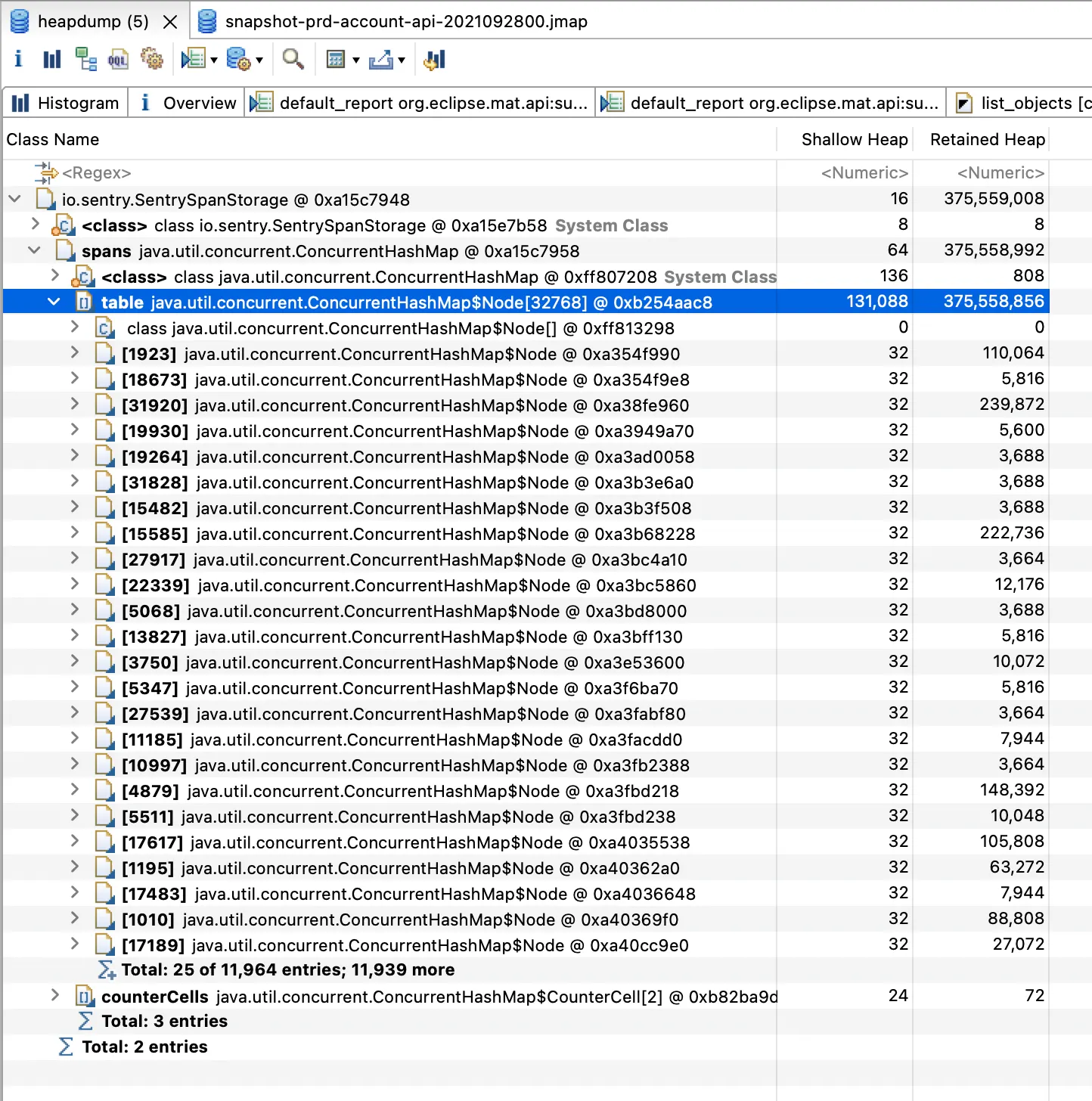
One instance of io.sentry.SentrySpanStorage loaded by <system class loader> occupies 375,559,008 (64.66%) bytes. The memory is accumulated in one instance of java.util.concurrent.ConcurrentHashMap$Node[], loaded by <system class loader>, which occupies 375,558,856 (64.66%) bytes.
Keywords
io.sentry.SentrySpanStorage
java.util.concurrent.ConcurrentHashMap$Node[]
System class load 에서 로드한 io.sentry.SentrySpanStorage 인스턴스가 약 65%의 메모리를 차지한다는 내용이다.
그렇다면 현재 Out of memory Error의 가장 큰 원인은 io.sentry.SentrySpanStorage 의 무분별한 생성으로 특정할 수 있게 된다.
이것은 error monitoring tool로 서버에서 사용하고 있는 것인데 비즈니스 로직과 관계 없이 바로 이 툴로 인해서 메모리가 부족했다는 것이다.
어떤 객체가 생성되고 GC되지 못한 것일까?
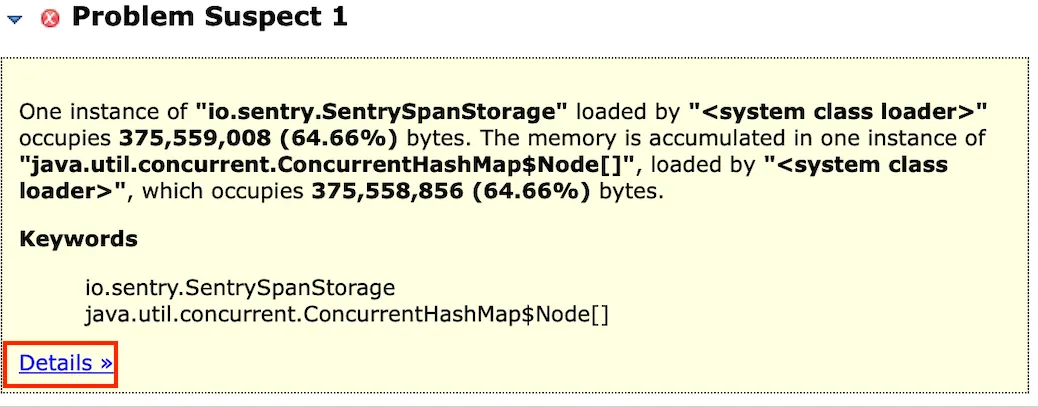
Details 를 클릭해보면 더 자세한 정보를 확인할 수 있다.
어떤 객체가 몇개나 생겼고 어느정도 heap을 차지하는지 확인해보자.
Suspects가 한개라면 거의 이름만 보고도 원인을 특정할 수 있겠지만, 2개 이상이면 좀 더 확인이 필요할 것이다.
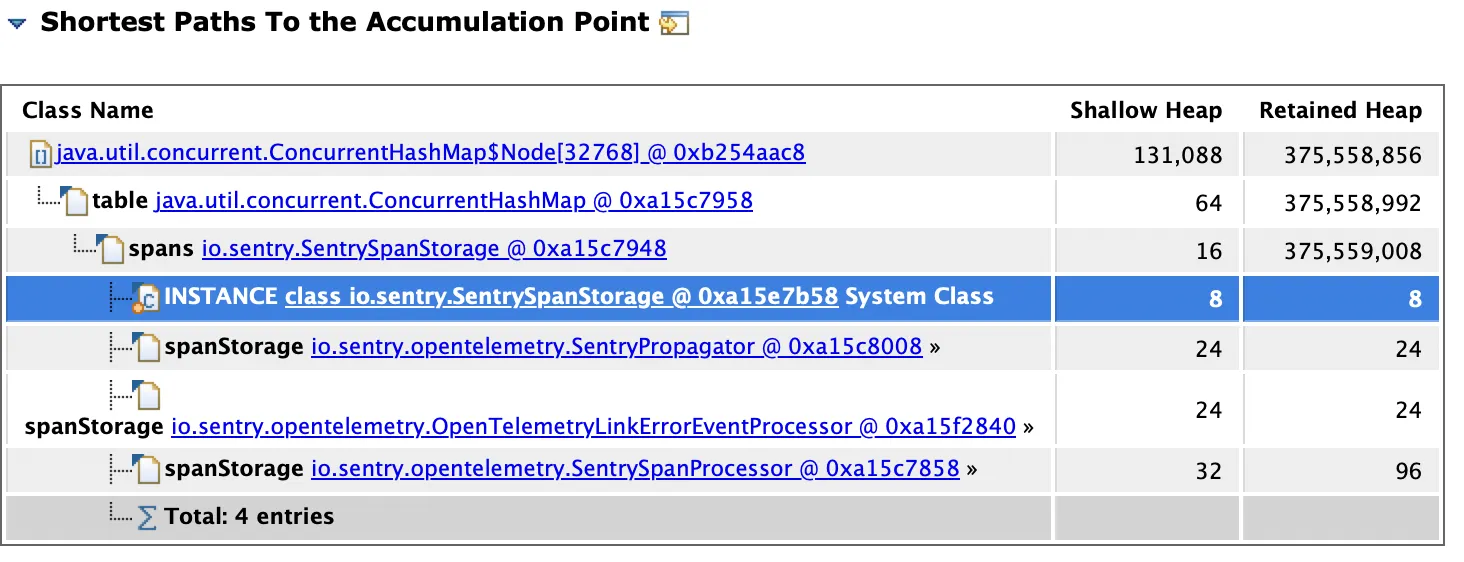
Heap에 있는 instance의 스냅샷
CocurrentHashMap에 저장된 SentrySpanStorage 라는 객체가 너무 많이 생겼다.
이 인스턴스가 너무 많은 메모리를 차지하고 적절할 때 minor GC, full GC가 발생하지 않았거나 혹은 적절히 GC되었다 하더라도 GC 속도에 비해 객체 생성의 속도가 너무 빨랐을 것이다.
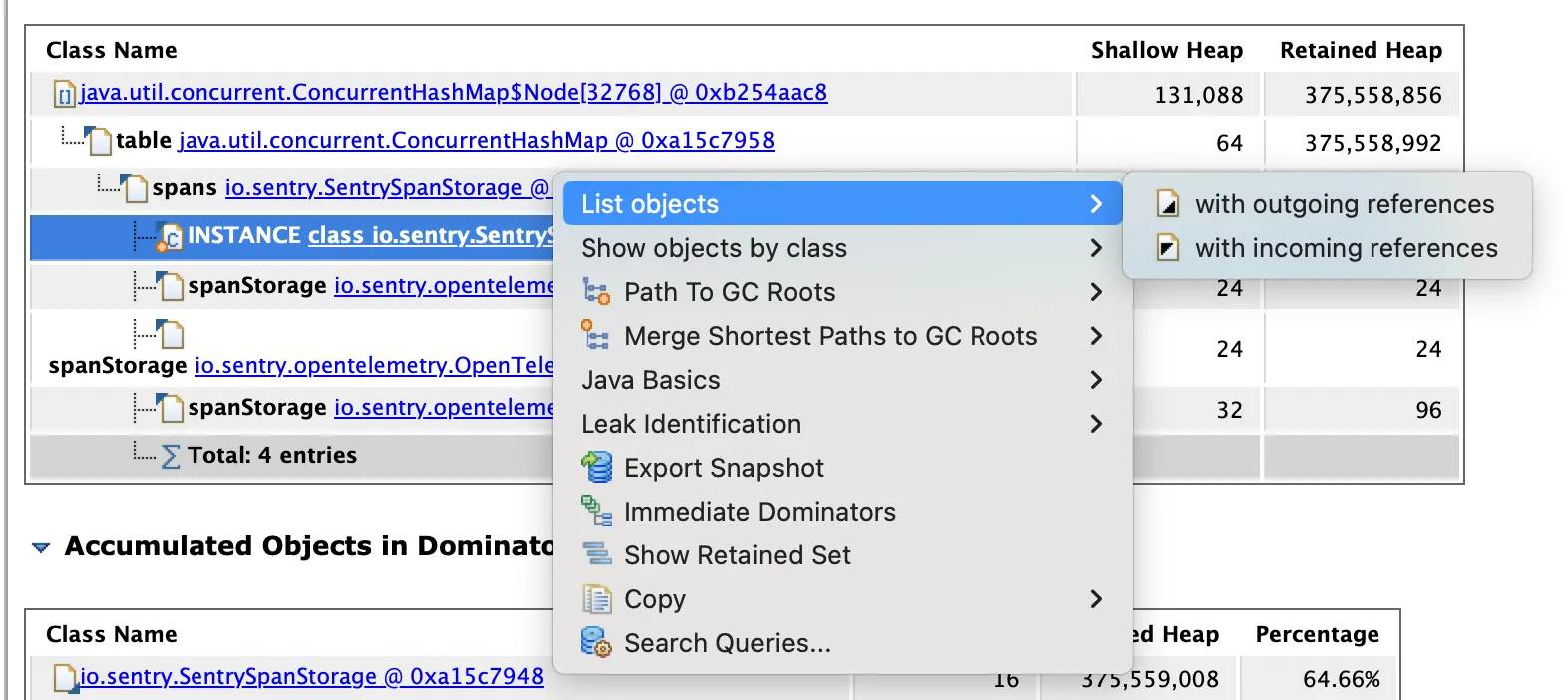
더 자세히 알기 위해 List objects 를 살펴보면 outgoing reference와 incoming reference로 어떠한 객체를 참조하는지 볼 수 있다.
Outgoing references, Incoming references 란 무엇인가?
쉬운 설명을 위해 아래와 같은 예시가 있다. 이 예시의 원문은 references를 확인하기 바란다.
public class A {
private C c1 = C.getInstance();
}
public class B {
private C c2 = C.getInstance();
}
public class C {
private static C myC = new C();
public static C getInstance() {
return myC;
}
private D d1 = new D();
private E e1 = new E();
}
public class D {
}
public class E {
}
public class SimpleExample {
public static void main (String argsp[]) throws Exception {
A a = new A();
B b = new B();
}
}
Java
복사
이러한 객체의 관계도는 아래와 같이 그려볼 수 있다.
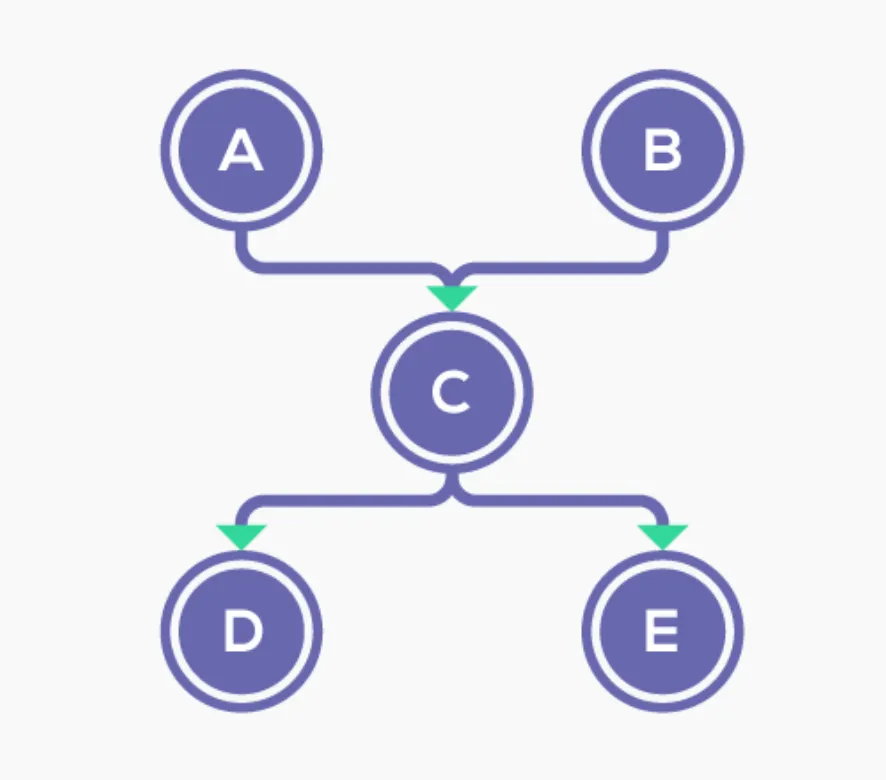
Sample 의 객체 관계도, https://dzone.com/articles/eclipse-mat-incoming-outgoing-references
Object A, Object B는 Object C를 참조하고 있다.
Object C 는 D, E object를 참조하고 있다.
Incoming References
Object C 를 참조하고 있는 모든 객체를 “incoming references” 라 한다.
이 예시에선 Object A, B 그리고 class C가 incoming references 가 된다.
즉, io.sentry.SentrySpanStorage 를 참조하는 객체가 무엇인지 알 수 있게 된다.

누가 io.sentry.SentrySpanStorage 를 참조하고 있는가??
MAT에서 list objects 로 incoming references 를 살펴보면 위와 같다.
정말 사실인지 살펴보기 위해 sentry github에서 코드를 확인해보자.

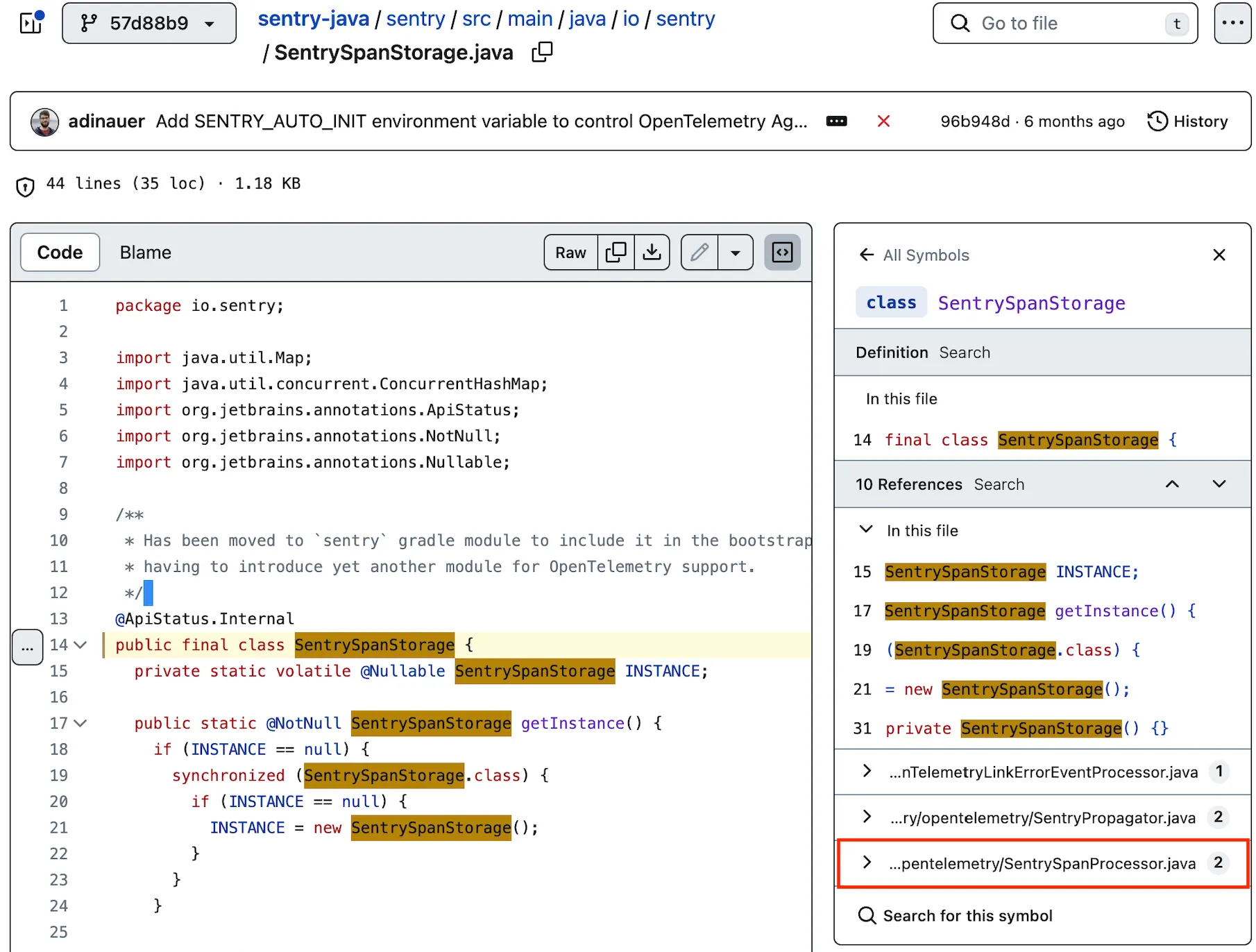
SentrySpanStorage 의 class
위 페이지의 references를 보면 SentrySpanProcessor 가 참조하고 있다고 명시하고 있다.

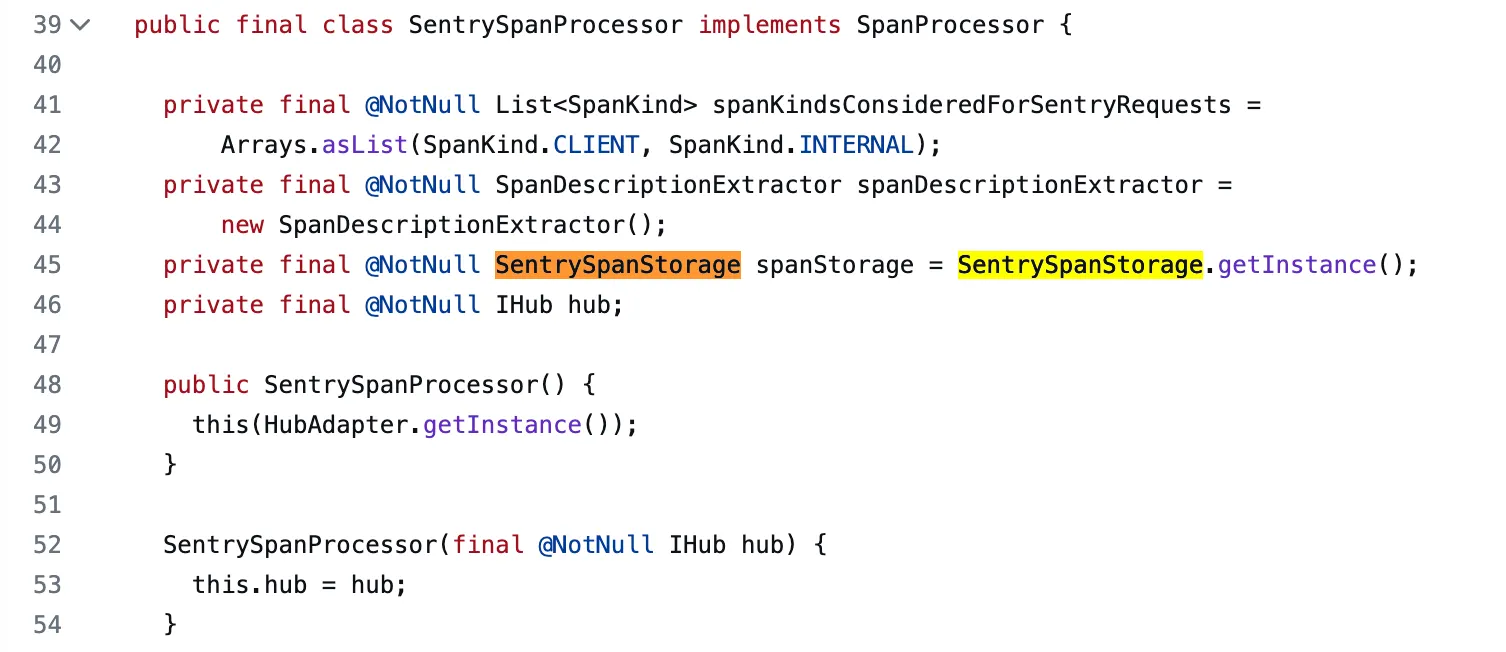
SentrySpanProcessor 의 클래스 파일
역시 github에서 확인해보면 SentrySpanStorage 를 참조하고 있다.
그렇다면 Sentry는 class loader에서 클래스를 띄우게 되면 SentrySpanProcessor 에서 어떠한 작업을 하기 위해 SentrySpanStorage 를 참조하고 있음을 확인할 수 있게 된다.
이것이 incoming references 이다.
Outgoing References
Incoming 과 반대로 C가 갖고있는 references를 의미한다. 위 예시에선 Object D, E 그리고 class C가 여기에 해당한다.
예시의 heap dump의 outgoing references를 확인해보면 io.sentry.SentrySpanStorage 가 어떤 instance를 참조하고 있는지 확인할 수 있다.

동일하게 SentrySpanStorage 를 살펴보면 ConcurrentHashMap 을 참조하고 있음을 확인할 수 있다.
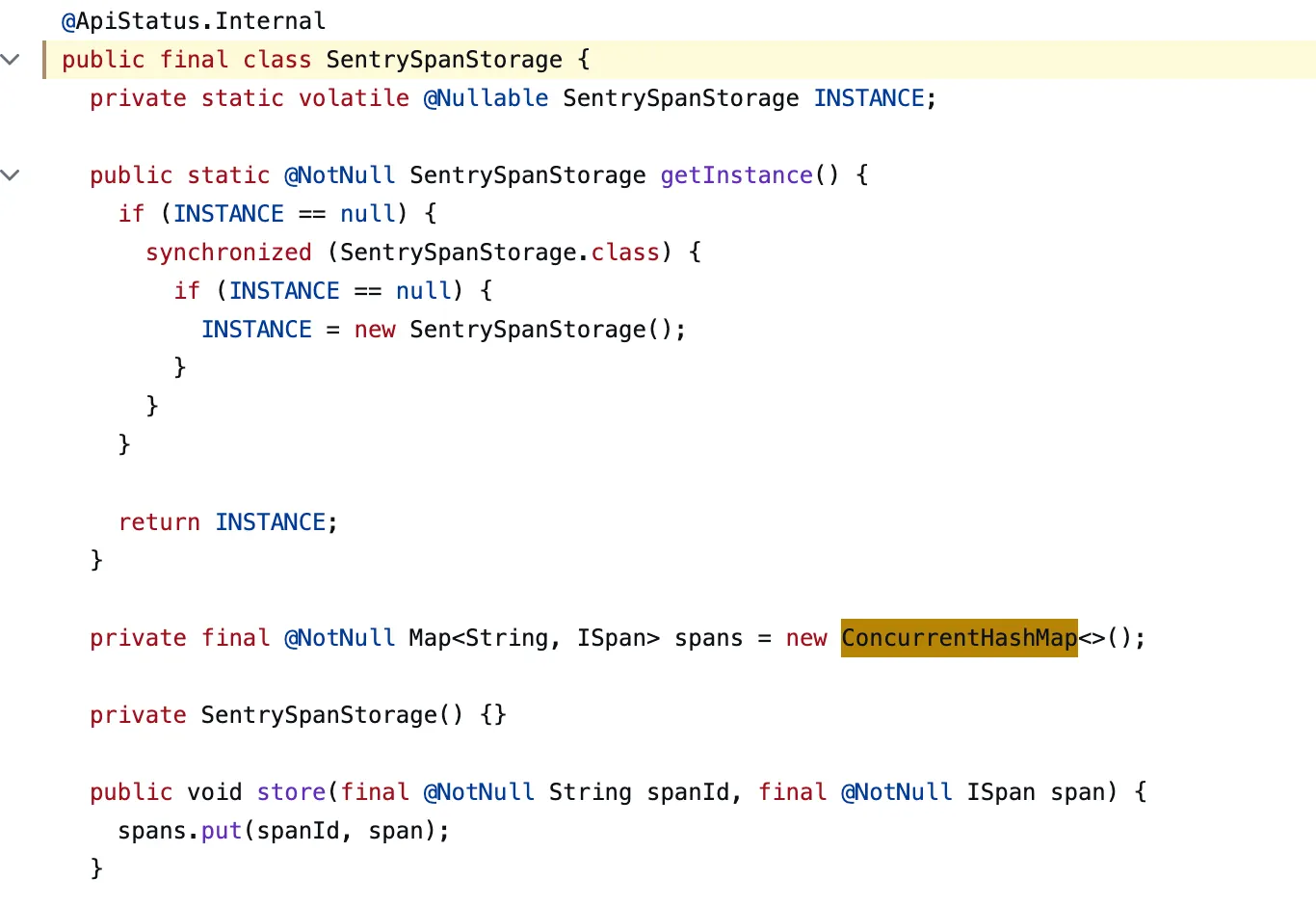
ISpan 이 나오지 않고 Node 가 나오는 이유는 Map에서 value해당하는 객체가 Node 이기 때문이다. 이 Node 객체에 ISpan 이 담기게 된다.
이에 대한 자세한 설명은 heap dump에 대한 주제에서 벗어나기 때문에 따로 다루도록 하겠다.
Retained Heap Size 란 무엇인가?
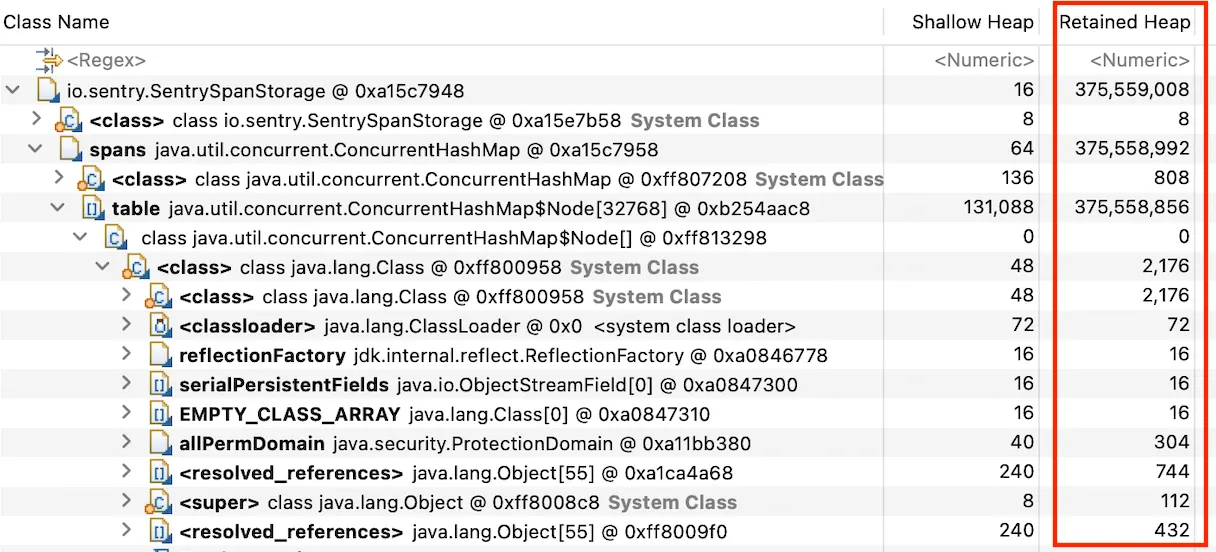
Retain에 의미는 간직하다, 남아있다 라는 뜻이다. 즉 heap 에 남아있는 size를 의미하는 것이다.
GC되어 삭제되지 않고 heap에 남아있는 객체의 size의 합이 된다.
위 report에서 확인할 수 있는 것은 ConcurrentHashMap 이 갖고있는 사이즈가 heap의 65%를 차지하고 있다는 사실이다.
이 사이즈는 GC가 실행될 때 free 되어야 한다.
해결 방안 추론하기
Out of memory Error의 root cause가 특정되었다. 그리고 어떠한 객체가 지속적으로 생성되는지 확인할 수 있었다. 그렇다면 이 객체를 어떻게 소멸되게 만들어야 할까??
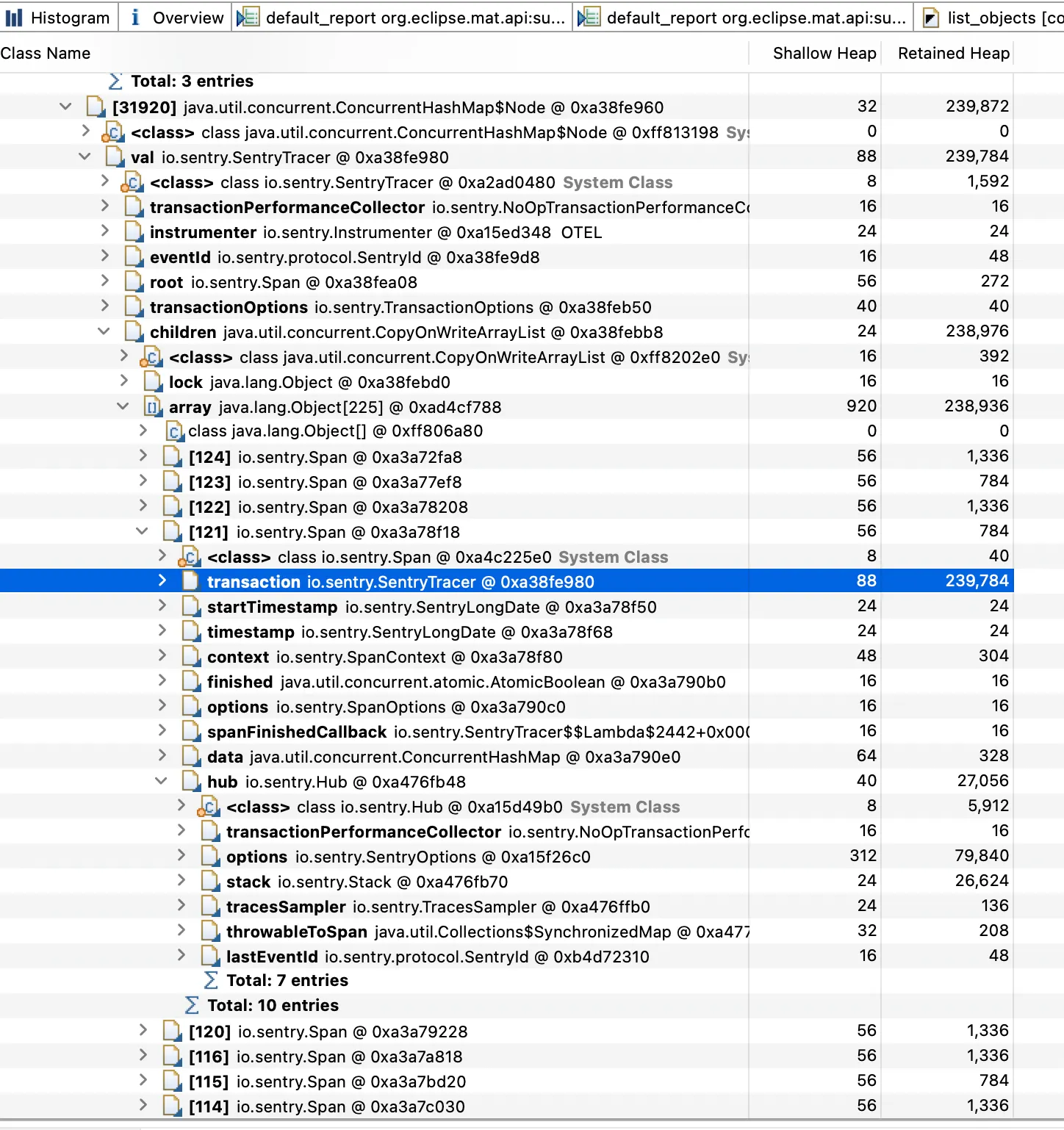
Map에 저장된 size가 큰 value를 살펴보면 sentry에서 모니터링 하는 이벤트 하나의 튜플로 추측할 수 있다.
더 추적해보면 transaction 이라는 필드에 많은 데이터를 갖고있으며 이 데이터를 변경하는 다루는 option을 변경하거나, sentry에 할당되는 thread를 설정하거나 서버의 증설 등을 각 상황에 맞게 고려할 수 있다.
결론
•
Heap dump 는 모니터링 툴과 로그를 통해서 원인을 특정하기 어려울 때 선택한다.
◦
단 Out Of Memory Error 인 경우 파악하는데 도움이 된다.
•
Leak report를 통해 원인이 되는 객체 집합을 특정한다.
•
Leak suspect가 2개 이상이라면 incoming, outgoing reference를 통해 더 자세하게 원인을 특정하자.
•
원인이 특정 되었다면, 관련 option을 찾아보거나 설정을 찾아 주어진 상황에 알맞게 반영하자.







