
데이터베이스 시스템을 읽다가 clustering index(clustered index)라는 단어가 나왔다. 예전에 읽었던 내용인데 자세하게 기억이 나지 않아서 정리해둘 필요가 있다고 생각했다.
먼저, Cluster 란 여러 개를 하나로 묶는 다는 의미로 사용한다.
특히 Index 에서는 값이 비슷한 것들을 묶어서 저장하려는 형태로 구현되는데, 주로 비슷한 값들을 동시에 조회하는 경우가 많다는 점에 착안하였다.
MySQL 에서는 InnoDB 엔진과 TokuDB 엔진에서만 지원하며, 나머지 storage engine 에서는 지원하지 않는다.
Clustering Index
Relation 에서 PK에만 적용되는 내용이다. InnoDB 에서는 row data 를 index에 저장하는 것을 의미한다.
Query(insert 를 포함한 여러 명령)에 대해 최고의 performance 를 얻기 위해 InnoDB 에서 clustered index를 어떻게 최적화 하는지 알아둘 필요가 있다.
•
Table 에 PK를 정의하면, InnoDB는 PK를 clustered index 로 사용한다.
◦
InnoDB의 경우 모든 테이블에 PK가 필요하다.
◦
만약 unique 에 non-null 필드가 없다면, auto_increment 가 clustered index 역할을 한다.
◦
auto_increment 는 row 가 추가되면, 자동적으로 생성된다.
•
InnoDB는 PK가 테이블에 없다면 unique 인덱스 중 not null 컬럼을 clustered index 로 정의한다.
•
만약 unique index 마저도 없다면, 숨겨진 clustered index 를 생성한다.
◦
이 경우 GEN_CLUST 라는 이름의 index 가 생성된다.
▪
이 index는 row ID value 를 포함하여 적절히 컬럼을 조합한다.
▪
Row 들이 InnoDB가 정의한 key 를 기준으로 정렬된다.
▪
Row ID는 6-byte로 row가 inserted 될 때마다 단조증가 한다.
◦
이 기준으로 물리적인 파일도 정렬된다.

Hidden index 경우는 명시적으로 사용할 수 없으며, 질의의 결과로 반환되지도 않는다.
Clustering index 는 InnoDB를 사용할 경우 상당한 이득이므로 되도록 PK를 사용하도록 하자
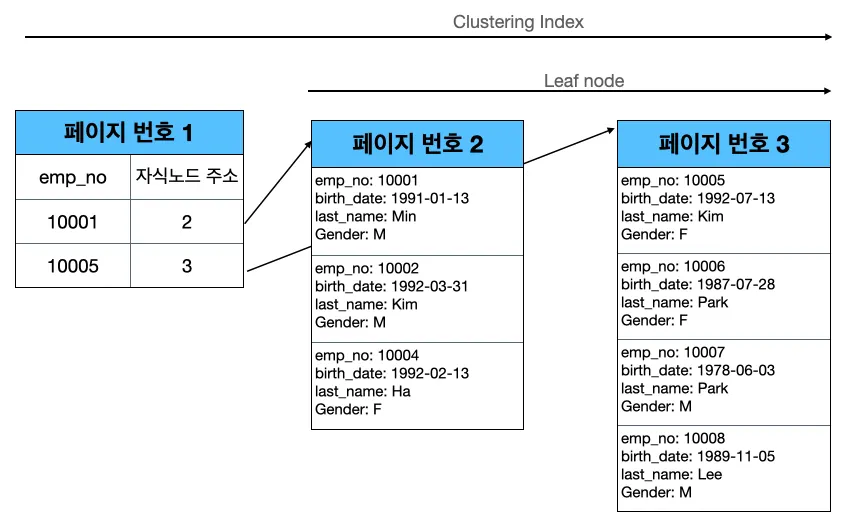
Clustering index Structure
이 index를 보면 인덱스 안에 row 데이터가 포함된 것을 볼 수 있다. 실제로 index 안에 모든 필드가 다 저장되어 있는 것이 특징이다.
즉, Clustering table 은 그 자체에 하나의 거대한 index 구조로 관리되는 것이다.
Clustering index 의 갱신
위 테이블에서 만약 10008번의 Lee 가 10003 번으로 PK가 변경되면 어떻게 될까? (물론 실제로 PK가 변경되는 일은 거의 없다.)
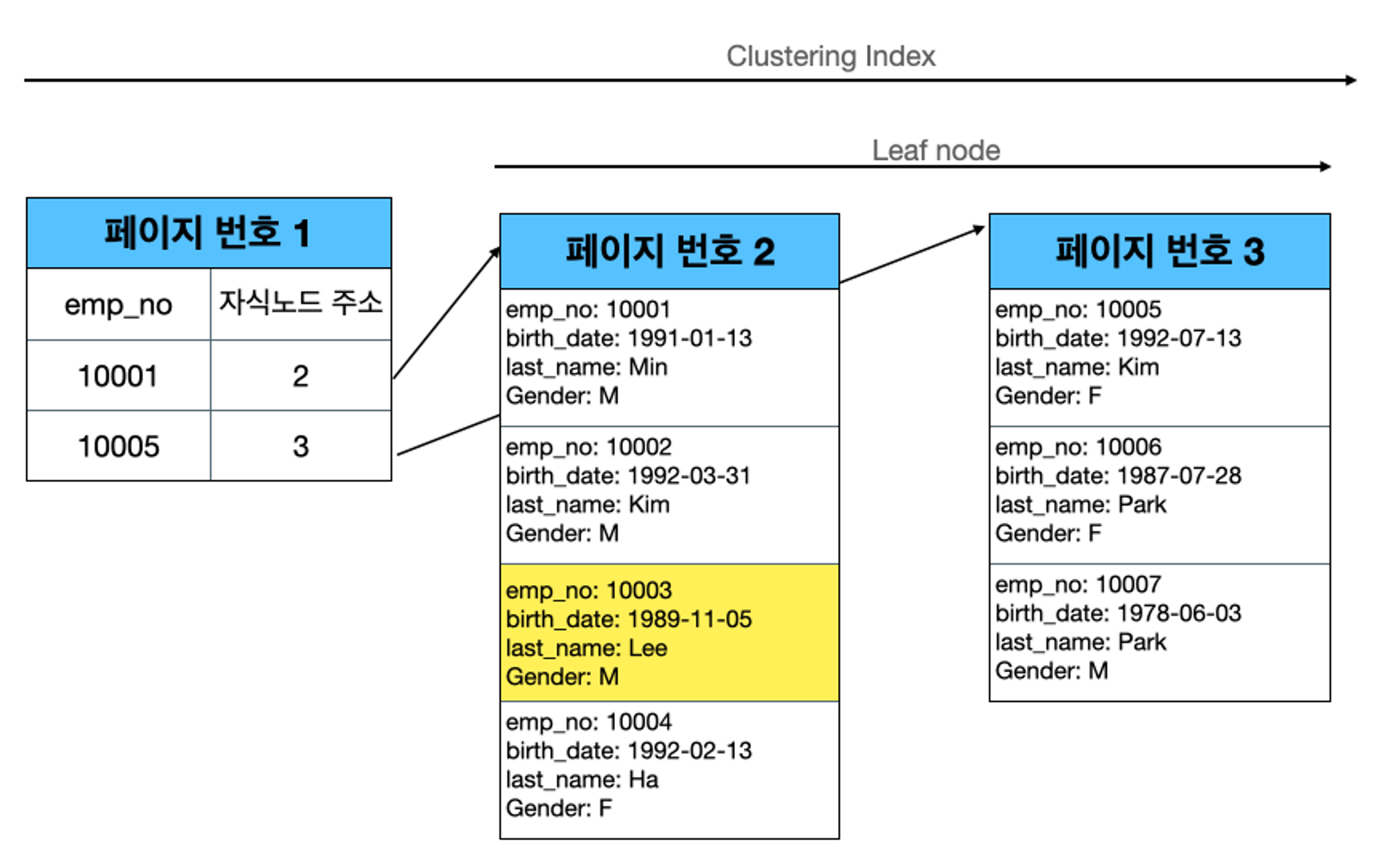
update employ set emp_no=10003 where emp_no = 10008 쿼리를 실행했을 때 결과
10008 row는 페이지 3번에 속해 있었지만, 페이지 2번으로 이동한다.
물론 한번 더 언급하지만, PK가 변경되는 일은 거의 없다. Cluster table의 작동 방식을 설명하기 위해 PK 값의 변경 과정을 살펴본 것이다.
어떻게 Clustered index가 query의 속도를 향상시킬까?
Clustered index를 통해 row 데이터에 접근하는 명령이 빠를 수 밖에 없는 이유는, row data 가 포함된 페이지로 index search 가 바로 연결되기 때문이다.
만약 table이 충분히 크다면, 다른 page를 사용하여 row data를 저장하는 storage 의 Disk I/O 작업을 저장하는 경우가 많다.
Clustered index와 secondary index의 연관성
그렇다면, cluster index가 아닌 다른 인덱스 흔히 말하는 보조 인덱스는 어떤일이 발생할까?
앞선 예제에서 PK가 변경되는 경우가 있다, 이러면 record의 주소값이 변경되는데 이 역시 비용이 큰 작업이다.
InnoDB는 이러한 문제에서 자유로워 지기 위해 보조 인덱스에 PK 값을 포함하여 사용한다.
그래서 만약 PK가 길다면, secondary index는 더 많은 공간을 차지하므로 PK가 짧은것이 성능과 보조 인덱스 측면에서 유용하다.
