
Handing Duplicate Records

Kinesis 문서에서 제공하는 내용으로 duplicate 가 발생하는 경우와 이를 해결하는 방법
Kinesis Stream 에서 중복이 발생하는 경우
Producer Retries
•
Producer 에서 PutRecord 를 호출할 때 network 와 관련하여 timeout 과 같은 이슈가 발생하는 경우
◦
ACK 을 받기 전에 timeout 으로 인해 produce 를 retry 하는 경우가 있다.
•
Kinesis Client Library(이하 KCL)는 application 에서 소비하는 모든 message 가 중요하다 간주하기 때문에 retry 를 사용하여 신뢰성을 갖춘다.
•
Kinesis Stream 은 동일한 메시지가 두번 PutRecord 를 호출하여 같은 메시지가 committed 되어도 둘 다 저장한다.
◦
두 data가 동일하더라도, 각각 unique sequence 를 갖는다.
•
따라서 Application이 엄격하게 이를 보장해야 하는 요구사항이 있다면, PK를 갖도록 설계해야 한다.

KCL PutRecord 는 default 로 retry를 3번 실행한다.
Consumer Retries
Consumer retry 는 보통 processor 가 restart 할 때 실행된다.
동일한 shard 에 대해서 record processor 가 restart 하는 경우는 다음과 같다.
1.
Worker 가 예상치 못하게 죽었다.
2.
Worker instance 가 추가되거나 제거된다.
3.
Shard 가 병합되거나 분리된다.
4.
Application 이 배포된다.
이러한 경우가 있을때 shards-to-worker-to-record-processor 는 계속해서 load balancing 을 위한 작업을 별도로 수행하게 된다.
만약 다른 instance 로 migration 된다면 application의 worker 는 마지막 check point 부터 다시 시작한다.
Example: Consumer Retries Resulting in Redelivered records
Consumer 에서 retry 수행을 위한 예제를 위해 다음과 같은 application 을 예시로 들어본다.
•
Application은 stream 에서 계속해서 records 를 읽고 집계하여 파일로 만들고, S3에 업로드한다.
•
Shard 1개와 1 worker 가 shard를 processing 한다.
•
현재 check point 는 10000 이다.
다음의 순서로 실행되고 있다.
1.
Worker 가 shard의 다음 record에 해당하는 10001 ~ 20000 을 읽어들인다.
2.
Worker 는 1번에 해당하는 records 를 일괄처리 한다.
3.
Record prcoessor 가 데이터를 집계하고, AWS S3에 성공적으로 업로드한다.
4.
Checkpoint 를 호출하기 전에 worker 가 terminated 된다.
5.
Application, worker, record processor 가 재시작한다.
6.
Worker 는 이제 10001 부터 다시 읽기 시작한다.
따라서, 10001 ~ 20000에 해당하는 record는 1번 이상 다시 consumed 된다.
Consumer 가 중복으로 부터 자유롭게 재시도하려면
Consumer 를 개발하는 입장에서 1번 이상 동일한 record가 consume 된다 하더라도 정확하게 1번만 processing 되길 원하게 된다.(멱등성)
이는 매우 어렵고 정밀한 작업이 된다.
앞선 예제에서 stream을 통해 지속적으로 record 를 읽어 file로 만들고 Amazon S3에 업로드 한다.
100001~20000 records는 동일한 데이터가 1번 이상 S3로 업로드될 수 있다.
이 중복을 완화하기 위해서 다음의 3가지 step 을 따를 필요가 있다.
1.
Record processor 는 S3 에 업로드하는 파일에 대해 고정된 record 수를 사용한다.
•
예를 들면, 파일 하나에는 record 5000개만 하나의 파일로 생성한다.
2.
S3 에 업로드 하는 file 의 이름을 [S3 prefix]-[shard id]-[sequence] 로 생성한다.
•
이 케이스에선 sample-shard000001-100001 이 된다.
3.
S3에 file을 upload 하면, check point 를 마지막에 호출한다. → 15000(파일 하나에 5000 record씩 생성하므로)
이러한 설계라면 동일한 데이터를 1번 이상 processing 되더라도 결과는 오로지 하나만 나오게 된다.
적용 사례
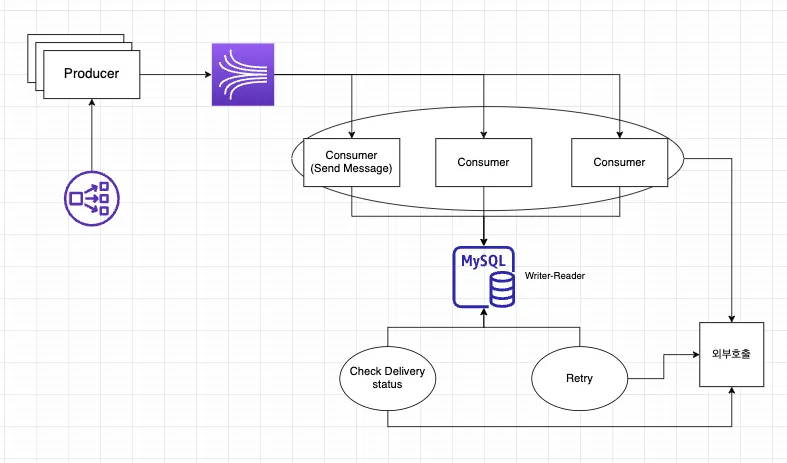
이와 같은 structure 가 있을 때 Consumer 는 메시지를 전송할 때 동일한 메시지가 2번 이상 사용자에게 전달될 수 있다. 그래서 전송 전에 DB에 unique id 는 질의하여 존재하는지 여부를 확인하였다.
그렇다면 전송하는 측에서 Unique ID 를 정의해서 보내줘야 한다.
물론 이와 별개로 Primary Key가 따로 존재한다.
또한, Unique ID가 존재하는지 확인하는 시간 부터 메시지를 저장하는 시간 이 시간 사이인 사이에 다른 consumer 가 또 메시지가 존재하는지 확인하는 작업이 발생할 수 있다.
이를 대비하기 위해 MySQL의 insert ignore into 를 사용하였다.
