
Springboot 와 Google Cloud 의 BigQuery를 연동하여 API를 개발해야 한다. 빅데이터팀이 정의한 multi-result 를 반환하는 Stored proecdure를 spring boot 와 연결해본다.
이와 관련된 글을 찾기가 어려워서 직접 trouble shooting 을 완료하고 다른 개발자들이 내가 소비한 시간을 동일하게 소비하지 않기를 바란다.
개요
상황
•
지표 API를 개발하게 되었다. 데이터는 BigQuery 에 존재한다.
•
직접 쿼리를 실행하자니 big query의 쿼리를 직접 BE팀에서 실행하는데는 시간이 부족하다.
•
한번의 stored procedure 를 호출하여 여러개의 결과를 반환하는 stored procedure 를 제공받는다.
•
이 Stored procedure를 Spring application 에서 호출한다.
•
Kotlin, Spring boot 를 사용한다.
선택권
1.
Google cloud 의 client 를 사용한다. 링크
2.
Spring boot starter 에 있는 cloud integration 을 사용한다.
결정한 부분
결론부터 말하자면 설정을 편리하게 하기 위해 spring boot starter 패키지를 사용했다. 설정 자체는 별거 아니지만 이왕 spring boot 를 사용하는데 이 편이 더 편리하겠다고 생각했다.
사전작업
API를 사용하도록 big query 의 Enable API 설정을 on 해야한다.
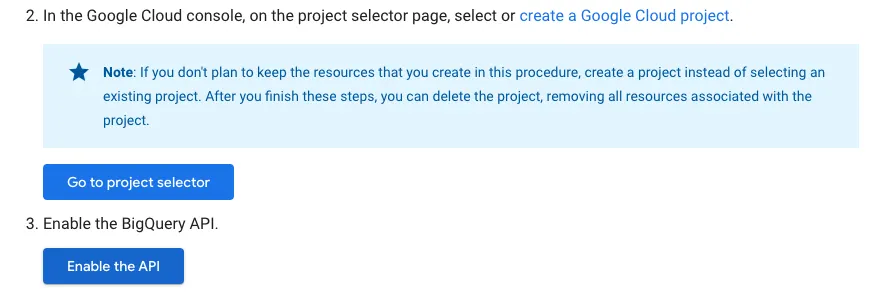
이후 부분은 위 문서에 잘 나와있으니 service account 생성과 관련된 것은 위 문서를 참고하고, service key를 준비 해둔다.
Gradle 에 추가할 문장
extra["springCloudGcpVersion"] = "3.4.0"
extra["springCloudVersion"] = "2021.0.5"
implementation("com.google.cloud:spring-cloud-gcp-starter")
implementation("com.google.cloud:spring-cloud-gcp-starter-bigquery")
dependencyManagement {
imports {
mavenBom("com.google.cloud:spring-cloud-gcp-dependencies:${property("springCloudGcpVersion")}")
mavenBom("org.springframework.cloud:spring-cloud-dependencies:${property("springCloudVersion")}")
}
}
Kotlin
복사
Gradle 에 위와 같이 추가하여 Big Query를 사용할 수 있도록 설정한다.
이와 같은 설정을 해두면 Spring boot 의 auto configuration 을 사용할 수 있다.
Properties 에 추가할 내용
위 문서에 포함된 Configuration 을 application.properties 혹은 application.yml 에 추가한다.
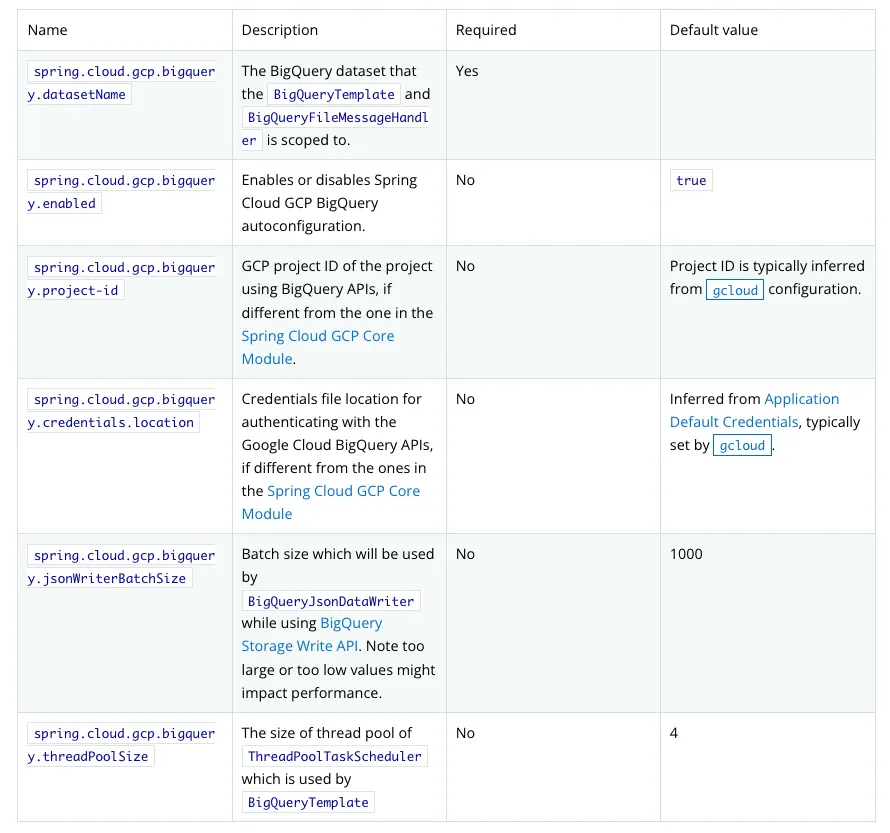
•
spring.cloud.gcp.bigquery.datasetName
◦
BigQuery의 dataset 과 BigQueryTemplate, BigQueryFileMessageHandler 의 scope 범위에 해당할 dataset 이름을 할당한다.
◦
반드시 필요한 값이며 default 는 없다.
•
spring.cloud.gcp.bigquery.enabled
◦
Auto configuration 을 사용할지 말지를 결정한다.
◦
별도로 기입하지 않는다면 활성화된다.
•
spring.cloud.gcp.bigquery.credentials.location
◦
Credential file 의 위치를 명시할 곳이다.
◦
이 글에서는 사용하지 않는다. base64 로 인코딩 하여 하단의 field 에 할당할 것이다.
◦
Github secret 을 사용하여 pod 로 배포할 것을 고려하면 mount 등을 하기 귀찮다고 생각했다.
•
spring.cloud.gcp.bigquery.jsonWriterBatchSize
◦
BigQueryJosnDataWriter 를 통해 데이터를 저장하는 API를 호출할 때 사용할 batch size 이다.
◦
내 요구사항에선 읽기, select 호출만 필요하기 때문에 따로 사용하지 않는다.
•
spring.cloud.gcp.bigquery.threadPoolSize
◦
BigQueryTemplate 을 사용할 때 thread pool 의 크기를 명시한다.
◦
Default는 4이고, required 가 아니다.
◦
내 요구사항에선 BigQueryTemplate 이 필요하지 않을것으로 예상된다.
Configuration
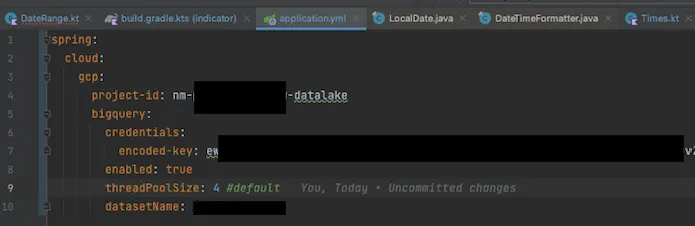
이와같이 사용할 수 있다.
Key file 을 base64로 encoding 하기
cat /path/to/key/file | base64
Shell
복사
Key file 을 base64로 인코딩한다.
만약 file 을 사용한다면 필요하지 않은 작업이다.
우리의 환경은 K8S 로 배포하고 docker file 을 직접 빌드해서 AWS ECR 에 올려야 하는데 이 과정보단 github flow 를 통해서 Docker file 빌드시에 주입하는것이 편리하다고 생각했다.
이제 select 만 한다면 모든 설정은 완료되었다.
Select Query 혹은 stored procedure 호출하기
fun executeCall(query: String) {
val queryConfig = QueryJobConfiguration
.newBuilder(query)
.build()
val tableResult = bigQuery.query(queryConfig)
for (row in tableResult.iterateAll()) {
println("---------------start-----------------")
for (value in row) {
println(value)
}
}
}
Kotlin
복사
간단한 select Query 를 호출하는 함수
query 에 select 쿼리를 입력하면 BigQuery 로 쿼리문을 전송하여 결과를 받아온다.
ResultSet 의 결과는 tableResult 로 들어오게 된다.
그 결과 안엔 field 가 하나하나 있는데 이를 Entity 로 쉽게 매핑하는 방법은 아직 찾기 못했다.
Multi-result set
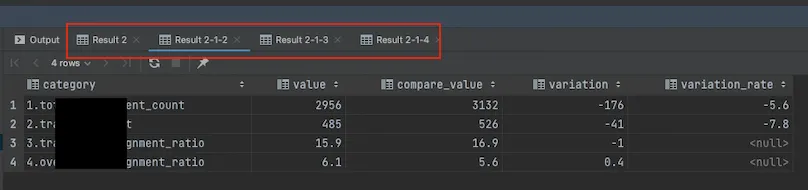
Result 가 여러개이다. 이건 2번째 결과이다.
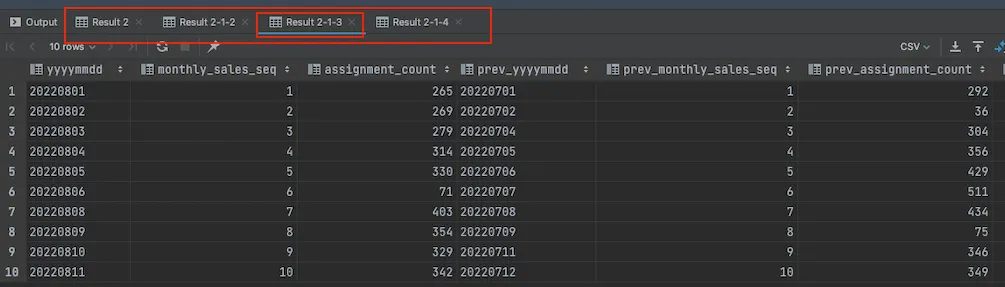
이 결과는 3번째 결과이다.
이 Stored precedure 는 4개의 결과 집합을 반환한다.
문제는 위의 함수로는 가장 마지막 결과만 확인할 수 있다. 그래서 1, 2, 3번째의 결과를 JobId 를 통해 찾을 필요가 있다.
그래서 JobId 를 개발자가 직접 관리(만들어야)해야 한다.
나중에 Key generator 를 사용하겠지만, 현재는 간단하게 UUID를 사용하여 JobId 를 만들어 다음과 같이 사용한다.
@Service
class CallProcedure(
private val bigQuery: BigQuery,
) {
fun executeCall(query: String) {
val queryConfig = QueryJobConfiguration
.newBuilder(query)
.setUseLegacySql(false) // 이 설정이 stored procedure 를 호출하게 만든다
.build()
val jobId = JobId.of(UUID.randomUUID().toString()).also {
bigQuery.query(queryConfig, it)
}
// multi-result
val children = bigQuery.listJobs(JobListOption.parentJobId(jobId.job))
for (child in children.iterateAll()) {
println("----------??----------")
println(child.getQueryResults())
}
}
}
Kotlin
복사
Job ID 를 만들고, job id로 각각의 결과 집합을 찾는다.
결과 집합은 parentJobId 를 통해서 찾아온다.
children 은 결과집합이 여러개일 경우 iterateAll 함수를 통해 가져올 수 있다.
결과
•
기존의 spring application 은 JPA repository 를 많이 사용했다.
◦
이와 비슷한 컨셉으로 repository 를 정의할 예정이다.
◦
이를 통해서 Entity 를 만들고 결과 속성값을 할당하려고 한다.
•
자동으로 생성되는 BigQuery 를 DI로 주입받으면 바로 select 를 할 수 있다.
@SpringBootTest
internal class BigqueryStatisticsRepositoryTest {
@Autowired
private lateinit var bigquery: BigQuery
@Test
fun `call procedure`() {
executeCall("""
CALL dataset.procedure(param1, param2, ...)
""".trimIndent())
}
}
Kotlin
복사
위와 같이 코드를 작성하여 결과를 확인할 수 있다.
println() 로 나온 결과를 찍거나, break point 를 통해서 주어진 상황에 알맞게 결과를 deserialize 하면 요구사항을 충분히 충족할 수 있을 것이다.
참조한 문서
이 외에 write operation 의 경우는 모두 spring cloud big query 의 문서를 통해 확인할 수 있다.
참조한 문서들은 다음과 같다.




샘플코드
이와 관련된 기능을 찾다보면 archive 된 github repo도 존재한다.
주의해야 할 것은 이 버전은 오래된 것이기 때문에 현재 사용할 이유가 없다.
