이 포스팅은 Real MySQL 트랜잭션 chapter 를 읽고 작성한 부분입니다. 저는 MySQL, MongoDB, 현재는 Elastic Search 까지 회사에서 필요한 요구사항에 맞춰 개발중입니다. 그런데 4년이나 사용한 MySQL 내부에 대해 정확히 모른다는게 말이 안되는거 같아 이 책을 읽게 되었습니다.
MySQL 을 현업에서 활발히 사용하는 개발자라면 이 책을 꼭 강추합니다 꼭 구매해서 읽어보세요!

트랜잭션
작업의 완전성을 보장해주는 것이다.
논리적인 작업셋을 모두 완벽하게 처리하거나 처리하지 못할 경우 원 상태로 복구(roll back)을 해서 일부분만 업데이트(partial update) 되는 현상을 예방해야 한다.
트랜잭션을 지원하지 않는 MyISAM 과 트랜잭션을 지원하는 InnoDB 처리 방식의 차이를 살펴본다.
MySQL 에서의 트랜잭션
txn 정의: 트랜잭션은 반드시 여러개의 query 가 있을 때만 의미있는 것이 아니다. 하나의 논리적인 작업에 논리적인 작업 set 자체가 100% 적용되거나 (commit을 실행했을 때) 또는 아무것도 적용되지 않아야 함을(Rollback 또는 트랜잭션을 Rollback 시키는 오류가 발생했을 때) 보장해주는 것이다.
# myisam
create table tab_myisam (
fdpk int not null,
primary key (fdpk)
) engine = MyISAM;
insert into tab_myisam (fdpk) values (3);
SQL
복사
create table tab_innodb (
fdpk int not null,
primary key (fdpk)
) engine = INNODB;
insert into tab_innodb (fdpk) values (3);
SQL
복사
위와 같이 테이블을 만들고 pk가 3인 데이터를 먼저 insert 한다.
insert int tab_myisam (fdpk) values (1), (2), (3);
insert int tab_innodb (fdpk) values (1), (2), (3);
SQL
복사
•
duplicate key 에러가 둘다 발생하지만 결과는 다르다
•
myisam 의 경우는 1, 2, 3 이 저장되어 있고, innodb는 3만 저장되어 있다.
•
myisam 과 같은 이슈를 partial update 라 하여 테이블 데이터의 정합성을 맞추는데 상당히 어려운 문제를 만들어 낸다.
•
transaction 은 애플리케이션 개발에서 고민할 문제를 줄여주는 필수적인 DBMS 의 기능이다.
주의 사항
transaction 은 꼭 필요한 상황에만 좁게 사용하는 것이 좋다. 즉, transaction 의 범위를 최소화 해야 한다.
다음의 게시글 작성 로직을 통해 이 의미를 설명한다
1.
처리 시작
→ DB connection 생성
→ transaction start
2.
사용자의 로그인 여부 확인
3.
사용자의 글쓰기 내용의 오류 여부 확인
4.
첨부로 업로드된 파일 확인 및 저장
5.
사용자의 입력 내용을 DBMS 에 저장
6.
첨부 file 정보를 DBMS에 저장
7.
저장된 내용 또는 기타 정보를 DBMS 에서 조회
8.
게시물 등록에 대한 알림 메일 발송
9.
알림 메일 발송 이력을 DBMS 에 저장
← transaction commit
← DB connection close
10.
처리 완료
•
DBMS 에 저장하는 작업은 5, 6번 에서 실행된다.
→ 2, 3, 4번의 절차가 더 빨리 진행된다 하더라도 DBMS transaction 에 포함 시킬 필요는 없다.
•
DB transaction 의 connection 개수가 제한적이다.
◦
connection 소유 시간이 길어지면 여유 connection 개수가 줄어들어 대기 상황이 발생한다.
•
8번과 같이 network 통신 작업은 transaction 안에 포함해선 안된다.
•
메일 서버와 통신할 수 없는 상황이 발생한다면 웹 서버뿐 아니라 DBMS 서버까지 위험해 질 수 있다.
•
5, 6번은 하나의 transaction 으로 묶어야 하지만, 7번과 같이 단순 조회는 transaction 에 묶을 필요 없다.
•
9번은 5, 6번과 다른 로직이기 때문에 굳이 하나로 묶을 필요는 없다.
◦
이러한 작업이 있어서 Spring AOP 가 나온게 아닐까?
이러한 이유로 다음과 같이 처리 로직을 변경한다
1.
처리 시작
2.
사용자의 로그인 여부 확인
3.
사용자의 글쓰기 내용의 오류 발생 여부 확인
4.
첨부로 업로드된 파일 확인 및 저장
→ DB connection 생성
→ transaction start
5.
사용자의 입력 내용을 DBMS 에 저장
6.
첨부 파일 정보를 DBMS 에 저장
← transaction commit (종료)
7.
저장된 내용 또는 기타 정보를 DBMS 에서 조회
8.
게시물 등록에 대한 알림 메일 발송
→ transaction start
9.
알림 메일 발송 이력을 DBMS에 저장
← transaction commit
← DB connection close
10.
처리 완료
프로그램 코드가 DB connection을 가지고 있는 범위와 transaction 이 활성화돼 있는 범위를 최소화 한다.
Network 작업이 포함 되어 있다면 반드시 transaction 에서 분리되어야 한다.
MySQL 엔진의 잠금
용어 설명
•
storage engine level: InnoDB, MyISAM, mGroonga
•
MySQL engine level: storage 엔진을 제외한 나머지 부분
mysql engine level 은 storage engine 까지 영향을 준다. 반대는 영향을 미치지 않는다.
Global Lock
•
global lock 은 Flush tables with read lock 명령으로 획득한다.
◦
범위는 전체이다. 작업 대상 테이블, Db가 다르더라도 동일하게 영향을 미친다.
•
MySQL 에서 제공하는 Lock 중에 가장 범위가 크다.
•
select 를 제외한 DDL, DML 은 global lock 이 종료될 때 까지 대기상태이다.
•
read lock 이후 global lock 이 걸리면 마지막 select 가 종료 되고 global lock 이 시작된다.
◦
read lock 이 오래걸린다면 최악의 경우가 될 수 있다.
•
가급적 서비스용 DB 에서는 사용하지 않는 것이 좋다.
Table Lock(InnoDB 에서는 사용하지 않는다)
•
명시적, 묵시적으로 table lock 을 획득할 수 있다.
◦
명시적 Lock 은 온라인에 상당한 영향을 미치므로 application 에서 거의 사용하지 않는다.
•
LOCK TABLES table_name [READ|WRITE] 명령으로 lock 을 획득한다.
•
Unlock tables 명령으로 잠금을 반납할 수 있다.
•
MyISAM, InnoDB engine 을 사용하는 table 도 동일하게 설정할 수 있다.
•
MyISAM 이나 Memory 테이블은 data 를 변경하는 쿼리를 실행하면 발생한다. (묵시적 lock)
◦
쿼리가 실행되는 동안 자동으로 획득하고, 종료되면 자동으로 반납한다.
•
InnoDB table 은 storage engine 차원에서 record 기반의 잠금을 제공하기 때문에 단순 data 변경 query 로 인해 묵시적인 table lock 이 설정되지 않는다.
◦
DML 은 무시되고, DDL 인 경우에 lock 인 경우 영향을 미친다.
User Lock
•
GET_LOCK() 함수를 이용해 임의로 잠금을 설정할 수 있다.
•
이 잠금의 대상은 테이블이나 record 또는 auto_increment 같은 DB 객체가 아니다.
•
하나의 DB가 5대 웹 서버에 서비스를 할때 여러 client 가 상호 동기화를 처리할 때 유용하다.
•
한꺼번에 많은 record 를 변경해야 하는 상황(batch program)에 dead lock 경험시
◦
동일 데이터를 변경하거나 참조하는 프로그램 끼리 분류하여 user lock 을 실행하면 dead lock 해결책이 되곤 한다.
# mylock 이라는 문자열에 대해 잠금을 획득한다
# 이미 잠금이 사용 중이면 2초 동안만 대기한다.
select get_lock('mylock', 2);
# "mylock" 이라는 문자열에 대해 잠금이 설정돼 있는지 확인한다.
select is_free_lock('mylock');
# "mylock" 이라는 문자열에 대해 획득했던 잠금을 반납한다
select release_lock('mylock');
SQL
복사
Name Lock
테이블, view 등에 이름을 변경할 때 사용하는 lock 이다.
실시간으로 테이블을 바꿔야 하는 경우 다음과 같이 사용할 수 있다.
rename table rank to rank_backup, rank_new to rank;
SQL
복사
위에서 보면 두 테이블의 이름을 변경하는 작업이다. 위 쿼리의 장점은 잠시동안 Table not found 'rank' 같은 에러를 경험하지 않는다
rename table rank to rank_backup;
rename table rank_new to rank;
SQL
복사
위와 같이 따로 변경하면 잠시동안 Table not found 'rank' 에러를 경험할 수 있다.
MyISAM 과 Memory 스토리지 엔진의 잠금
myisam 과 memory 엔진의 경우 자체적인 잠금을 가지지 않고 MySQL 엔진에서 제공하는 table lock 을 그대로 사용한다.
query 단위로 필요한 잠금을 한꺼번에 모두 요청해서 획득하기 때문에 dead lock 이 발생할 수 없다.
잠금 획득
•
읽기 잠금
◦
table 에 read lock 이 없으면, 바로 잠금을 획득하고 읽기 작업 실행
•
쓰기 잠금
◦
table 에 아무런 잠금이 없어야만 쓰기 잠금을 획득할 수 있다.
◦
그렇지 않다면 다른 잠금이 해제될 때까지 대기한다.
잠금 튜닝
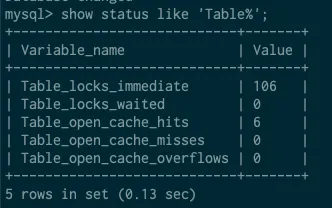
show status like 'Table%';
SQL
복사
•
Table_locks_immediate 은 잠금이 풀리기를 대기하지 않고 바로 잠금을 획득한 횟수
•
Table_locks_waited 는 이미 잠금중이기 때문에 대기해야 했던 횟수
위 횟수를 누적하여 저장한다.
잠금 대기 쿼리 비율 = Table_locks_waited / (Table_locks_immediate + Table_locks_waited) * 100
SQL
복사
위 비율이 높다면 성능을 위해 lock 에 대한 튜닝이 필요하다 판단할 수 있다.
단, InnoDB 엔진의 경우 record 단위 잠금을 사용하기 때문에 위 수치에 반영되지 않는다.
테이블 수준의 잠금 확인 및 해제
•
MyISAM 이나 Memory 같은 엔진은 테이블 단위의 잠금이다.
•
table 을 해제하지 않으면 다른 client 에서 그 table을 사용하는 것이 불가능하다.
•
MySQL 에서 잠금을 획득하는 방법
◦
Lock Tables 명령을 이용해 명시적으로 획득하는 방법
▪
Unlock Table 명령으로 해제하기 전에 자동으로 해제되지 않는다.
◦
DML(select, insert, delete, update ) 쿼리 문장을 이용해 묵시적으로 획득
잠금 상태 확인
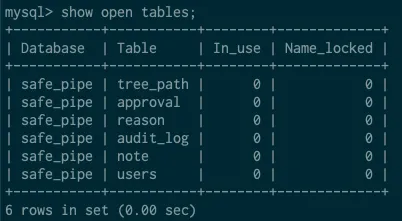
show open tables from 테이블 명;
show open tables from 테이블 명 like 조건;
SQL
복사
In_use = (컬럼은 잠그고 있는 client 수) + (잠금을 기다리는 client 수) 이다.
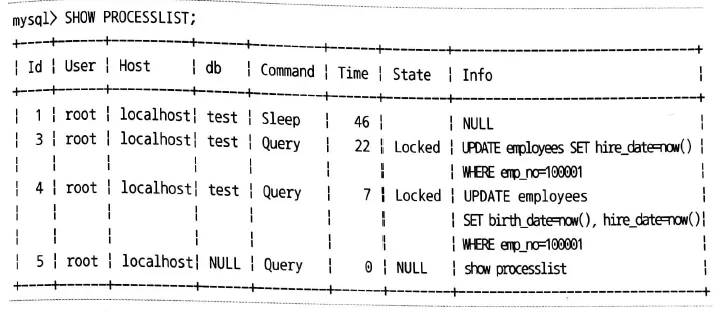
show processlist;
SQL
복사
어떤 client 의 connection 잠금을 디가리고 있는지 보여준다.
1.
id 가 3, 4번이 Locked 인데 이는 Lock 이 종료 대기 이다.
2.
3, 4번이 동일하게 employees 인걸로 보아 lock 을 획득한 것이 아니다.
3.
1번이 아무것도 하고 있지 않은것으로 보아 lock 을가지고 있으며, lock 을 반납하면 3, 4번의 쿼리가 실행될 것이다.
client 를 종료 시키는 방법은
kill query client_아이디;
SQL
복사
InnoDB 스토리지 엔진의 잠금
•
record 기반 잠금
•
잠금 정보가 매우 작은 공간으로 관리 되기 때문에 page lock, table lock 으로 레벨업 되는 경우는 없다.
•
record 와 record 사이의 간격을 잠그는 gap 락도 존재한다.
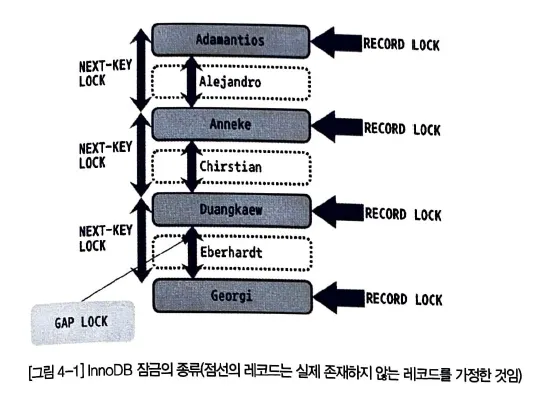
Record Lock, Record only Lock
•
record 자체만 잠그는 lock이다.
•
다른 상용 DBMS 와 동일한 역할을 하지만, 차이점으로는 index 의 record 를 잠근다.
•
만약 index 가 하나도 없는 table 이라 하더라도 내부적으로 자동 생서된 cluster index 를 사용해 잠근다
◦
다음에 이와 간련된 예제로 자세한 설명을 한다
•
보조 index 를 사용한 잠금은 Next Key lock 혹은 Gap lock 을 이용한다.
•
primary key, unique key index 에 의한 변경 작업은 Gap 에 대해서는 잠그지 않고 record 자체에만 lock 을 건다.
Gap lock

개념일 뿐이지 자체적으로 사용되지 않는다, Next key 의 일부로 사용된다.
•
record 와 record 사이에 새로운 record 가 insert 되는 것을 막는 역할을 수행한다.
•
다른 DBMS 에는 없다.
•
record 와 바로 인접한 record 사이의 간격만을 잠그는 것을 의미한다.
Next key lock
•
binary log 에 기록되는 query 가 slave 에서 실핼될 때 master 에서 만들어낸 결과와 동일한 결과를 만들도록 보장한다
•
next key 와 gap lock 으로 인해 dead lock 이 자주 발생된다.
◦
binary log 포맷을 row 형태로 바꿔서 next key lock 이나, gap lock 을 줄이는 것이 좋다.
◦
하지만 row format 의 안정성은 아직 확인이 어렵다.
Auto increment lock
•
동시에 여러 record 가 insert 되는 경우, 저장되는 각 record 는 중복되지 않고, 저장된 순서대로 일련번호를 갖도록 한다.
•
새로운 record 를 저장할 때만 필요하다.
•
insert, replace 에서 사용된다.
•
위 두 query 가 실행될 때 잠시 AUTO_INCREMENT lock 이 걸렸다가 즉시 해제된다.
•
명시적으로 획득하고 해제하는 방법은 없다. 매우 잠시 걸리기 때문에 대부분의 경우 문제가 되지 않는다
인덱스와 잠금
앞서 언급했듯, index 를 잠그는 것은 InnoDB 의 특징이며 따로 알아두어야 한다.
index lock 은 변경해야 할 record 를 찾기 위해 검색한 index record 를 모두 잠가야 한다.
key ix_firstname (first_name); # first_name 이 index 이다.
select count(*) from employees where first_name = 'Georgi';
-> 253
select count(*) from employees where first_name = 'Gerogi' and last_name = 'Klassen';
-> 1
SQL
복사
위와 같은 상황일 때
update employees set hire_date = now()
where first_name = 'Gerogi' and last_name = 'Klassen';
SQL
복사
는 lock 의 범위가 253개가 된다.
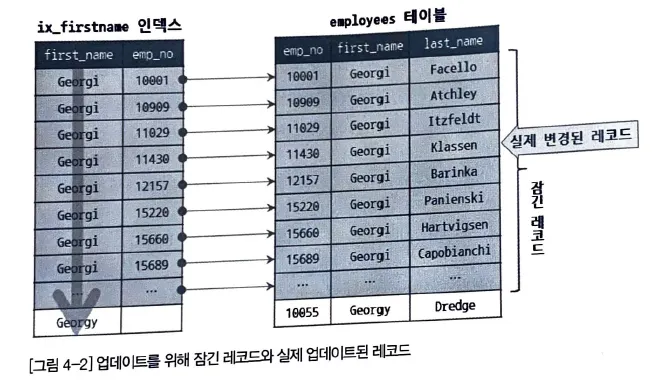
이 예제는 253개 밖에 안되지만, 적절한 index 가 준비되지 않는다면 수백만건의 record 가 대기상태가 되어 update 작업이 종료되길 기다리는 상황이 올 수 있다.
만약, 이 table 에 index 가 하나도 없다면 어떻게 될까?
table 읠 full scan 하면서 update 작업을 하는데, 30만건이 있다면 모든 record 를 잠그게 된다.
transaction 격리 수준과 잠금
앞의 불필요한 잠금 현상은 InnoDB 의 next key lock 때문에 발생하는 것이다. next key lock 이 필요한 이유는 복제를 위한 binary log 때문이다.
InnoDB 에서 gap lock 이나 next key lock 을 줄일 수 있다는 것은 사용자의 query 요청을 동시에 더 많이 처리할 수 있음을 의미한다.
다음 조합으로 InnoDB 에서 next key lock 이나 gap lock 을 제거할 수 있다.
•
MySQL 5.0
◦
innodb_locks_unsafe_for_binlog=1: transaction 격리 수준을 read-commited 로 설정
•
MySQL 5.1 +
◦
binary log 비활성화: transaction 격리 수준을 read-commited 로 설정
◦
record 기반의 binary log 사용,innodb_locks_unsafe_for_binlog=1
▪
격리 수준을 read-commited 로 설정
5.1 이상에선 binary log 가 활성화 되면 최소 repeatable-read 이상의 격리 수준을 사용하도록 강제되고 있다.
→ 하지만, 이러한 조합이라 하더라도 unique key 나 fk 에 대한 gap lock 은 없어지지 않는다.
위의 조합으로 걸면 InnoDB의 잠금이 없어진다.
먼저 index 만 비교해서 베타적 잠금을 걸게 되지만, 그 다음 나머지 조건을 비교해서 일치하지 않는 record 는 즉시 잠금을 해제한다.
레코드 수준의 잠금 확인 및 해제
record 수준의 잠금은 더 복잡하다. 테이블은 테이블 전체에 lock 이 걸리기 때문에 발견이 쉽지만, record 수준의 잠금은 해당 record 가 오랫동안 사용되지 않는다면 발견이 쉽지 않다.
5.0 까지는 메타 정보를 제공하지 않지만, 5.1 부터는 record 잠금과 대기에 대한 조회가 가능하므로 쿼리 하나로 확인이 가능하다.
MySQL 5.1 이상의 잠금 확인 및 해제
3개의 connection 이 있고 각각 다음과 같은 query 를 실행했다 가정하자

위의 상태만으론 어디에 lock 이 걸린것인지 확인이 어렵다.
# 어떤 잠금이 존재하는가?
select * from information_schema.innodb_locks;
# 어떤 트랜잭션이 어떤 client 에 의해 가동되는가
select * from information_schema.innodb_trx;
# 잠금에 의한 process 간 의존관계
select * from information_schema.innodb_lock_wait;
SQL
복사
하지만 각각의 테이블로는 원하는 정보를 얻기 어렵다 join 을 할 필요가 있다.
select
r.trx_id waiting_trx_id,
r.trx_mysql_thread_id waiting_thread,
r.trx_query waiting_query,
b.trx_id blocking_trx_id,
b.trx_mysql_thread_id blocking_thread,
b.trx_query blocking_query
from information_schema.innodb_lock_waits w
inner join information_schema.innodb_trx b on b.trx_id = w.blocing_trx_id
inner join information_schema.innodb_trx r on r.trx_id = w.requestiong_trx_id;
SQL
복사
실행 결과
•
34A7번(100번)이 34A6번(99번)을 기다리고 있다.
•
34A7번(100번)이 34A5번(18번)을 기다리고 있다.
•
34A6번(99번)이 34A5번(18번)을 기다리고 있다.
MySQL의 격리 수준
특정 transaction 이 다른 transaction 에서 변경하거나 조회하는 table 을 볼 수 있도록 허용할지 말지를 결정한다. 격리 수준은 다음의 4가지로 나눈다.
•
Read uncommited (dirty read)
•
Read commited
•
Repeatable read
•
Serializable
아래로 갈 수록 transaction 간 고립 정도가 높아지며, 동시성이 떨어진다.
transaction 을 언급하면 3가지 부정합에 대해 다루는데 격리 수준에 따라 발생할 수도 있고, 아닐수도 있다.
Default view
Search
Read Uncommited
transaction 내용이 commit 이나 rollback 여부에 상관 없이 다른 transaction 에 보여진다.
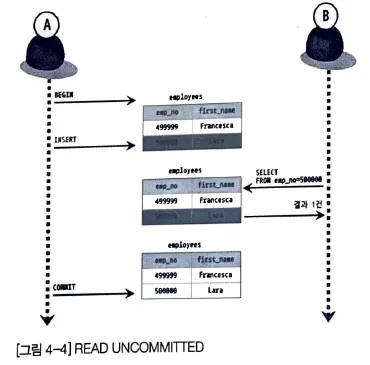
•
user A 의 insert commit 이 완료되지 않음
•
user B 는 commit 이전이더라도 insert 된 record 를 읽을 수 있다.
◦
emp_no = 50000 가 commit 전인데도 읽어옴
문제는 user A 에 에러가 발생해 rollback 이 된다 하더라도 user B는 Lara 가 직원인줄 알게 된다.
이것을 Dirty Read 라 한다.
RDMBS 에서 dirty read 는 transaction 격리 수준으로 인정하지 않을 만큼 개발자를 혼란스럽게 만든다.
Read Commited
어떤 transaction 에서 data 를 변경하더라도 commit이 완료된 데이터만 다른 transaction 에서 조회할 수 있다.
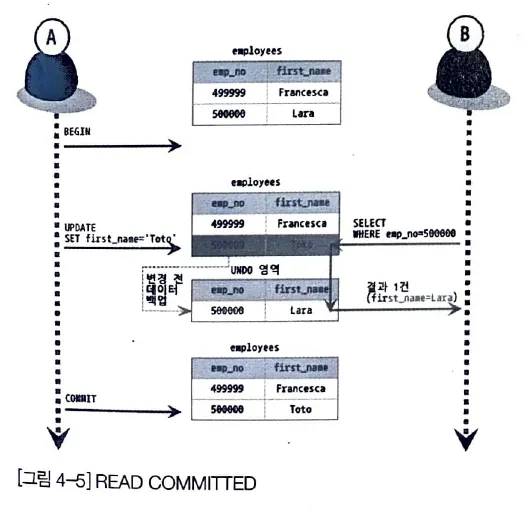
•
User A는 emp_no 이 500000인 Lara 의 first name 을 Toto 로 변경한다(commit 전)
•
그러면 500000 인 데이터는 UNDO 영역에 Lara 로 저장되고, employees 테이블은 Toto로 갱신된다.
•
User B 가 5000000 를 select 하면 UNDO 영역의 데이터인 Lara 를 읽게 된다.
•
User A 가 commit 을 완료하면 Toto 로 record 는 갱신된다.
•
만약 User B가 바로 동일한 query 를 실행하면 Lara가 아닌 Toto 를 받게 되어 반복할 수 없는 읽기가 되는 문제가 발생된ㄷ.
Read commited 수준에서 "Non-Repeatable Read" 가 발생하는 문제가 있다.
이러한 문제는 금전적인 처리와 연관 되었을 때 큰 문제를 발생시킨다.
transaction 상황에서 select와 아닌 상황에서 select 는 어떻게 다를까?
•
Read commited 격리 수준에서는 큰 차이가 없다.
•
Repeatable read 수준에서는 select 도 transaction 범위 내에서만 작동한다
◦
begin transaction 이 되면 몇번 select 를 실행해도 동일한 결과만 보게 된다.(심지어 다른 transaction 에서 변경하고 commit을 하더라도)
Repeatable Read
•
InnoDB 엔진에서 기본적으로 사용되는 격리 수준이다.
•
binary log 를 가진 MySQL 장비에서는 최소 Repeatable Read 격리 수준 이상을 사용해야 한다.
•
Rollback 에 대비해 변경되기 전 record 를 Undo 공간에 백업하고 실제 record를 변경한다.
◦
이러한 변경 방식을 MVCC(Multi Version Concurrency Control) 이라 한다.
•
모든 InnoDB transacton 은 고유한 순차적인 번호를 가지며 Undo 여역에 이 transaction 번호가 함께 저장되어 있다.
•
InnoDB 엔진이 불필요하다 판단되는 데이터를 주기적으로 삭제한다.
•
MVCC 를 보장하기 위해 실행 중인 transaction 가운데 가장 오래된 transaction 번호 이전의 transaction 에 의해 변경된 Undo 영억의 데이터는 삭제되지 않는다 (그림을 통해서 설명)
•
특정 transaction 번호의 구간 내에서 백업된 Undo 데이터가 보존돼야 한다.
다음 그림을 설명하기에 앞서 transaction id 6에 의해 데이터가 insert 되었다고 가정하자.
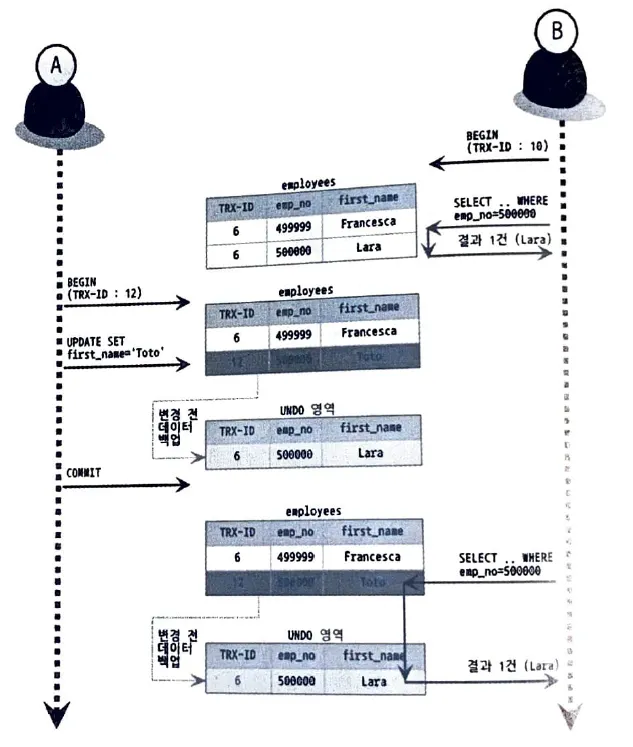
1.
User B는 trx 10 으로 select 를 실행해 Lara 를 받았다. (transaction begin)
2.
User A는 그 도중에 Lara를 Toto로 변경하고 commit 을 실행해 transaction을 종료했다.
3.
User B는 그 이후 다시 500000으로 select 하였는데 Lara 라 반한되었다.
•
trx id 10 인 User B는 10 보다 작은 trx id 값으 데이터를 보게 된다.
위 그림에선 emp_no = 500000 에 대해 back up 된 데이터가 하나만 존재하는 것으로 나오지만, 실제로는 더 많을수도 있다. Begin 으로 transaction 을 시작하고 종료하지 않는다면 Undo 영역이 무한정 커질 수 있으며, 이것은 성능에 악영향을 주게 된다.
그런데 이러한 Repeatable Read 격리 수준에서도 다음과 같은 부정합이 발생할 수 있다.
user A 가 insert 를 실행하는 도중에 user B 가 select ... for update 쿼리로 employess 테이블을 조회했을 때 결과이다
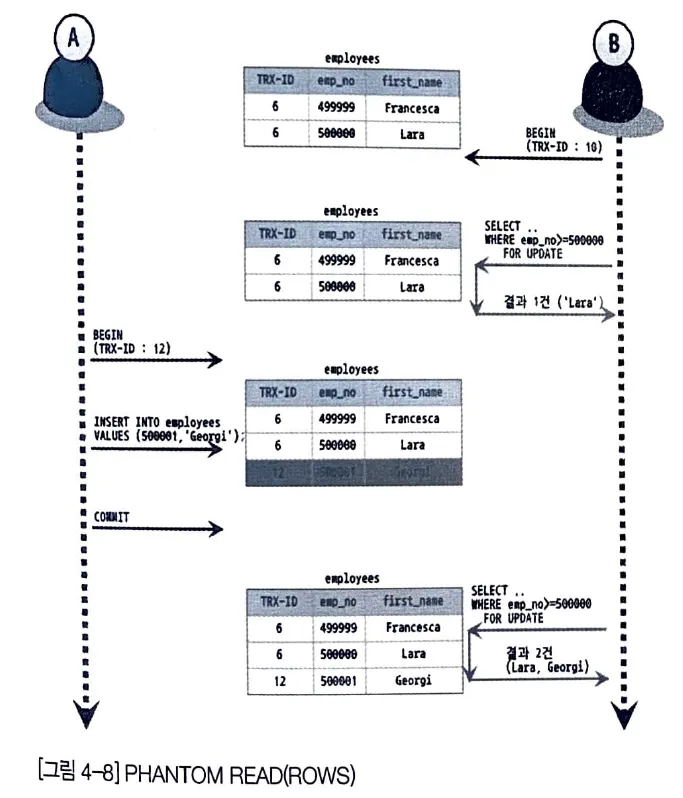
user B 는 Begin 명령으로 transaction을 시작한 후, select 를 수행하고 있다.
•
그러므로 두 번의 select 결과는 동일해야 한다.
이렇게 다른 transaction에서 수행한 변경 작업에 의해 record 가 보였다가 안보였다가 하는 현상을 Phantom read (또는 Phantom row)라고 한다.
select .. for update 쿼리는 select 하는 record 에 쓰기 잠금을 걸어야 하는데 Undo record 에는 잠금을 걸 수 없다. 그래서 Undo 영역의 변경 전 데이터를 가져오는 것이 아니라 현재 record 값을 가져오게 되는 것이다.
Serializable
Serializable 격리 수준에서는 읽기 작업도 공유 잠금(읽기 잠금)을 획득해야 하며, 동시에 다른 transaction 은 그러한 record 를 변경하지 못하게 된다.
하지만 InnoDB 에서 Repeatable read 에서도 이미 phantom read 가 발생하지 않기 때문에 굳이 Serializable 을 사용할 필요성은 없는 듯 하다.
Repeatable read 격리 수준과 Read committed 격리 수준의 성능 비교
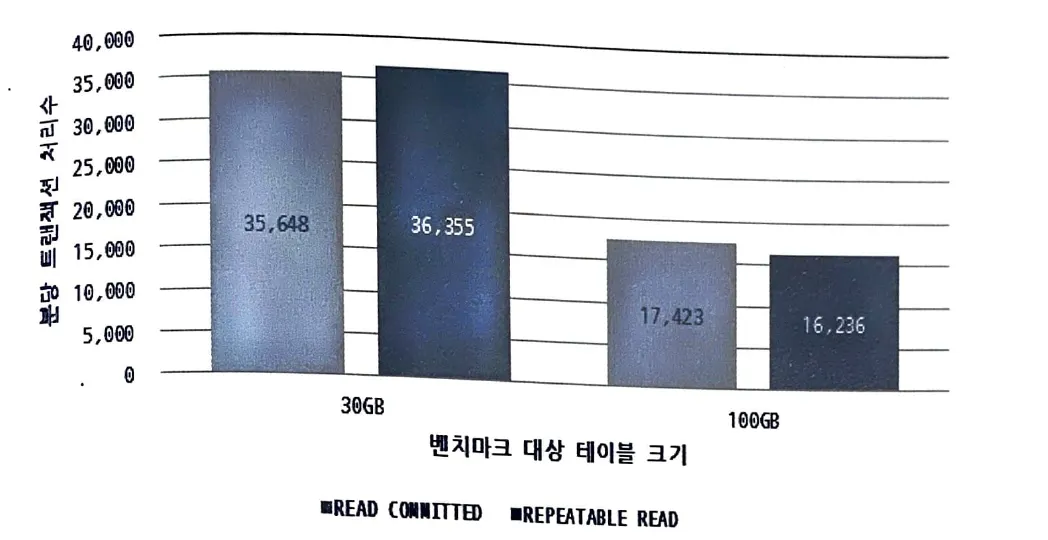
Read committed 와 Repeatable read 의 성능 차이는 크지 않다.
•
1GB와 30GB 크기의 테이블에서 Repeatable read가 2% 정도 높은 성능을 보였다
•
100GB 크기의 테이블에서 Read committed가 7% 정도 높은 성능을 보였다.
그러나 한가지 주의할 점은 binary log 가 활성화 된 MySQL 에서 Read commited 는 사용할 수 없다.