
Java 개발자가 왜 H/W 에 관심을 가져야 할까? 날로 성장해가는 device 그에 맞춰 더 복잡해지는 software 그 안에서 성능을 추구하기 위해 우리가 알아야 할 것을 살펴본다
대량 생산한 칩상의 트랜지스터 수는 약 18개월 마다 2배씩 증가한다
- 고든 무어
device 의 놀라운 발전을 이루면서 저렴해진 트랜지스터 덕분에 컴퓨터의 구조는 더욱 복잡해졌고, 이에 맞추어 소프트웨어도 상당히 복잡해졌다.
현재 소프트웨어는 우리의 사회 전반에 자리잡고 있다.
이러한 상황에서 java 는 큰 혜택을 받았다
언어 및 runtime 설계가 프로세서가 강력해지는 시류와 맞아 떨어지면서 자바는 큰 혜택을 받게 된다.
자바 프로그래머는 가용 리소스를 최대한 활용할 수 있도록 java platform 근간의 원리와 기술을 잘 알고 있어야 한다.

플랫폼 및 코드 수준에서 최적화 하는 기법과 JVM 소프트웨어 아키텍쳐는 더 뒤에서 다룬다.
여기서는 앞으로 이어질 이야기를 이해하는 단서가 될만한 H/W 와 OS에 관련한 지식을 다룬다
트랜지스터
최신 하드웨어 소개
•
이제 컴퓨터 하드웨어는 register 기반의 산술, 로직, 로드, 스토어 연산을 수행하는 뻔한 머신이 아니다
•
따라서 CPU 에게 직접 일을 시키는 C 언어가 진리의 원천인 것 처럼 여기는 것이 맞지 않다.
•
이 장에서는 발전된 CPU 기술을 알아본다
메모리
•
무어의 법칙에 따라 개수가 급증한 트랜지스터는 clock speed 를 높이는데 쓰였다.
•
하지만 clock 이 높아지니, 그 만큼 데이터 전송 속도가 받쳐줘야 하는데 시간이 갈수록 프로세서 코어의 데이터 수요를 main memory 가 맞추기 어려워졌다.
•
결국 연산 속도(clock 수)가 올라가도 데이터가 오길 기다려야 하니 소용이 없게 되었다.
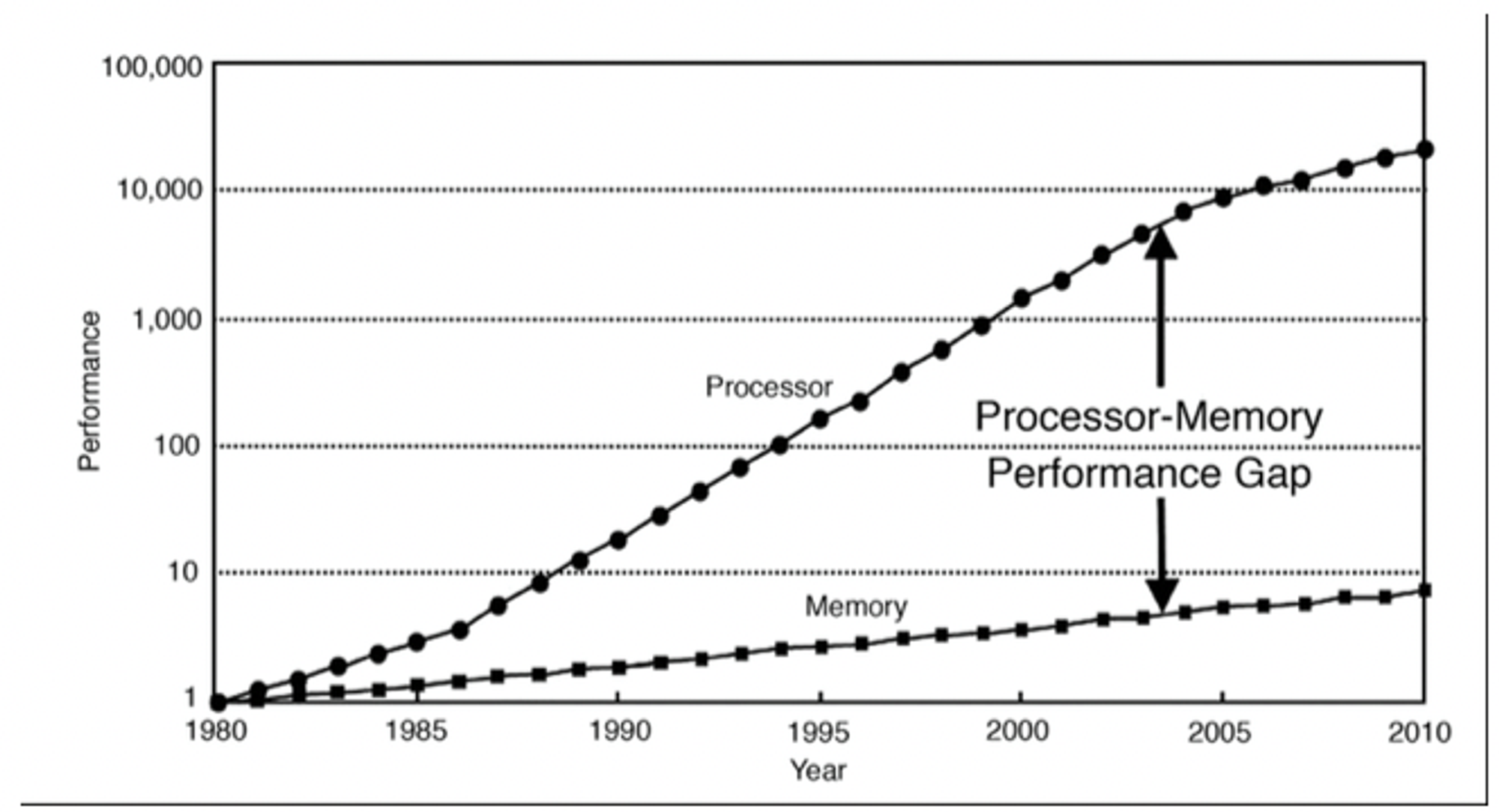
메모리 속도와 트랜지스터의 개수
메모리 캐시
•
위와 같은 문제를 해결하기 위해 고안된 것이 CPU 캐시이다.
•
CPU 캐시는 메모리 영억이며, register 보다 느리지만, main memory 보다는 훨씬 빠르다
•
CPU 가 main memory 를 재참조 않게 사본을 떠서 CPU 캐시에 보관하는 아이디어 이다.
•
요즘은 access 빈도가 높은 캐시일수록 프로세서 코어와 가까운 곳에 위치시키는 방식으로 계층을 두었다.
◦
L1: CPU와 가장 가깝다 (코어 전용 private 캐시)
◦
L2: 그 다음 캐시 (코어 전용 private 캐시)
◦
L3: 모든 코어가 공유하는 캐시(혹은 일부만 공유하기도 한다)
•
프로세서 아키텍처에 따라 캐시 개수 및 설정 상태는 제각각 이다.
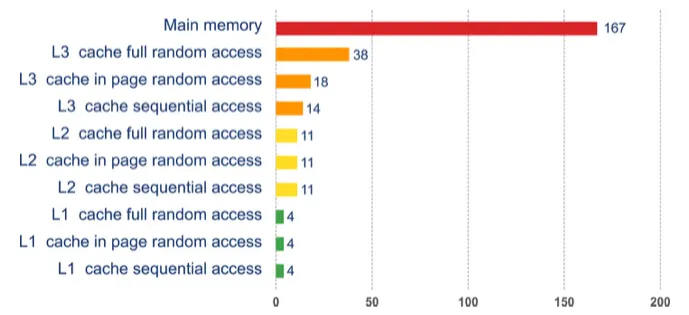
다양한 메모리 종류별 액세스 시간
이렇게 CPU 캐시를 추가하여 access 시간을 줄이고 코어가 처리할 데이터를 계속 채워 넣는다
clock 속도와 access 시간 차이 때문에 CPU 는 캐시에 더 많은 비용을 투자하게 된다.
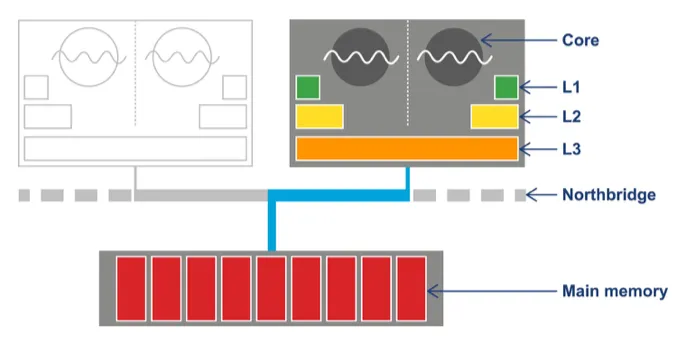
전체 CPU 및 메모리 아키텍처(Northbridge 컴포넌트를 거쳐 액세스 하고 이 버스를 관통하기 때문에 메인 메모리 엑세스 시간이 줄어든다)
프로세스 처리율이 해결 되었지만, 또 새로운 문제가 생겼다.
데이터를 메모리 → cache, cache → 메모리 로 옮겨야 하는지 다시 결정해야 했는데 이것은 캐시 일관성 프로토콜, cache consistency protocol 이란 방법으로 해결한다.
책 후반부에서 언급되는데 이와 같이 캐싱한다면 concurrency programming 에서 문제가 발생한다
MESI 라는 프로토콜이 굉장히 자주 언급되는데
이것은 캐시 라인(64 bytes)에서 다음의 4가지 상태로 정의한다.
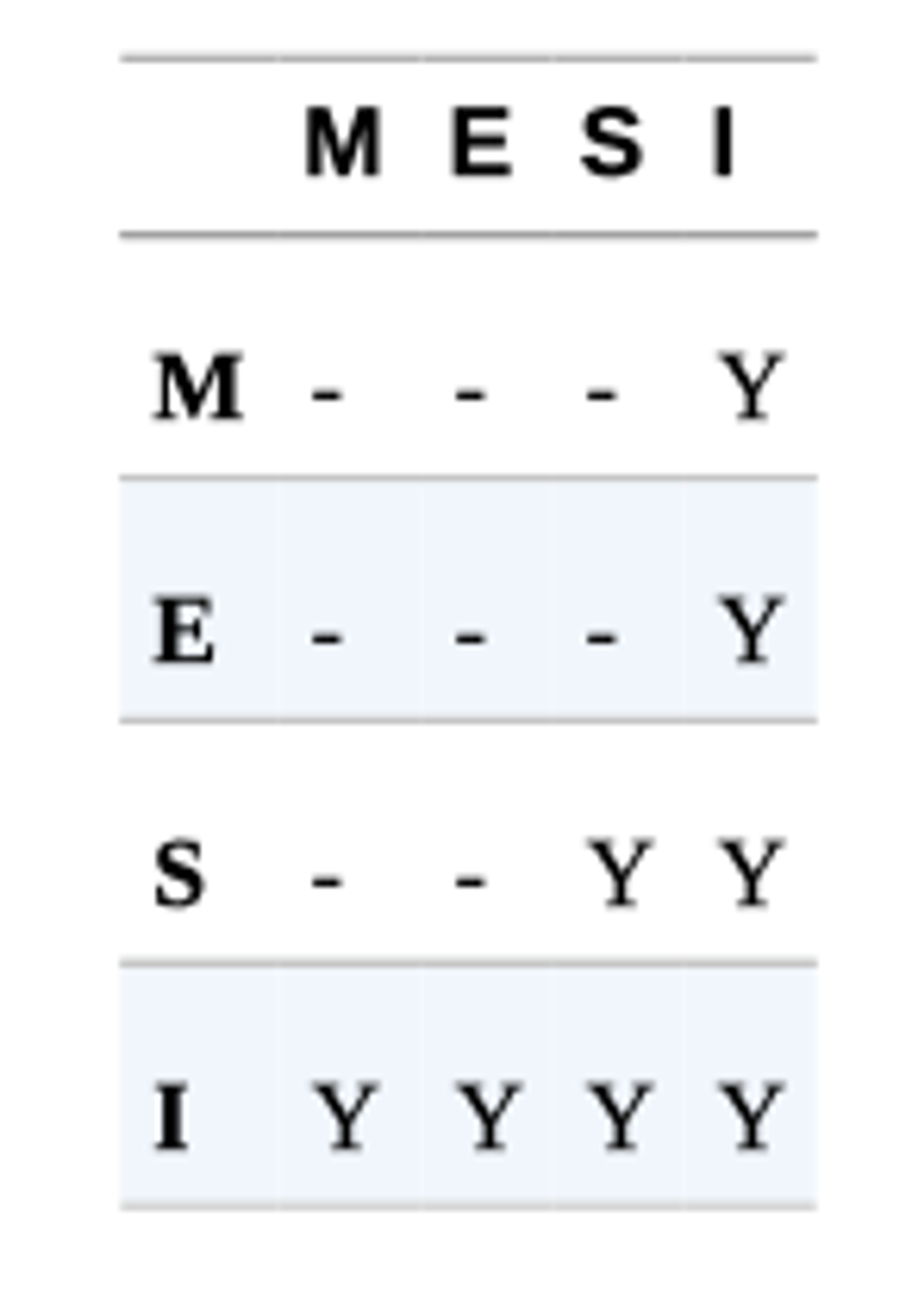
1.
Modified: 데이터가 수정된 상태
2.
Exclusive: 이 캐시에만 존재하고 main memory 내용과 동일한 상태
3.
Shared: 둘 이상의 캐시에 데이터가 들어 있고, 메모리 내용과 동일한 상태
4.
Invalid: 다른 프로세스가 데이터를 수정하여 무효한 상태
이 상태가 의미하는 것은 multi-processor 가 동시에 공유 상태에 있을 수 있다는 것을 의미한다.
하지만, 프로세서가 배나, 수정 상태로 바뀌면 다른 프로세서는 모두 Invalid 상태로 전환된다.
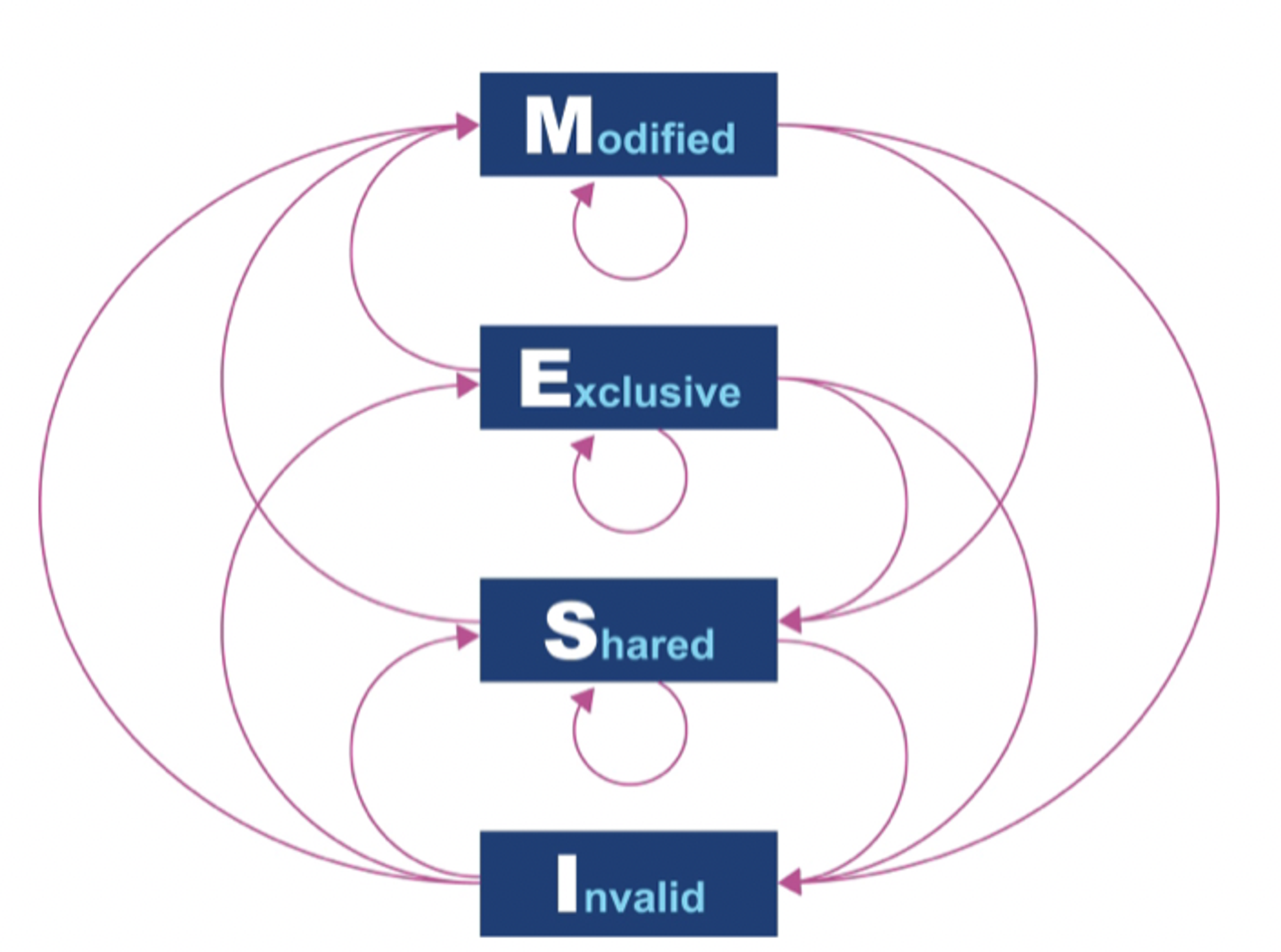
MESI 상태 변이 다이어그램
프로세서가 처음 나왔을 때는 매번 캐시 연산 결과를 바로 메모리에 기록(동시 기록: write-through)했지만, 메모리 대역폭을 너무 많이 소모하여 효율이 낮아 요즘은 사용하지 않는다.
결국 후기록(write-back) 방식을 채택하여 캐시 블록을 교체해도 프로세서가 변경된 캐시 블록만 메모리에 기록하여 main memory 로 돌아가게 만들어 트래픽이 많이 떨어졌다.
캐시 하드웨어의 작동 원리를 나타낸 간단한 코드를 살펴본다
public class Caching {
private static final int ARR_SIZE = 2 * 1024 * 1024;
private static final int[] testData = new int[ARR_SIZE];
private void run() {
System.err.println("Start: " + System.currentTimeMillis());
for (int i = 0; i < 15_000; i++) {
touchEveryLine();
touchEveryItem();
}
System.err.println("Warmup finished: " + System.currentTimeMillis());
System.err.println("Item Line");
for (int i = 0; i < 100; i++) {
long t0 = System.nanoTime();
touchEveryLine();
long t1 = System.nanoTime();
touchEveryItem();
long t2 = System.nanoTime();
long elItem = t2 - t1;
long elLine = t1 - t0;
double diff = elItem - elLine;
System.err.println(elItem + " " + elLine + " " + (100 * diff / elLine));
}
}
private void touchEveryItem() {
for (int i = 0; i < testData.length; i++) {
testData[i]++;
}
}
// 한번에 i가 16씩 뛴다. 2^22 까지
private void touchEveryLine() {
for (int i = 0; i < testData.length; i += 16) {
testData[i]++;
}
}
public static void main(String[] args) {
Caching c = new Caching();
c.run();
}
}
Java
복사
캐싱 예제
위 코드에서 touchEveryItem 가 touchEveryLine 에 비해서 16배의 일을 한다고 예측된다.
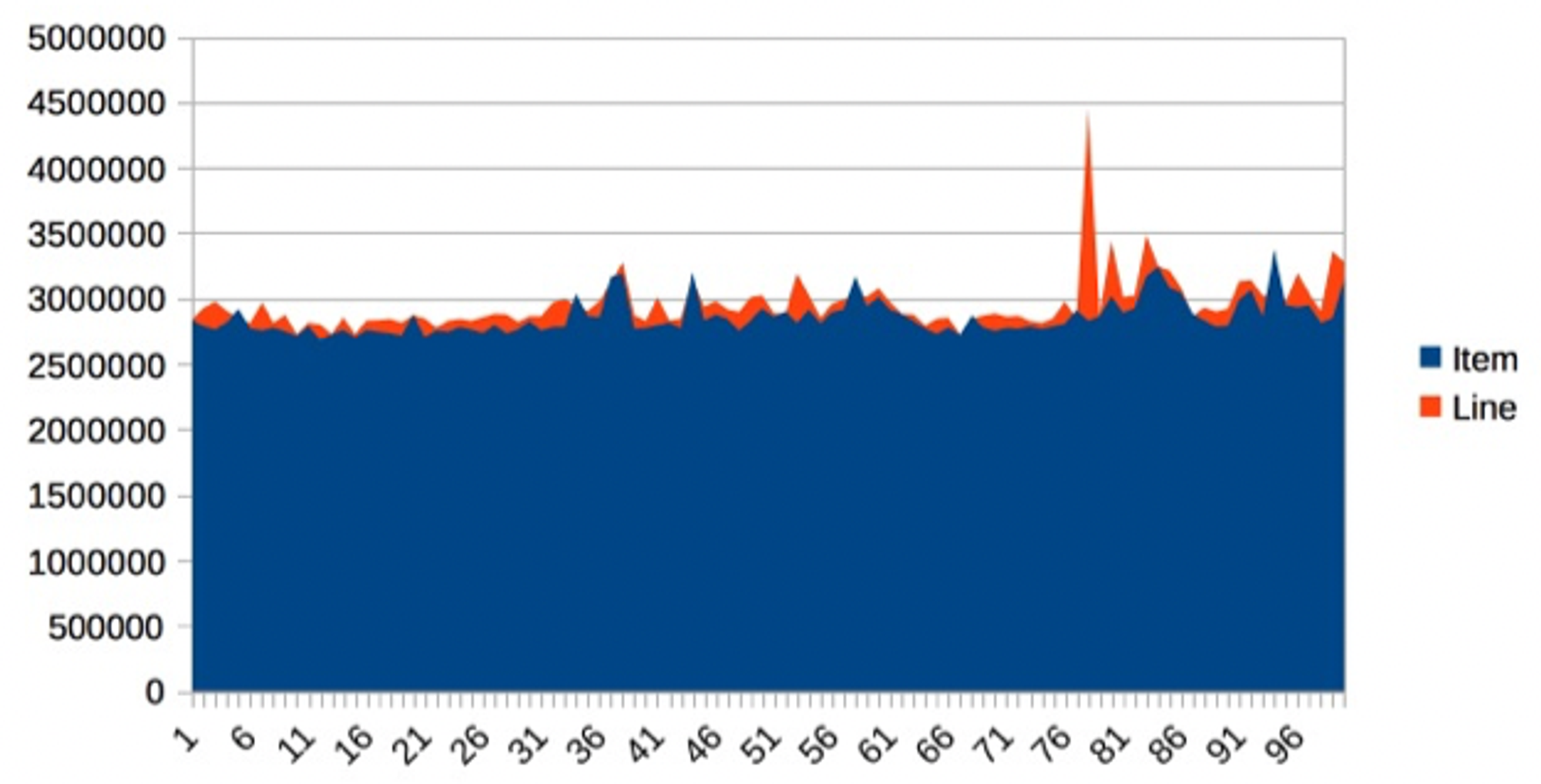
캐싱 예제의 소요 시간 100MB 메모리를 이동을 1회 할 때 대략 2.86ms 걸린다.
하지만, 직감으로는 잘못된 판단을 하기 쉽다. 이 샘플의 결과는 위와 같이 큰 차이가 없다.
가장 영향을 많이 미치는 것은 i 로 접근하는 개수가 아니라, memory 버스를 예열하는 부분이다.
위 두 method 를 활용해 배열의 데이터를 main memory → 캐시 로 이동하는 코드이다.
간혹 30~35% 정도 벗어난 특이점이 나오는데 이 부분이 해당한다.
최신 프로세서의 특성
메모리 캐시는 점점 증가한 트랜지스터를 가장 확실하게 활용하지만, 지난 수년간 여러가지 다른 기술도 등장했다.
변환 색인 버퍼(TLB, Translation Lookaside Buffer)
•
캐시에서 요긴하게 사용되는 장치
•
TLB는 가상 메모리 주소를 물리 메모리 주소로 매핑하는 페이지 테이블의 캐시 역할을 수행한다.
•
덕분에 가상 주소를 참조해 물리 주소에 접근하는 빈번한 작업 속도가 매우 빨라진다.
•
TLB 가 없다면 가상 주소 lookup 에 16 cycles 이 필요하여 성능이 제대로 나오지 않는다.
분기 예측과 추측 실행(Branch prediction)
•
processor 가 분기하는 기준값을 평가하느라 대기하는 현상을 방지한다.
•
차세대 CPU 는 다단계 명령 pipeline 을 사용해 CPU 1 사이클도 여러 단계로 나누어 실행한다.
•
이런 모델은 조건문을 다 평가하기 전까지 분기 이후 다음 명령을 모른다.
◦
이 결과로 분기문 뒤에 나오는 pipeline 을 비우는 동안 프로세서는 여러 사이클(최대 20회) 동안 멈춘다
이런일이 없도록 CPU 는 가장 발생 가능성이 높은 브랜치를 미리 결정하는 heuristics(휴리스틱 이론)을 통해 예측하는데, 예측이 맞다면 바로 해당 브랜치 작업을 실행하고 틀렸다면 실행한 명령을 모두 폐기한 후 pipeline 을 비우는 비용을 지불한다.
하드웨어 메모리 모델
어떻게 하면 CPU가 일관되게 동일한 메모리 주소를 access 할 수 있을까?
→ multi-core 시스템에서 메모리에 대한 근본적인 질문이다.
이 문제를 JIT 컴파일러인 javac 와 CPU는 일반적으로 코드 실행 순서를 바꿀 수 있다.
(단, 바꿔도 문제 없다는 가정 하에서)
myInt = otherInt;
intCharged = true;
Java
복사
순서가 바뀌어도 상관없는 코드의 예시
두 할당문 사이에 다른 코드가 없으니 thread 입장에선 어떤 순서로 오든 상관 없어, 순서를 자유롭게 바꿀수 있다
그러나, 바라보는 thread 입장에서 순서가 달라지만 intChareged 는 true 로 보여도 myInt 는 이전 값 일 수 있다.
이런 방식은 x86 에선 불가능하고, CPU 아키텍처 마다 조금씩 차이가 있다.
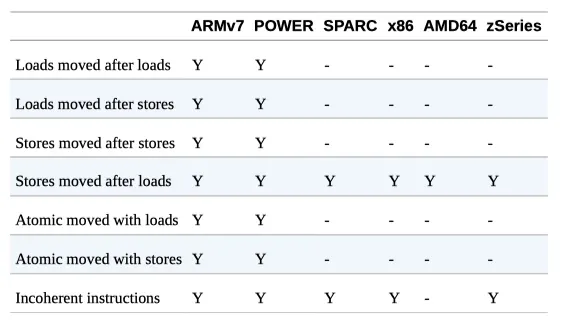
하드웨어 메모리 지원
JMM은 프로세서 타입별로 메모리 일관성을 고려하여 명시적으로 weak model 로 설계되었다.
따라서 multi-thread 코드가 제대로 동작하려면 lock 과 volatile 을 정확히 알고 사용해야 한다.
운영체제
•
OS 의 임무는 실행하는 process 가 공유하는 resource access 를 관장하는 것이다.
◦
resource: CPU, 메모리
•
resource 는 한정되어 있고, preocess 는 저마다 더 많은 resource 를 차지하려고 한다
•
따라서 남은 resource 양을 골고루 나누어 줄 중앙 시스템이 필요하다
Memory Management Unit(MMU, 메모리 관리 유닛)을 통한 가상 주소 방식과 페이지 테이블은 memory access 제어의 핵심으로, 한 process 가 소유한 메모리 영역을 다른 process 가 훼손하지 못하게 한다.
•
앞에서 설명한 TLB의 경우는 물리 메모리 주소 look up을 줄이는 하드웨어 기능이다
•
메모리를 사용하면 S/W 가 엑세스 하는 시간이 빨라진다
•
메모리는 개발자가 다루기엔 너무 low level 이므로 스케쥴러에 대해 살펴본다.
스케쥴러
•
스케쥴러는 CPU 접근을 통제한다
•
이때 Run Queue(실행 큐)를 사용하여 접근을 통제한다
◦
최신 시스템은 사용 가능한 수준보다 더 많은 thread/process 로 가득하기 때문에 CPU 경쟁을 해결할것이 필요하다
•
스케쥴러는 인터럽트에 응답하고 CPU 코어 access 를 관리한다.
•
자바 thread 가 굳이 OS 에서 사용하는 thread 과 일치시킬 필요는 없지만 이것이 상당히 효율적이다
◦
실제로는 굳이 일치 시킬 필요가 없다고 명시되었지만 유용하지 않아 배제됨
다음은 자바 thread 의 life cycle이다.
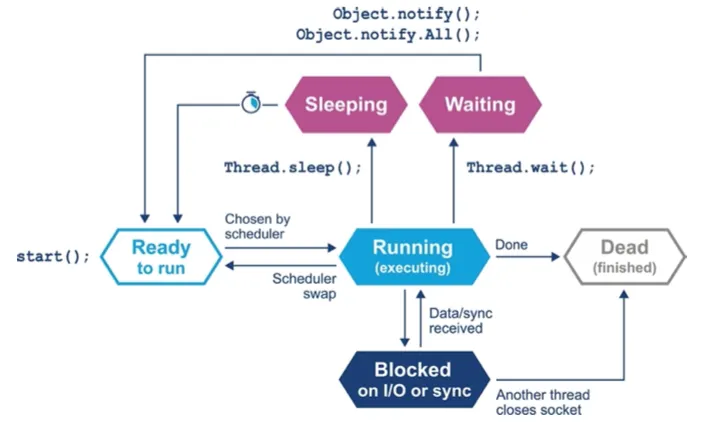
Java Thread: thread life cycle
•
스케쥴러는 할당시간 끝에 Run queue 를 사용해 thread 를 되돌려 큐의 맨 앞으로 배치시켜 다시 실행되게 한다.
•
thread 는 자신이 할당받은 시간을 포기하려면 sleep(), wait() 을 사용한다
◦
sleep() 잠드는 시간 명시
◦
wait() 대기조건 명시
◦
s/w 락에 걸려 blocking 될 수 있음
•
진정한 multi-processing 환경에서 어떻게 실행될지 매우 복잡하고 예측이 어렵다
•
OS는 특성상 CPU 에서 코드가 실행되지 않는 시간을 유발한다
•
정작 코드가 실행되는 시간보다 대기하는 시간이 더 많다
스케쥴러의 움직임을 확인해보자
OS 가 스케쥴링 과정에서 발생시킨 오버헤드를 확인해보자
long start = System.currentTimeMillis();
for (int i = 0; i < 1_000; i++) {
Thread.sleep(1);
}
long end = System.currentTimeMillis();
System.out.println("Millies elasped: " + (end - start) / 4000.);
Java
복사
1000회를 슬립한다면 1초간 쉬는게 된다.
thread 는 한번 잠 들때마다 큐의 뒤로가고 새로 시간을 할당받을 때까지 기다린다
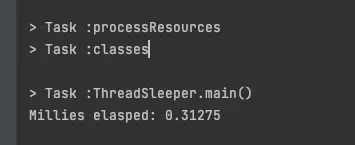
내 컴퓨터에선 0.3초
•
OS마다 코드의 실행 결과는 천차만별이다. unix 는 10~20%가 오버헤드이다
•
윈도우 초기 버전 180% 정도의 비효율이 있었다고 한다
조금 더 확실한 비교군
시간 문제
자바 플랫폼에선 타이밍을 어떻게 처리하는지 JVM 하부, OS가 타이밍을 지원하는 방법을 알아보자
POSIX(Portable Operating System Interface) 와 같은 표준이 있더라도 OS 는 저마다 다르게 동작한다
java의 System.currentTimeMillis() 는 OS의 os::javaTimeMillis() 를 사용하는데 그 구현이 다르다
jlong os::javaTimeMillis() {
timeval time;
int status = gettimeofday(&time, NULL);
assert(status != -1, "bsd error");
return jlong(time.tv_sec) * 1000 + jlong(time.tv_usec / 1000);
}
WebAssembly
복사
BSD 유틱스(mac OS)
솔라리스, 리눅스, AIX 등의 코드도 BSD와 같지만 유독 windows 만 완전히 다르다
jlong os::javaTimeMillis() {
if (UseFakeTimers) {
return fake_time++;
} else {
FILETIME wt;
GetSystemTimeAsFileTime(&wt);
return windows_to_java_time(wt);
}
}
WebAssembly
복사
윈도우 MS
이렇게 다른 이유는
•
윈도우는 유닉스의 timeval 구조체 대신 64bit FILETIME 구조체를 이용해 1601년 이후 경과한 시간을 100나노초 단위로 기록한다
◦
timeval: 1970년 1월 1일 자정 기준으로 1초씩 흐른 시간을 4byte 로 나타낸다
•
윈도우는 H/W 따라 달라진다.
Context switches
정의: OS 스케쥴러가 현재 실행중인 thread/task 를 없애고 대기중인 다른 thread/task 로 대체하는 프로세스로 thread 실행 명령과, stack 상태를 교체하는 모든일에 연관있다.
•
user 의 thread 사이에 발생하거나
•
유저 모드에서 커널 모드로 바뀌면서 mode switch 가 일어난다
•
mode switch 가 훨씬 비싼 작업이다.
유저 공간에 있는 코드가 access 하는 메모리 영역은 kernel 코드와 거의 공유할 부분이 없기 때문에 모드가 변경되면 명령어와 다른 캐시를 강제로 비워야 한다
→ 이때 TLB를 비롯한 다른 캐시도 무효화 된다.
이 캐시들은 system call 반환 시 다시 채워야 하므로 커널 모드 교환의 영향은 유저 공간으로 다시 제어권이 넘어가도 당분간 이어진다. 이로인해 성능 하락이 이어진다
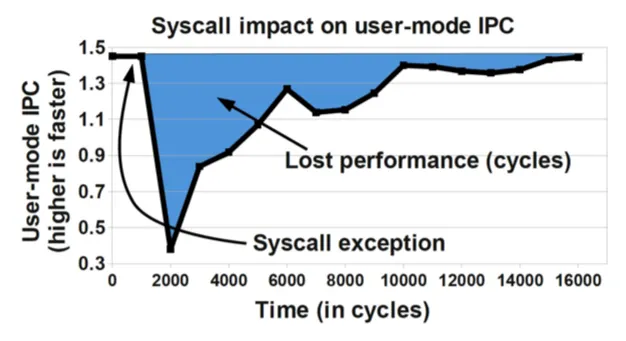
system call 이 미치는 영향
리눅스는 이 성능하락을 만회하기 위해 가상 동적 공유 객체(vDSO: Virtual Dynammically Shared Object) 라는 장치를 제공한다.
•
vDSO 는 kernel privileges(특권) 이 필요 없는 system call의 속도를 높이는데 사용하는 유저 공간의 메모리 영역이다.
•
커널 모드로 context switch 를 하지 않기 때문에 그만큼 속도가 빠르다
◦
그렇다면 system call 의 결과를 캐싱해두고 사용하는건가?
실제 동작은 다음과 같다
•
gettimeofday() OS에서 자주 쓰이는 system call 이다.
•
커널 자료 구조를 읽어 시스템 클록 시간을 얻는다
•
side effect 가 없어 privileged access 가 필요 없다.
◦
(side effect 가 있다면 privileged access가 필요함)
•
이 자료구조를 vDSO 로 유저 프로세스 주소 공간에 매핑만 된다면 커널 모드로 변경할 필요가 없다.
•
따라서 위 그래프의 파란색 만큼의 손실을 감내하지 않아도 된다.
타이밍 자료를 빈번하게 호출하는 java application 에서는 이러한 식으로 성능을 끌어올린다.
단순 시스템 모델
단순한 시스템 모델을 예로 들어 성능 문제를 일으키는 근원을 알아본다. 예시 시스템 모델은 자바 application 의 단순한 개념으로 다음의 컴포넌트로 구성되었다
•
application 이 실행되는 H/W 와 OS
•
application 이 실행되는 JVM container
•
application code itself
•
application 이 호출하는 외부 시스템
•
application 으로 유입되는 트래픽
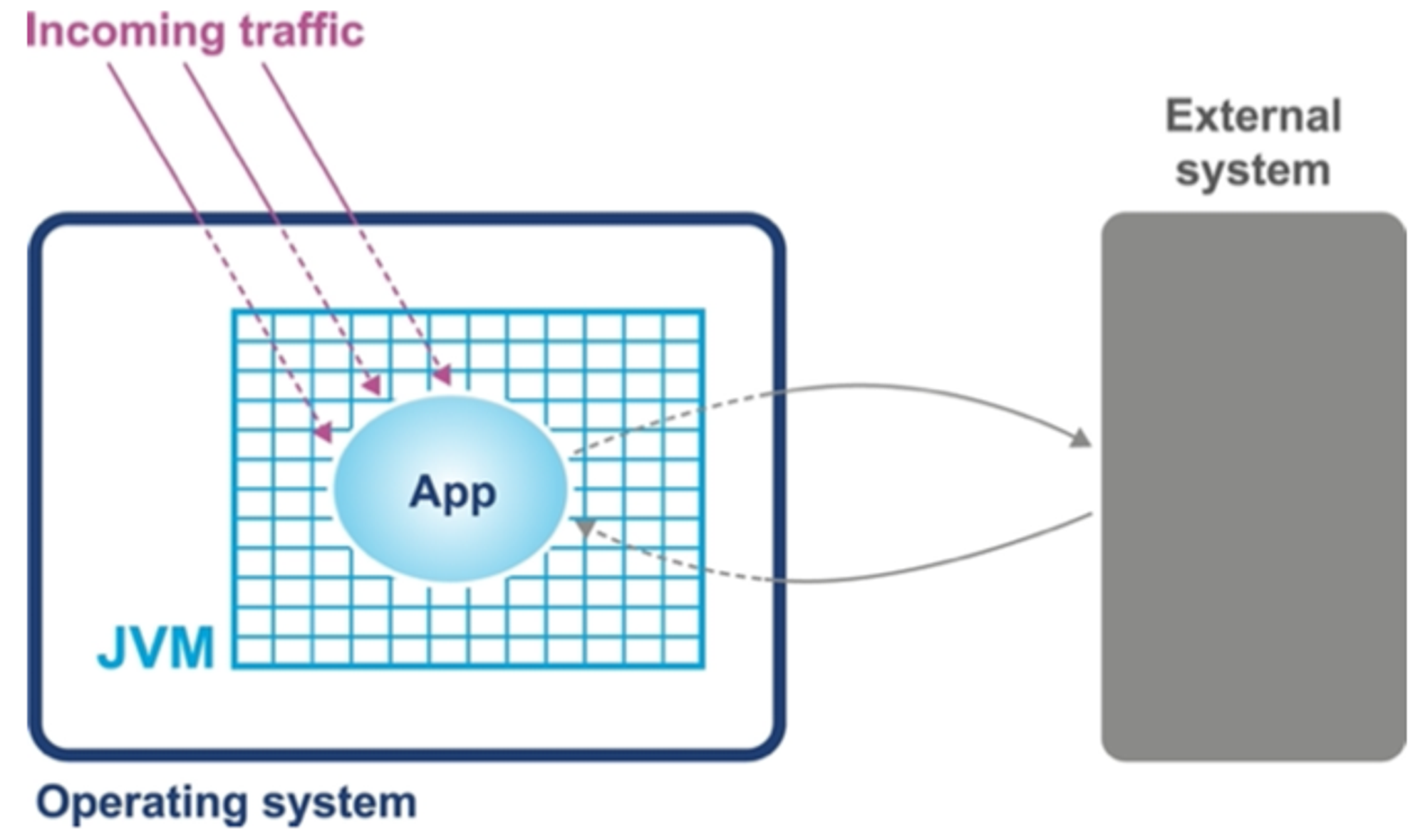
단순 시스템 모델
이들 중 누구라도 성능 문제를 일으킬 수 있다.
다음 절에서 부위를 좁히거나 격리하는 방법으로 누가 성능 문제를 일으키는지 밝혀내는 진단 기법을 알아본다
기본 감지 전략 Basic Detection Strategies
application 이 잘 돌아간다 → CPU 사용량, 메모리, 네트워크, I/O 대역폭 등 시스템 resource 를 효율적으로 잘 이용한다는 뜻이다.
하나 이상이 리소스를 소진하면 곧바로 성능 문제가 발생된다.
•
진단에 있어 첫 단계는 어떤 resource 가 한계에 이르렀는지 인식하는 것이다.
•
부족한 리소스가 뭔지 모른다면 제대로 튜닝할 수 없다.(가용 리소스를 늘리든, 효율을 높이든)
•
OS 자체가 리소스를 잡아먹는 원흉이 되어선 안된다.
◦
OS의 임무는 user process 대신 리소스를 관리하는 것이지 소모하는것이 아니다.
CPU 사용률
•
CPU 사용률은 성능을 나타내는 핵심 지표이다.
◦
CPU의 효율적인 사용이 성능 향상의 지름길이다
◦
부하가 집중되는 도중에 사용률이 가능한 100%에 가까워야 한다
성능 엔지니어라면 vmstat, iostat 을 능숙하게 다뤄야 한다
각각 현재 가상 메모리 및 I/O 서브 시스템상태에 관한 유용한 데이터를 제공 받는다
vmstat 1
가상 메모리
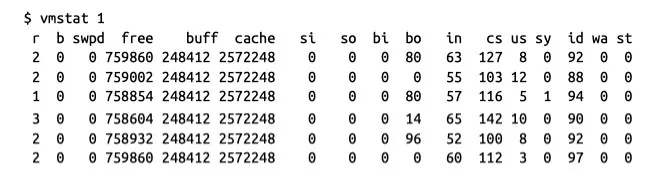
vmstat 1 은 스냅샷을 한번만 찍는게 아니라 1초마다 찍어 다음 줄에 결과를 표시한다
결과가 비교적 이해하기 쉽고 유용한 데이터로 구성되어 있어 섹션별로 자세히 살펴본다
1.
proc: 실행 가능한(r) 프로세스, 블록킹된(b) 프로세스 개수
2.
memory: swap memory, 미사용(free) 메모리, 버퍼로 사용한 메모리 (buff), cache memory가 표시된다
3.
swap: 디스크로 교체되어 들어간(swap-in) 메모리(si), disk에서 교체되어 빠져나온 메모리(swap-out) so 정보
•
최신 머신은 스왑이 많이 일어나지 않는다
4.
io: block-in(bi), block-out(bo) 개수는 각각 블록(I/O) 장치에서 받은 512 bytes 블록, 블록 장치로 보낸 512 bytes 블록 개수이다
5.
system: 인터럽트(in), 초당 context switch 횟수(cs)
6.
cpu: cpu 직접 연관된 지표를 CPU 사용률 %로 표시한다.
•
us: 유저 시간
•
sy: 커널 시간(system time)
•
id: 유휴 시간
•
wa: 대기 시간
•
st: 도둑맞은 시간(vm에 할애된 시간)
기본툴 이지만 무시할 수 없으며 프로세스와 OS에 거의 맞닿아 단순한 툴은 시스템의 실제 작동을 거의 그대로 드러낸다.
예를 들면 위의 context switch 의 경우 CPU 가 100%에 닿도록(계산 작업 application 의 경우) 설계되었는데 CPU는 100%가 아니면서 cs 의 수치가 높다면 I/O 에서 블록킹이 일어났거나 thread lock 이 벌어졌을 가능성이 이 크다
그러나, vmstat 만으로 여러 가지 경우의 수를 구분하기 어렵다
I/O 문제를 감지하기엔 좋지만 thread lock 경합을 실시간으로 감지하려면 VisualVM 과 같은 툴이 필요하다
Garbage Collection
6장에서 자세히 다룰 내용이다.
•
hotspot JVM 은 시작 시 메모리를 유저 공간에 할당/관리 한다
•
메모리 할당을 위한 sbrk() 같은 system call 을 할 필요가 없다.
◦
즉, GC를 위해 커널 교환을 할 일이 거의 없다.
•
따라서 system 에서 CPU 사용률이 높게 나타났을 때 GC 대부분의 시간을 소비하는 주범이 아니다.
•
GC 자체는 CPU 사이클을 소비하되 커널 공간의 사용률에는 영향을 미치지 않는 활동이다.
•
반면 user 공간에서 CPU 를 100% 가깝게 사용하고 있다면 GC를 의심해야 한다.
•
vmstat 등으로 성능을 분석을 할 때 CPU 사용률이 100%로 일정하지만 모든 사이클이 유저 공간에서 소비되고 있다면 JVM의 문제인지 user code 의 문제인지 확인해야 한다.
•
JVM 에서 GC 로깅은 꽁짜나 다름없다.
입출력
I/O 는 시스템 성능에 암적인 존재이다. 애플리케이션 개발자가 적절히 추상화할 장치가 없다.
다행히 자바는 단순한 I/O 만 처리한다.
또한 CPU, 메모리 어느 한쪽과 I/O를 동시에 고갈시키는 application 은 거의 없다.
성능을 분석한다면 application 에서 I/O가 어떻게 일어나는지 인지하는 것만으로도 충분하다
커널 바이패스 I/O
•
kernel 을 이용해 데이터를 복사해 user 공간에 넣는 작업이 비싼 고성능 작업이다.
◦
그래서 커널 대신 직접 네트워크 카드에서 유저가 접근 가능한 영역을 데이터를 매핑하는 전용 하드웨어/소프트웨어를 사용한다.
◦
이렇게 하면 커널 공간과 유저 공간 사이를 넘다드는 행위 "이중 복사"를 막을 수 있다.
•
그러나 자바는 이러한 구현체를 제공하지 않으므로 필요한 기능을 구현하려면 커스텀 라이브러리를 써야 한다.
•
유용한 기능이기 때문에 고성능 I/O가 필요한 시스템에서 일반적으로 구현한다
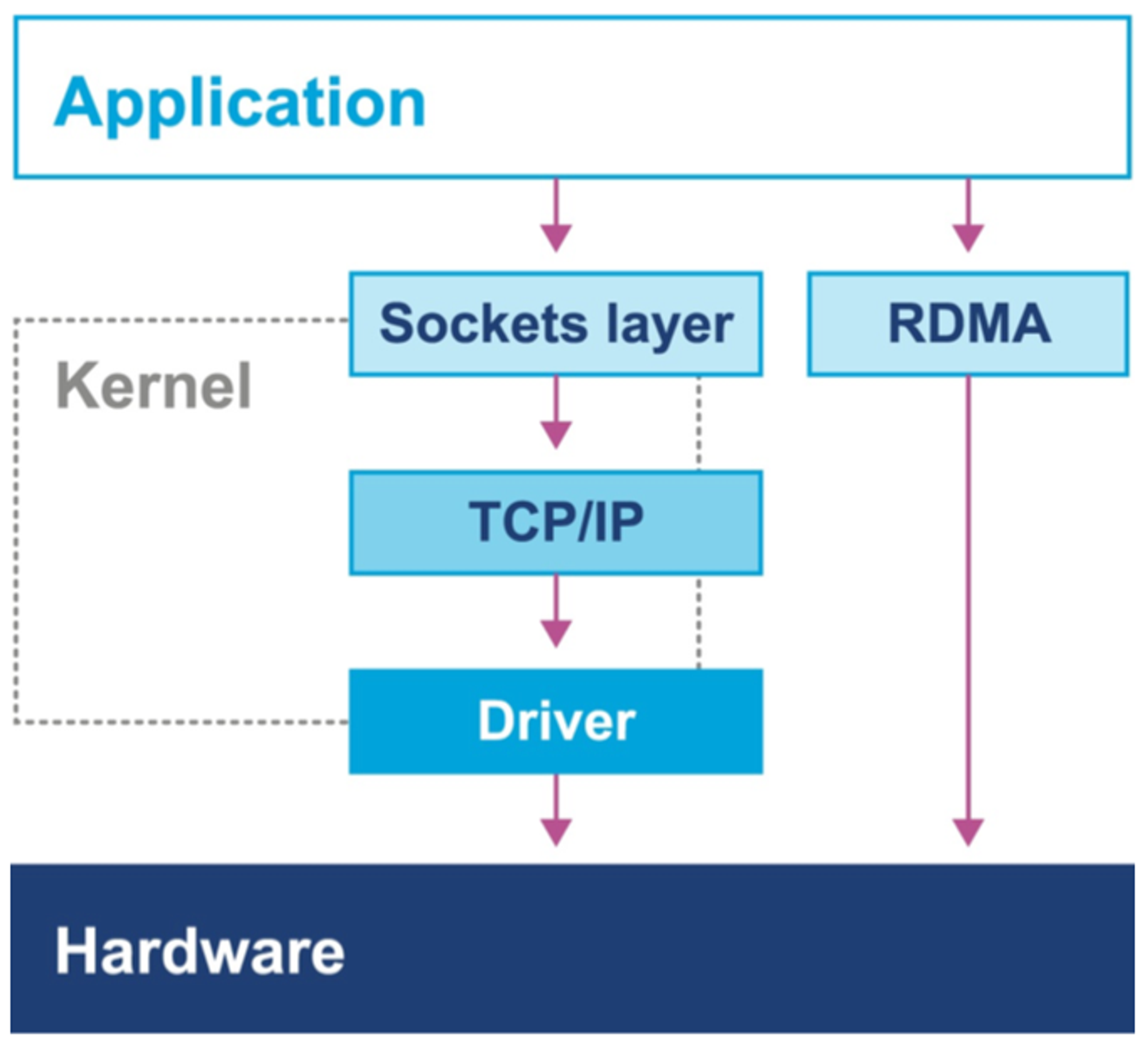
커널 바이패스 I/O
이제는 bare metal(OS조차 설치되지 않은 H/W) 에서 동작하는 OS에 대한 내용을 다루었지만
이제는 가상 환경에서 운용하는 사례가 늘기 때문에 java application 을 바라보는 엔지니어의 시각이 어떻게 달라지는지 알아본다
기계 공감 Mechanical Sympathy
기계 공감은 성능을 조금이라도 더 쥐어짜야 하는 상황에서 H/W 를 폭넓게 이해하고 공감할 수 있는 능력이 중요하다는 생각이다.
•
극단적인 사례 뿐 아니라 제품과 관련하여 여러 문제에 봉착해서 app의 성능 향상이 필요한경우 살펴볼 내용이다.
•
성능에 관련해 H/W 를 JVM 이 추상화한 부분
◦
JVM이 추상화 한 부분을 굳이 개발자가 알아야 하는가?
•
Java/JVM 을 효과적으로 활용하기 위해 JVM 이란 무엇인지, H/W 와 어떻게 상호작용 하는지 이해해야 한다
프로세스 캐시가 앞에서 성능 향상을 가져온 부분을 설명했다.
multi-thread 환경에서 두 thread 가 동일한 캐시 라인에 있는 변수를 읽거나 쓰려고 하면 어떻게 될까?
1.
경합이 발생한다 (race condition)
2.
thread-A 가 thread-B 의 캐시 라인을 무효화 하면 memory 에서 다시 읽어야 한다
3.
thread-B 가 작업을 마치면 thread-A 의 캐시라인을 무효화 한다
이러한 문제를 어떻게 해결하여 캐시를 효율적으로 사용할까?
이러한 문제 해결에 있어 기계 공감이 key point 가 된다.
•
자바의 객체는 필드 배치가 고정돼 있지 않기 때문에(?) 캐시 라인을 공유할 변수를 찾을 수 있고
•
변수 주변에 padding 을 넣어 강제로 다른 캐시 라인으로 보내는 것도 방법이다.
이러한 방법을 생각할 수 있는건 기계적 공감 위에서 일어난다
가상화
가상화는 다양한 종류가 있지만 실행중인 host OS 위에 guest OS를 실행하는 설계이다.
가상화에 대한 모든것을 다룰 수는 없지만, 무엇이 달라지는지를 간단히 짚고 넘어간다
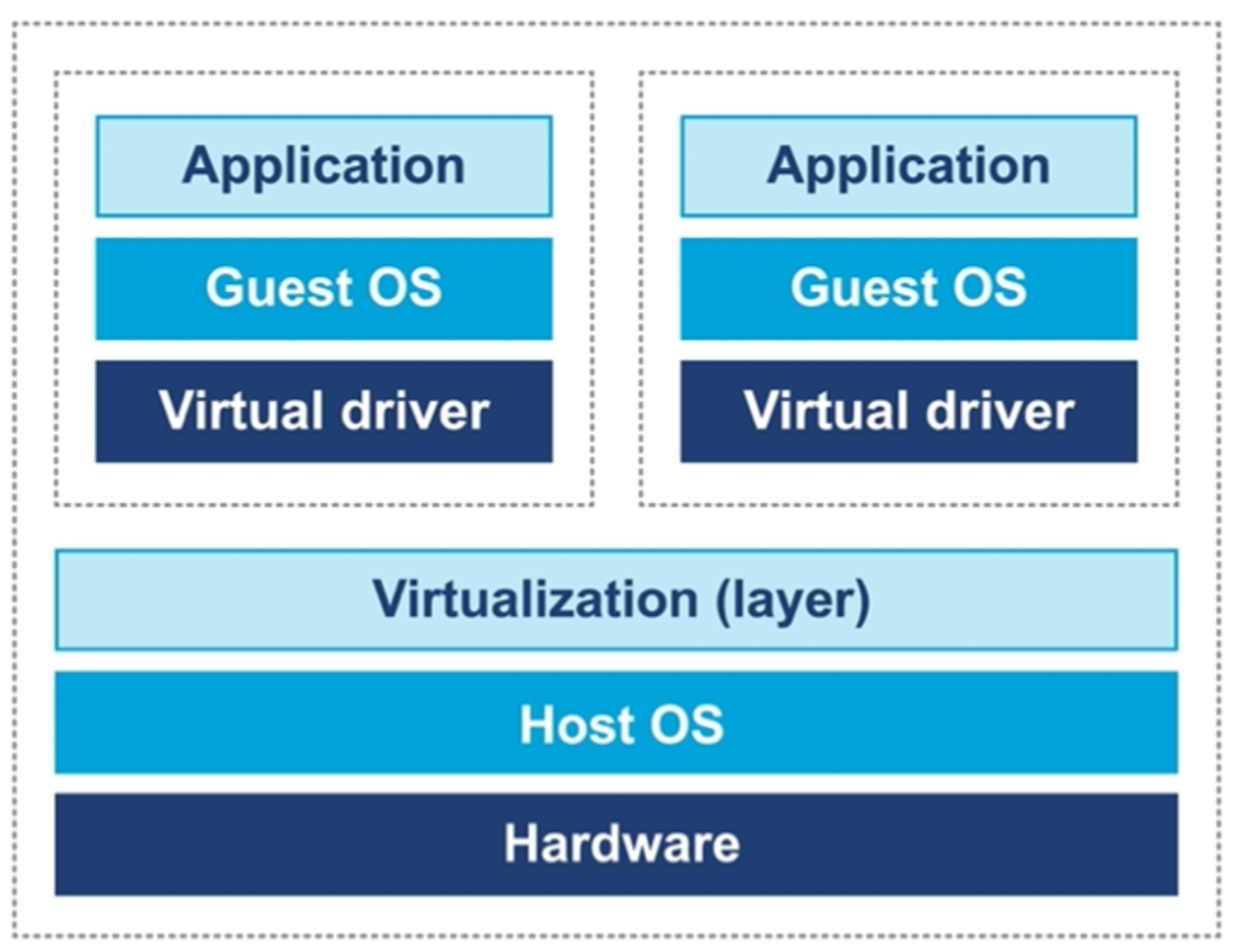
운영체제 가상화
가상화의 특징
•
가상화 OS에서 실행하는 프로그램은 bare metalOS(비 가상화)에서 실행하는 것과 동일해야 한다
•
hypervisor 는 모든 H/W resource access 를 조정해야 한다
•
가상화 오버헤드는 가급적 작아야 하며 실행 시간의 상당 부분을 차지해선 안된다.
그 외에 특징들
•
비가상화 OS는 privileged command 가 모두 동작하지만 가상화에선 이런 권한을 주지 않기 때문에 guestOS가 하드웨어에 직접 엑세스 할 수 없다.
•
따라서 prilileged 를 unprivileged 명령어로 고쳐 써야 한다.
•
context switch 가 발생하는 동안 cache flush(즉 TLB)가 일어나지 않도록 일부 커널의 자료구조를 shadow 해야 한다.
요즘 intel 호환 CPU의 경우 가상화 OS 성능을 높이는 H/W 기능이 탑재된 경우도 있지만, H/W 가 받쳐준다 하더라도 성능 분석이나 튜닝을 복잡하게 만든다
JVM 과 운영체제
JVM 은 OS에 독립적인 휴대용 실행환경을 제공하지만, thread scheduling 같은 기본적인 서비스조차도 하부 OS에 접근해야 한다
•
이런 기능은 native 키워드를 붙여 native method 로 구현한다
◦
C 언어로 작성되어 있다
◦
Java Native Interface(JNI) 라 한다
Object 안에 다음과 같은 native 함수가 있다.
public class Object {
/**
* Constructs a new object.
*/
@HotSpotIntrinsicCandidate
public Object() {}
@HotSpotIntrinsicCandidate
public final native Class<?> getClass();
@HotSpotIntrinsicCandidate
public native int hashCode();
@HotSpotIntrinsicCandidate
protected native Object clone() throws CloneNotSupportedException;
@HotSpotIntrinsicCandidate
public final native void notify();
@HotSpotIntrinsicCandidate
public final native void notifyAll();
public final native void wait(long timeoutMillis) throws InterruptedException;
}
Java
복사
이 method 들은 저수준 플랫폼의 관심사를 처리한다.
편의상 시스템 시간을 조회하는 예시를 들어 설명한다
os::javaTimeMillis() 을 보면 system call 을 호출하는 대표적인 java 코드이다
구현은 c++로 되어있으나 자바의 bridge를 통해 접근한다
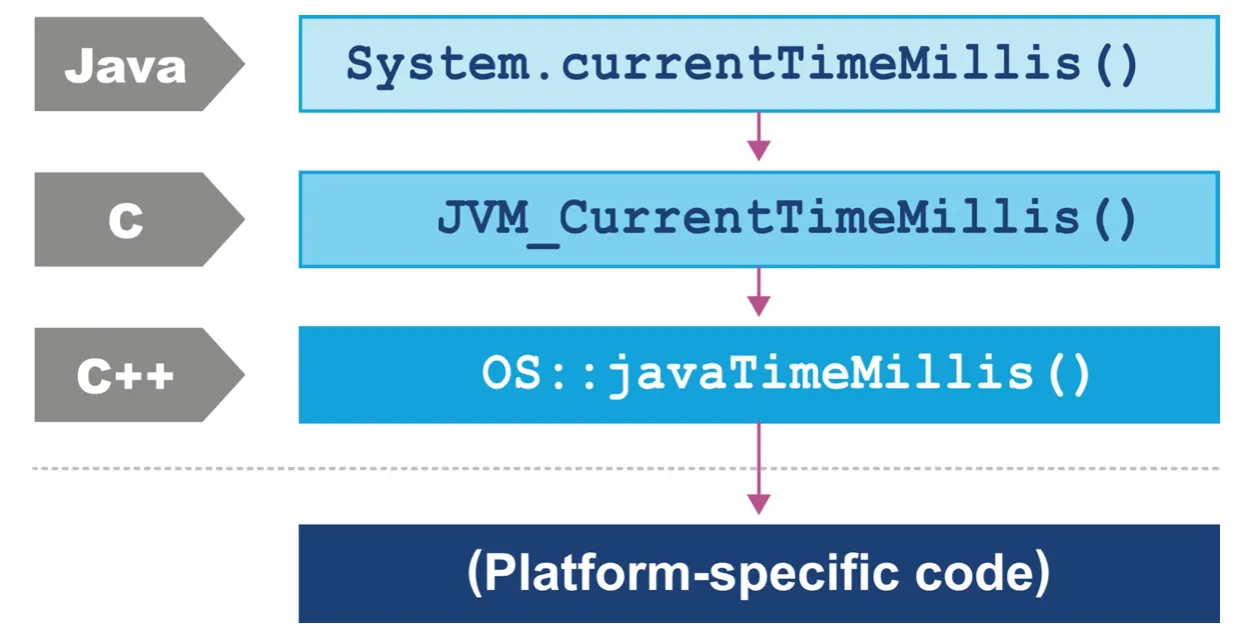
System.currentTimeMillies() 는 JVM_CurrentTimeMillis() 를 호출하고 다시 os:javaTimeMillies() 까지 타고와 플랫폼의 코드를 실행시킨다
결국 openJDK 2 개로 감싼 형태가 된다
