Java collection 의 ArrayList를 살펴보려고 한다. 여기서 다룰 내용은 다른 블로그엔 없는 내용이었으면 한다. 더 좋은 내용은 다른 블로그나 여러 글에서도 충분히 다루기 때문이다.
용어 정리
Collection API를 설명하려면 extends 와 implements 를 구별해서 사용해야 한다.
영어로는 표현이 명확하지만 한글로 표현했을때 inheritance 라는 단어가 둘 다 사용되기 때문에 다소 명확하지 않을 수 있음으로 다음의 두 단어를 사용한다.
•
상속: 두 클래스, 두 인터페이스 간의 inheritance(계승)을 의미한다.
•
구현: 클래스와 인터페이스 간의 inheritance(계승)을 개발하는데 사용되는 키워드이다.
Hierarchy Diagram of ArrayList class in Java
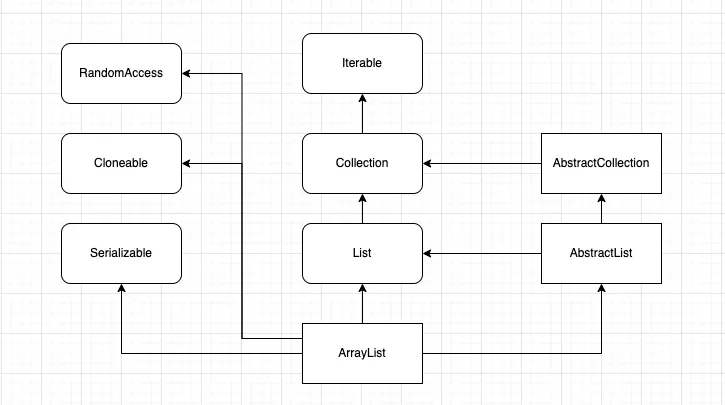
ArrayList의 hierarchy 많은 것을 품고 있다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
Java
복사
가장 먼저 눈이 가는것은 RandomAccess 이다. 구현을 살펴보면 아래와 같다.
Random Access Interface
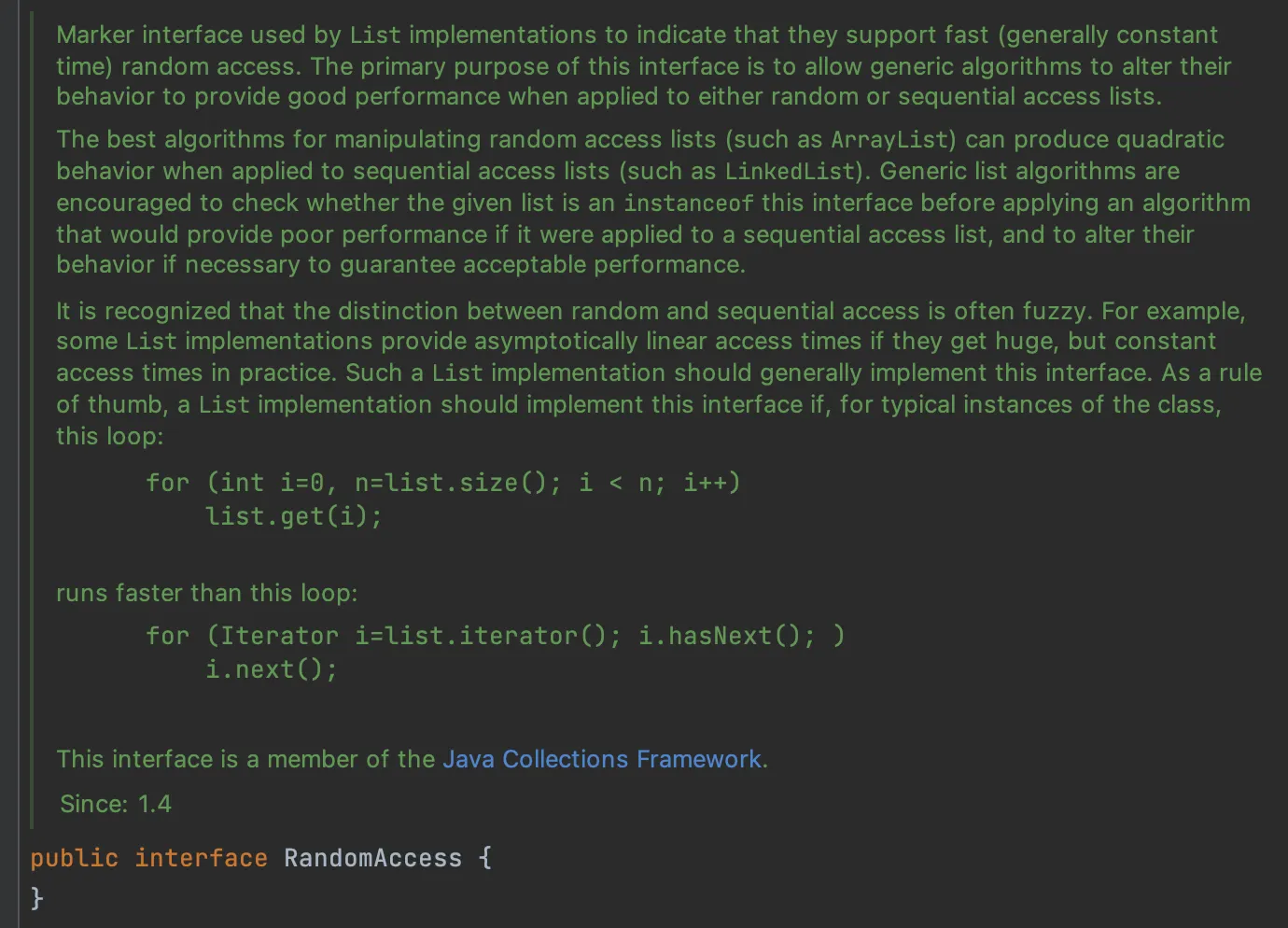
RandomAccess 의 설명이다.
1.
Marker interface: 아무것도 없이 선언만 있는 인터페이스를 의미한다.
2.
Access 하는데 상수 시간을 제공하는 (빠른) 접근을 의미한다.
•
처음 개발을 배울때 random access는 보통 LinkedList와 비교되었다.
•
Index에 기반하여 특정 element에 접근하는 것을 의미한다.
여기서 눈에 띄는건 아래 두 코드 중 list를 index로 접근하는 것이 더 빠르다고 설명하는 부분이다.
for (int i=0, n = list.size(); i < n; i++)
list.get(i);
Java
복사
for (Iterator i = list.iterator(); i.hasNext(); )
i.next();
Java
복사
그래서 벤치마킹을 다음과 같이 수행해봤다.
list 에 랜덤으로 100만개의 숫자를 저장하고 처음부터 마지막 까지 순회하는데 걸리는 시간을 비교해보자.
벤치 마크 결과
Iterator를 사용한 벤치 마크 결과
Result "me.yevgnenll.commons.ListAndIteratorBenchmarking.useIterator":
4.241 ±(99.9%) 11.224 ns/op [Average]
(min, avg, max) = (3.876, 4.241, 4.952), stdev = 0.615
CI (99.9%): [≈ 0, 15.465] (assumes normal distribution)
•
최소 지연시간: 3.876 ns
•
최대 지연시간: 4.952 ns
•
평균 지연시간: 4.241 ns
RandomAccess를 사용한 벤치 마크 결과
Result "me.yevgnenll.commons.ListAndIteratorBenchmarking.useRandomAccess":
1.937 ±(99.9%) 0.161 ns/op [Average]
(min, avg, max) = (1.931, 1.937, 1.947), stdev = 0.009
CI (99.9%): [1.776, 2.098] (assumes normal distribution)
•
최소 지연시간: 1.931 ns
•
최대 지연시간: 1.947 ns
•
평균 지연시간: 1.937 ns
알고리즘 풀때 다 쓰기 귀찮아서 종종 iterator를 사용했었는데 이제 무조건 random access로 순회해야겠다.
Cloneable interface
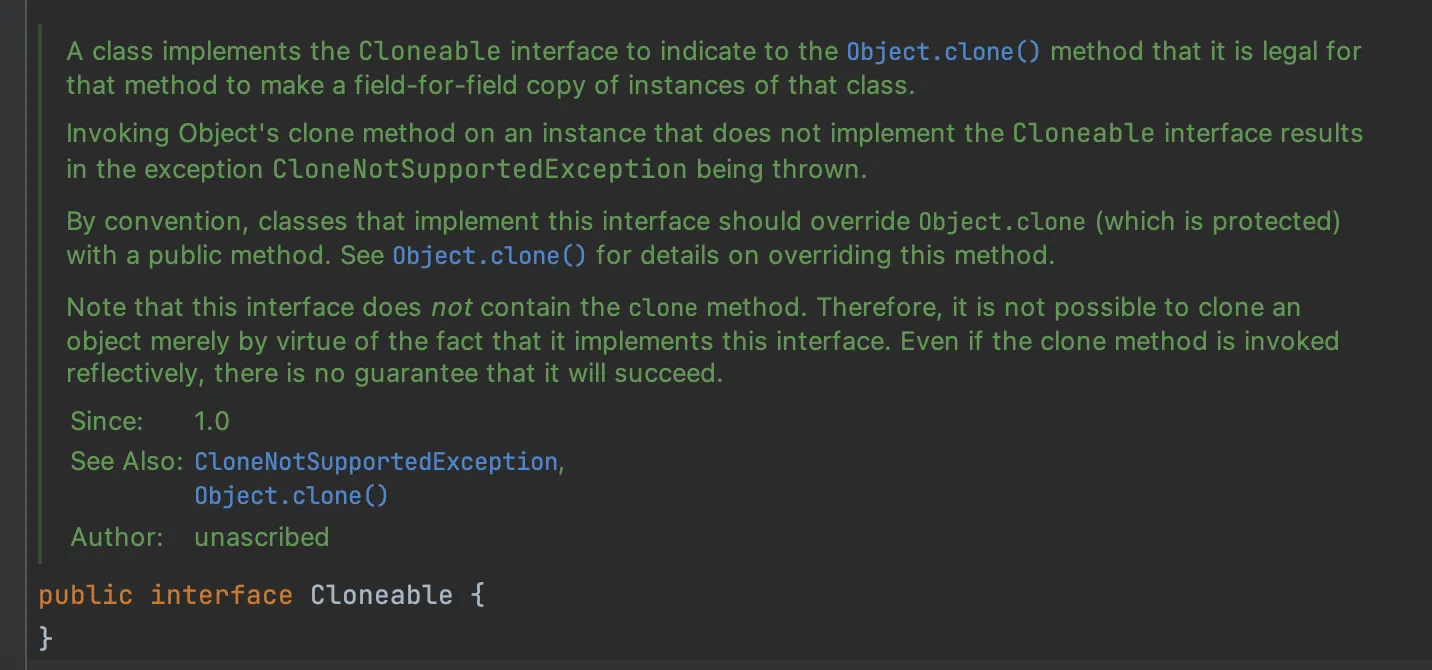
Effective java 13번 챕터에선 신중하게 clone()을 사용할 것을 권고하고 있다.
특징은 다음과 같다.
1.
Object.clone() 함수를 호출하는데 적법하기 위해 이 interface를 구현해야 한다.
2.
Cloneable 을 구현하지 않은 instance에 clone() 을 호출하면 CloneNotSupportedException 을 반환한다.
3.
Cloneable은 client를 위한 것이 아닌, super class의 protected 함수를 동작하도록 하는데 있다.
@HotSpotIntrinsicCandidate
protected native Object clone() throws CloneNotSupportedException;
Java
복사
Object의 clone() 은 JNI로 정의되어 있다.
Clone을 구현하고자 한다면 super.clone() 을 먼저 호출하고 각 필드를 복사하도록 하면서, 재귀적으로 호출되지 않도록 해야한다.
보통 배열 복제가 아니라면 사용하지 않도록 하는것이 좋지만, 특징과 주의할 점을 정확히 이해하고 사용한다면 괜찮다.
Clone 구현의 필수 조건
x.clone() != x
x.clone().getClass() == x.getClass()
x.clone().equals(x)
Java
복사
이 3가지 모두 true가 되도록 clone을 구현해야 한다.
JDK에선 이를 강제적인 요구사항으로 두지 않는다. 그래서 clone의 구현과 사용은 신중해야 한다.
Kotlin에서 data class 에 한하여는 compiler가 생성해주는 clone() 이 있다. kotlin의 data class 에서 copy는 shallow copy이므로 사용에 주의를 해야한다.
ArrayList의 clone() 구현
/**
* Returns a shallow copy of this {@code ArrayList} instance. (The
* elements themselves are not copied.)
*
* @return a clone of this {@code ArrayList} instance
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
Java
복사
ArrayList 의 clone 을 열어보면 이와 같이 구현되어 있다.
1.
ArrayList 의 super.clone 을 호출한다.
2.
새로운 변수에 Arrays.copyOf 를 호출하여 배열 복사를 수행한다.
3.
v.modCount 는 0으로 만든다.
•
ArrayList 는 동시성을 보장하지 않는다.
•
하지만, 동시성이 깨지는 이슈를 파악하고 exception 을 일으키는데 이때 사용되는 것이 modCount 이다.
•
다음 포스팅에서 자세히 다룰 예정이다.
4.
반환 타입이 Object 이지만, 따로 형변환을 하지 않아도 된다. 이는 Java가 convariant이기 때문이다.
Serializable interface
역시 marker interface 로 network를 통해 ArrayList를 전송할 것을 대비하여 사용되었다.
Serializble도 clone 처럼 정확히 알고 사용해야 하며, 그렇지 않다면 사용하지 않는편이 더 좋다.
Jackson library가 serialzible을 통해 구현되었으며 취약점이 되므로 되도록 사용을 권장하지 않는다.
하지만, JDK와 같은 라이브러리를 개발해야 한다면 알아두어야 할 필요가 있으며, 내 블로그엔 이미 Serializable에 대해 다룬 글들이 있으므로 이로 대체한다.








ArrayList 가 제공하는 기능들
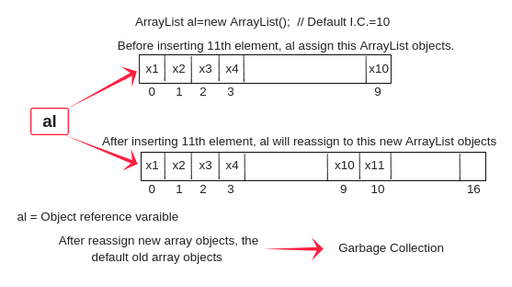
가변길이, Resizable array
ArrayList 도 내부적으로 배열을 갖고 있으며, 그 길이는 int 최대치 만큼 증가한다.
여기에 성능에 관련한 걱정이 있을 수 있지만, 상당히 잘 구성되어 있다.
내부적으로 System.arrayCopy 라는 함수를 사용하는데 배열 복제에 드는 비용이 이 아닌 이다.
이것 때문에 커널까지 열어봤는데 이와 관련된 포스팅은 ArrayList 이후에 하겠다.
Index 기반의 구조
ArrayList 는 RandomAccess 를 구현하면서, index로 접근할 수 있도록 설계되었다.
list.get(0) 을 호출하면 가장 첫 번째 element를 반환한다.
중복 요소 저장 가능
저장시에 중복 여부를 관찰하지 않는다. add() 로 호출하면 내부 bucket에 무조건 저장된다.
Null 요소
List<Integer> list = new ArrayList<>();
list.add(null);
Java
복사
위의 코드와 같이 null 이 저장 가능하다. 이는 Integer[] 에 무엇이 저장될 수 있는지 고민해보면 알 수 있다.
저장 순서대로 정렬
list.add(object); 를 호출하는 순서대로 정렬된다.
만약 저장된 element로 정렬을 원한다면, 해당 instance 는 내부적으로 comparable 이 구현되어야 한다.
Heterogeneous object
Heterogeneous 가 허용된다는 문장이 있다. 다른 종류의 object가 저장된다고 이해할 수 있다.
ArrayList list = new ArrayList<String>();
list.add("a");
list.add(1); // OK
list.add(new Object()); // OK
Java
복사
Heterogeneous 의 예시에 해당하는 코드
ArrayList 에 별다른 type을 generic으로 기입하지 않아 compile time에서 type이 지워졌다면 이러한 일이 가능하다. 따라서 collection, map 과 같은 자료구조를 사용할 때는 generic에 대한 이해가 필요하다.
ArrayList<String> list = new ArrayList<String>();
list.add("a");
list.add(1); // compilation error
list.add(new Object()); // compilation error
Java
복사
Type을 명시하여 compile time에서 error을 확인할 수 있다.
그런데 generic으로 선언했다 하더라도 다음과 같은 코드를 작성하면 runtime에서 error 없이 실행된다.
ArrayList<String> list = new ArrayList<String>();
list.add("a");
Method[] methods = List.class.getMethods();
for(Method m : methods) {
if(m.getName().equals("add")) {
m.invoke(list, 1);
break;
}
}
System.out.println(list.get(0));
System.out.println((Object) list.get(1));
Java
복사
Java의 reflection을 이용해 Heterogeneous 를 사용한 사례
이런 위험한 코드를 누가 작성하겠냐고 생각할 수 있지만, Hibernate와 같은 곳에서 사용한다.
동기화 (Synchronized)
ArrayList 는 synchronized를 지원하지 않는다. 즉, multi-thread에서 동일한 ArrayList 를 사용할 수 있다.
성능
ArrayList 를 다루는 것은 성능이 느려질 수 있다. 만약 10만개의 elment가 있는 ArrayList 에서 10번째 element를 제거했다고 가정하자.
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}
/**
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
es[size = newSize] = null;
}
Java
복사
저장된 element를 index로 삭제하면 왼쪽으로 한 칸씩 이동한다.
System.arraycopy 가 성능이 좋은건 사실이다. JDK → Linux kernel 쪽으로 내려가면 어셈블리에서 memmove 를 사용한다. for 와 같은 반복문으로 복사하는 것 보단 훨씬 빠르지만, 컴퓨터에서 이와같은 연산을 하는건 역시 부담을 준다.
대체로 System.arraycopy 는 로 본다.
이후 살펴볼 내용은 ArrayList 에서 중요한 코드를 열어보려고 한다.
특히, 중요하게 살피려는 부분은 grow() 에 해당하는 부분이다.
별다른 설정을 하지 않는다면, ArrayList 는 내부적으로 길이 10인 배열을 선언하고, 그것을 2배씩 늘려나간다. 어떻게 이러한 과정을 갖는지 살펴보고자 한다.