
분산 시스템을 설계할 때는 CAP 정리(Consistency, Availability, Partition Tolerance theorem)를 이해하고 있어야 한다. (면접에서 이 질문 나왔을때 엄청 당황했다.)
하지만, 이 개념은 매우 모호하며 Couchbase의 경우 CA로 등재되었다가 CP로 수정되기도 했다.
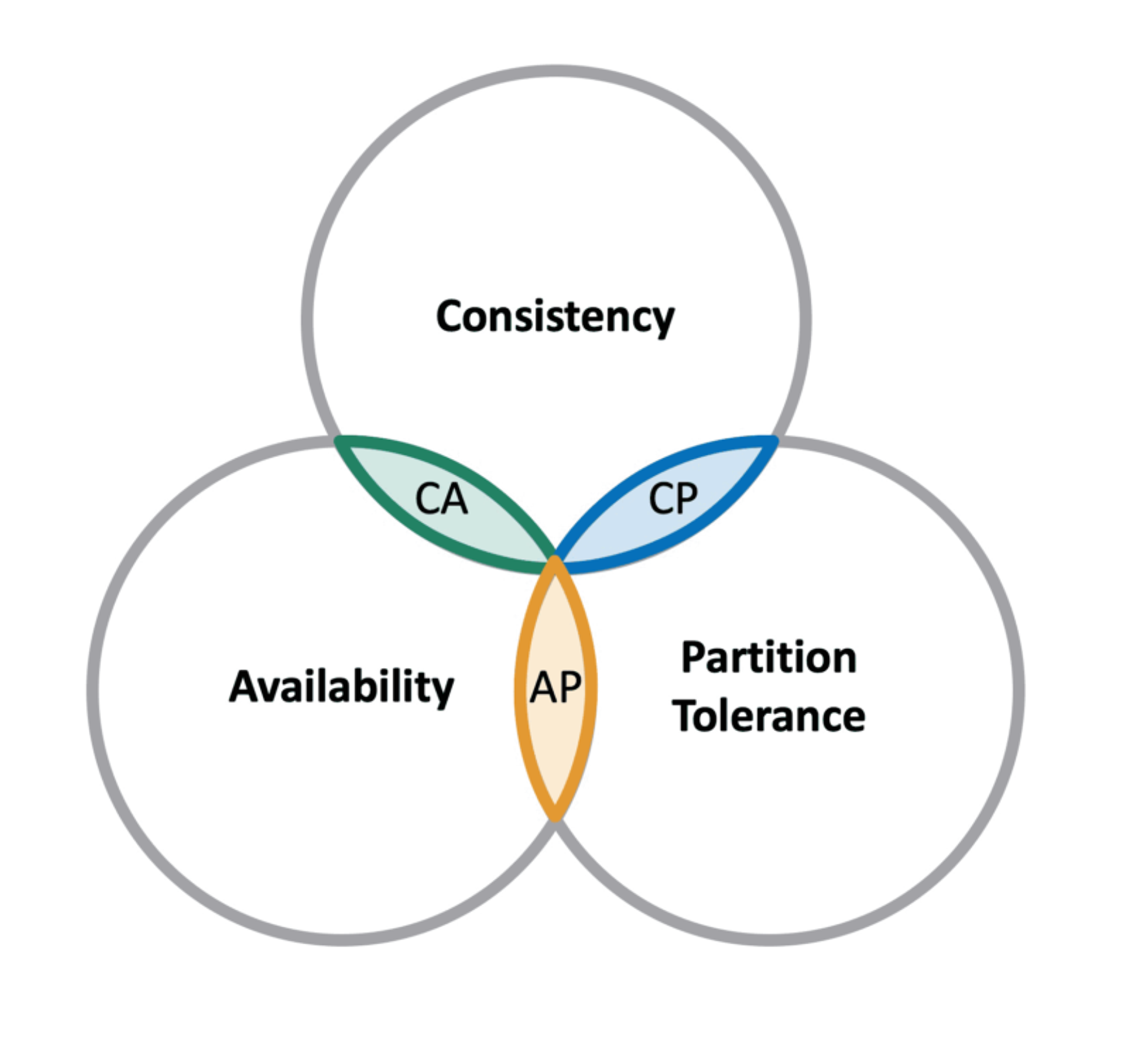
CAP 정리
다음의 세 가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것이 불가능하다.
•
일관성(Consistency)
•
가용성(Availability)
•
파티션 감내(Partition tolerance)
CAP는 원래 Database 에서 trade-off 에 대한 논의를 시작하려는 목적으로 정확한 정의 없이 경험 법칙으로서 제안 되었다.
여기서 말하는 분산 시스템은 Database cluster를 의미하는 것이며, 하나의 main-sub 부터 leaderless 구조까지 다양한다.

3개 중 2개를 골라야 한다.
그런데 이와 같이 생각하면 오해의 소지가 있다.
네트워크 분단은 좋든 싫든 발생한다.(장애가 없는 시스템이 있을까?? 제발 내가 만든 시스템이 장애가 없으면 좋겠다ㅜㅜ) 네트워크가 올바르게 동작할 때는 시스템이 일관성(선형성)과 완전한 가용성을 모두 제공할 수 있다.
CAP 각각은 서로 동등하지 않다. 마치 2개만 고르면 되는것 처럼 보이지만 P는 반드시 선택되어야 한다.
데이터 일관성 (Consistency)
분산 시스템에 접속하는 모든 client 는 어떤 노드에 접속했느냐에 관계없이 언제나 같은 데이터를 보게 되어야 한다.
Query Q에 대해서 어떤 노드이건 관계없이 동일한 Answer A를 반환한다.
가용성 (Availability)
분산 시스템에 접속하는 client 는 일부 node 에 장애가 발생하더라도 항상 응답을 받을 수 있어야 한다.
분산 시스템에서 Query Q를 받았을 때 언제나 응답 Answer A를 반환합니다.
이는 고가용성(High-availability)과 혼동하지 말아야 한다. 많은 양의 쿼리 응답을 제공하는 것이 아니라, 응답을 거부하지 않는것을 의미한다.
파티션 감내(Partition tolerance)
파티션은 두 node 사이에 통신 장애가 발생하였음을 의미한다.
“파티션 감내라고 해서 파티션이 있어도 시스템이 동작한다.” 라는 의미가 아니다. 네트워크 단절등으로 인해 cluster안에 존재하는 node 간 통신이 일어나지 않는다 하더라도 계속 응답이 있음을 뜻한다.
CAP 정리는 이들 가운데 어떤 두 가지를 충족하면 나머지 하나는 반드시 희생되어야 한다는 것을 의미한다.
Trade off 비교
•
CP 시스템
◦
일관성(Consistency)과 파티션 감내(Partition-tolerance)를 지원하는 저장소
◦
가용성을 희생한다.
◦
즉, 특정 시간대엔 임의의 Q에 대해 응답 A가 반환되지 않는다.
◦
A를 받는 모든 Q에 대해 동일한 A를 반환받는다.
•
AP 시스템
◦
가용성(Availability)과 파티션 감내(Partition-tolerance)를 지원하는 저장소
◦
데이터 일관성을 희생한다.
◦
즉, 특정 시간대엔 동일한 Q에 대해 값이 다른 A(이전 버전)를 반환한다.
•
CA 시스템
◦
일관성(Consistency)과 가용성(Availability)을 지원하는 저장소
◦
파티션 감내는 지원하지 않는다.
◦
하지만, 네트워크 장애는 피할 수 없는 일로 여겨지므로, 분산 시스템은 반드시 파티션 감내가 가능하도록 설계되어야 한다.
즉, 결과적으로 CA 시스템은 존재하지 않는다.
이러한 정의만으론 이해가 어렵다. 몇 가지 구체적인 사례를 살펴본다.
•
분산 시스템에서 데이터는 보통 여러 node 에 복제되어 보관한다.
•
3대의 복제 node n1, n2, n3 에 데이터를 복제하여 보관한다고 가정하자.
이상적인 상태
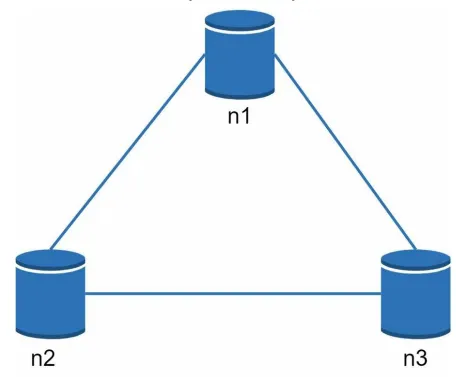
파티션이 된다는 것은 n1과 n2에 존재하는 집합 A가 n3에 존재하지 않는 상황을 의미한다.
이상적인 환경이라면 n1에 기록된 데이터는 자동으로 n2, n3 에 복제된다.
데이터 일관성(어느 node나 동일한 데이터)과 가용성(언제, 어디로 호출해도 항상 응답을 제공)도 만족된다.
실세계의 분산 시스템
분산 시스템은 파티션 문제를 피할 수 없다.
만약 파티션 문제가 발생할 경우 C(일관성)와 A(가용성) 중 하나를 선택해야 한다.
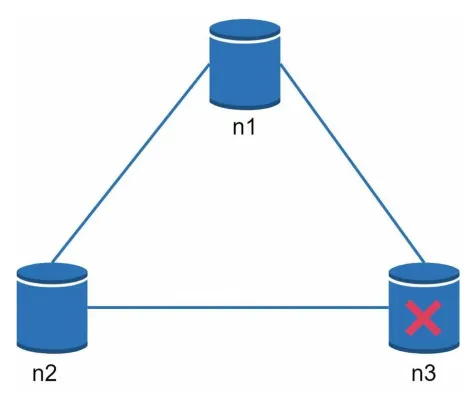
n3에 장애가 발생하고 n1, n2 와 통신이 불가능한 상황
•
n1과 n2에 기록한 데이터는 n3 로 저장되지 않는다. (파티션 발생)
•
n3에 기록된 데이터중 n1과 n2로 전달되지 않는 데이터가 있다면 n1, n2는 오래된 사본을 갖는다. (일관성 깨짐)
여기서 가용성(Availability)을 ‘포기’하고 일관성을 선택하면(CP)
일관성 유지를 위해 n1, n2 에 쓰기 작업을 중단시켜야 한다.
일관성은 유지되지만, 가용성(일부 노드에 장애가 발생해도 응답한다)이 만족되지 않는다.
그래서 일관성과 가용성은 동시에 만족할 수 없다.
요약
•
일관성이 필요 없는 application 은 네트워크 문제에 더 강하다.
◦
이런 통찰력이 2000년에 Eric Brewer 가 CAP 정리로 이름을 붙여 널리 알려졌다. 물론 1970년대에도 분산 데이터베이스 설계자들에게 알려져 있었다.
•
그래서 AP, CP 는 존재하지만 CA는 존재할 수 없다.
적용
MongoDB 는 CAP 로 보면 어떻게 될까?
MongoDB 는 NoSQL DBMS로 BSON(Binary JSON)을 저장한다.
용도로는 Big data, Sharding을 적용한 real-time application으로 사용한다.
CAP 정리로는 CP에 해당한다.
•
MongoDB는 single-master system 으로 각각의 replica 는 오로지 하나의 primary node 를 갖는다.
•
Upsert operation 을 받는 단 하나의 primary node 가 있고, 나머지는 복제본이다.
◦
Primary node의 로그를 읽어 2차 노드에 복제한다.
◦
Client는 primary node 에서도 읽지만, 2차 노드에서 읽는다.
•
1차 Primary node 가 사용 불가능한 상태가 되면, 가장 최신의 로그가 복제된 2차 노드가 primary node 가 된다.
•
모든 2차 노드가 새로운 master를 따라잡을 경우(복제가 완료된 경우) cluster 가 다시 사용 가능해진다.
◦
Client 는 이 따라잡는 간격 중에 쓰기 요청을 할 수 없다. → Availability를 포기한다.
Cassandra 의 CAP 정리.
Apache cassandra 는 NoSQL DBMS 이다.
분산 네트워크에 데이터를 저장할 수 있도록 허용하는 Wide-Column Database 로 MongoDB와는 다르게 masterless 아키텍처를 보유하여 다수에 장애 가능성이 존재한다.
CAP로는 AP에 해당한다.
•
가용성, 파티선 허용을 제공하지만 일관성은 제공하지 못한다.
•
Master node 가 없으므로 모든 노드는 쓰기와 가용성을 보장하며, 언제, 어느 노드라도 Upsert가 가능하다.
•
그러나 consistency 는 최종적 일관성(Eventual consistency)을 보장하여 노드간 불일치를 가능한 빠르게 해소하고자 한다.
•
만약 네트워크 파티셔닝 이슈로 인해 inconsistent 인 상황이 발생하면 빠르게 노드의 차이를 따라잡는 “repair” 라는 기능을 제공한다.
•
그러나 이 기능은 system performance를 고려할 때 trade off 가 존재하므로 따져볼 필요가 있다.
MySQL은 CP에 해당한다.
MySQL의 CAP 정리가 가장 햇갈렸다. 하지만 중요한 사실 하나를 먼저 명시하자.
CAP는 분산 데이터베이스 시스템이다. 따라서 하나의 DB node가 아닌 n(n > 1)개인 상황에서 고려해야 한다.
Master node가 분산되어 있고, 네트워킹을 통해 동기화 된다.
이때 분할이 발생하면, 읽기 요청은 일관성을 유지한다.
모든 읽기 요청이 동일한 데이터를 받으나, write에 대해 가용성이 희생된다.
