
이전에 작성했던 코드를 복기하다가 당시 정확하게 개념을 숙지하지 않고 넘어간 자료구조가 있다. java nio에 있는 ByteBuffer 이다. 이 마법을 나에게 주술에서 과학으로 만들기 위해 정리한다.
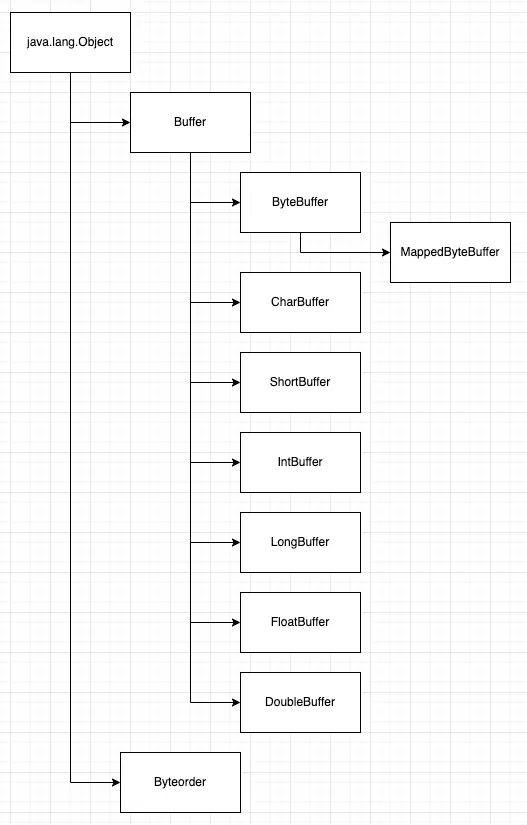
Buffer의 계층 구조
먼저 Buffer 와 Byteorder 로 나뉘어 지는 계층을 갖고 있다. 여기서 Buffer 의 ByteBuffer 에 대해 알아볼 것이다. 하지만, 이것을 정확하게 알기 위해서 Buffer 에 대한 이해도 필요하다.

Buffer 란?
하나의 데이터 형태를 저장하는 container 이다.
버퍼는 시작과 끝이 있는 일직선 모양의 데이터 구조를 갖고 내부적으로 자신의 상태 정보를 4가지 primitive type 속성에 저장한다.
자바에선 이 4가지 속성을 편리하게 다루기 위한 API를 제공한다.
따라서 배열보다 훨씬 사용하기 편하고 강력한 기능을 갖고있다.
ByteOrder
Byte는 읽는 순서에 따라 BIG_ENDIAN, LITTLE_ENDIAN 으로 나뉜다
ByteBuffer에 별다른 옵션을 주지 않는다면 BIG_ENDIAN 이 사용되도록 설정되어 있다.
Buffer의 4가지 기본 속성
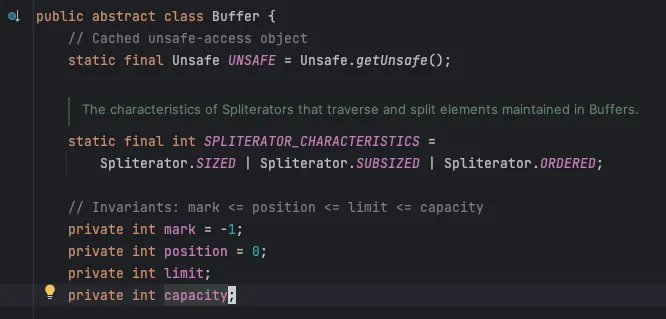
버퍼를 쉽게 이해하려면 설명보다 클래스에 대해 구체적으로 알아볼 필요가 있다.
Buffer의 네 가지 속성 mark는 -1을 초기값으로 갖는다.
속성 | 설명 |
position | 버퍼에서 읽거나 쓸 위치 값이다.
Limit 보다 큰 값을 가질 수 없다. Limit과 같은 값이면 더 이상 읽거나 쓰지 못한다.
만약 limit을 초과하면 RuntimeException이 발생된다. |
limit | 버퍼에서 읽거나 쓸 수 있는 한계 값이다.
버퍼에서 실제 어디까지 사용할지 지정하는 속성으로 capacity 보다 클 수 없다. |
capacity | 버퍼의 크기를 나타낸다. → 메모리의 크기버퍼를 생성할 때 parameter 주어진다.
한번 생성되면 크기를 변경할 수 없으므로 버퍼의 크기는 신중한 결정이 필요하다. |
mark | mark() 를 통해 현재 position을 표시할 때 사용한다. reset()으로 mark 에 돌아갈 수 있다. |
이 네 가지 속성에서 mark 를 제외하곤 모두 양수만 갖는다.
capacity 몇 개의 데이터를 저장할 수 있는지 나타낸다.
LongBuffer 의 경우 capacity를 100으로 정했다면, 이 버퍼에 100개의 long을 넣을 수 있다.
속성의 관계는 아래와 같다.
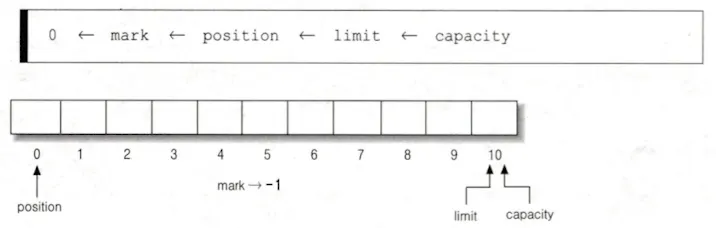
capacity, limit 이 10인 버퍼
Buffer 를 이용한다는 뜻은 이와 같은 자료구조에서 position, limit, mark 속성을 제어하며 버퍼를 이용하는 것이다.
public abstract class Buffer {
// getter
public final int poisition();
public final int limit();
public final int capacity();
// setter
public final Buffer position(int newPosition);
public final Buffer limit(int newLimit);
// manipulate mark
public final Buffer mark();
public final Buffer reset();
public final int remaining();
public final boolean hasRemaining();
public abstract boolean isReadOnly();
}
Java
복사
대표적인 Buffer의 API들
버퍼 계열의 클래스들이 공통적으로 사용하기 때문에 overriding을 막기 위해 final로 선언되어 있다.
Getter, setter가 있고, mark로 position을 mark에 저장하며 사용한다.
저장된 mark로 나중에 이동할 때는 reset() 을 호출하면 돌아갈 수 있다.
mark() 를 호출하지 않고 reset() 을 호출한다면 InvalidMarkException 를 반환한다.
remaining() 은 limit - position 이다. 현재 position을 기준으로 buffer에서 읽을 수 있는 데이터가 몇 개 남은것인지 확인할 때 사용한다.
isReadOnly 는 버퍼가 읽기 전용인지 아닌지 확인하는데 사용한다.
버퍼에서 데이터를 읽고 쓰기
Buffer에서 제공하는 API는 크기 4가지 부분으로 나눌 수 있다.
1.
상대적 위치를 이용해서 1byte 읽고, 쓰기
2.
절대적 위치를 이용해서 1byte 읽고, 쓰기
3.
배열을 이용해서 한꺼번에 많은 데이터를 읽고 쓰기
4.
버퍼 자체를 parameter로 받아 쓰기
상대적 위치를 이용해서 1byte씩 읽고 쓰기
public abstract byte get();
public abstract ByteBuffer put(byte a);
Java
복사
상대적 위치로 읽고 쓰기
상대적 위치라 함은 버퍼의 현재 position을 기준으로 데이터를 읽어오는 위치를 결정한다.
ByteBuffer buf = ByteBuffer.allocate(10);
byte b = buf.get();
Java
복사
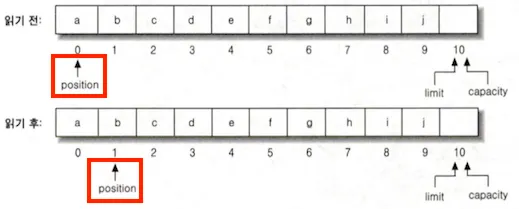
get() 메소드로 버퍼에서 데이터 읽기
위 그림은 get() 을 이용해 버퍼에서 데이터를 읽기 전과 읽기 후의 position 변화를 나타낸다.
읽으면서 position이 1씩 증가하는 것을 볼 수 있다.
그러나 limit, capacity 의 값은 변경되지 않는다.
ByteBuffer buf = ByteBuffer.allocate(10);
but.put((byte) z);
Java
복사
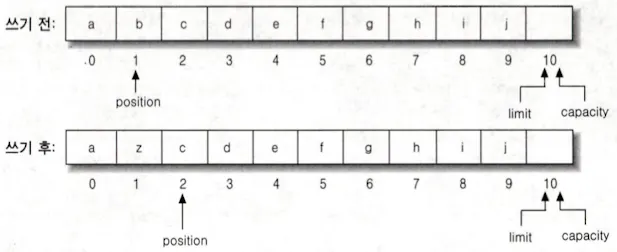
put() 메소드로 버퍼에 데이터 쓰기
상대적 위치로 1번 position에 쓴다 (b → z) 그럼 position이 1 증가한다.
역시 limit, capacity는 변화하지 않는다.
만약 position이 10인 상태에서 get(), put() 을 호출한다면 BufferUnderflowException, BufferOverflowException 이 발생한다.
따라서 읽고 쓰기 전에 position과 limit을 비교하여 buffer에 읽고 쓰기를 수행해야 한다.
절대적 위치를 이용해서 1byte 읽고 쓰기
public abstract byte get(int index);
public abstract ByteBuffer put(int index, byte b);
Java
복사
앞선 방법은 현재 position에 기반하지만, 현재는 index를 직접 지정하여 어느 위치에 읽고, 쓸 것인지 지정한다.
ByteBuffer buf = ByteBuffer.allocate(10);
byte b = buf.get(5);
Java
복사
5번 위치를 읽어낸다.
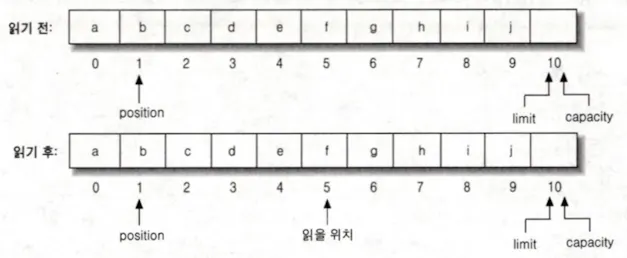
위 코드를 실행하면 5번 위치의 f 를 읽어 변수 b에 할당한다.
역시 limit을 넘어가면 IndexOutOfBoundsException을 발생하기 때문에 limit과 비교하여 이용해야 한다.
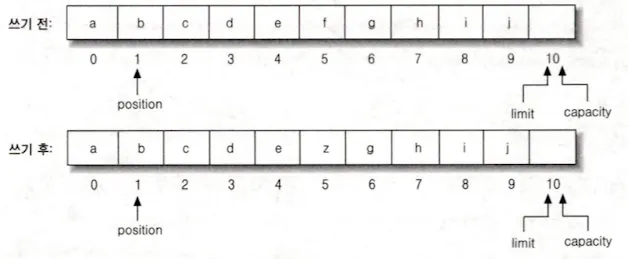
pub(index, b) 로 버퍼에 데이터 쓰기
위 버퍼는 지정한 위치에 데이터를 쓰는 그림이다. 읽고 쓰고 난 뒤에 position의 변화가 없다.
배열을 이용해서 한꺼번에 데이터를 읽고 쓰기
물론 앞선 방법을 통해 for 와 같은 반복문으로 데이터를 bulk로 읽어올 수 있다.
하지만, 이미 알맞은 API를 제공하니 이 방법을 살펴보자.
ByteBuffer buf = ByteBuffer.allocate(10);
byte[] bulk = new byte[5];
ByteBuffer b = buf.get(bulk);
Java
복사
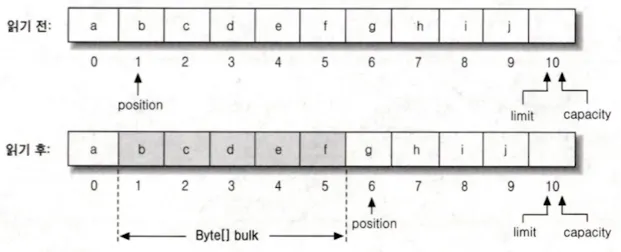
버퍼의 데이터를 배열로 읽어오기
현재 position이 1이기 때문에 여기서 5개의 element를 읽어온다.
반대로 bulk로 저장하는 방법은 아래와 같다.
ByteBuffer buf = ByteBuffer.allocate(10);
byte[] bulk = new byte[5];
buf.put(bulk);
Java
복사
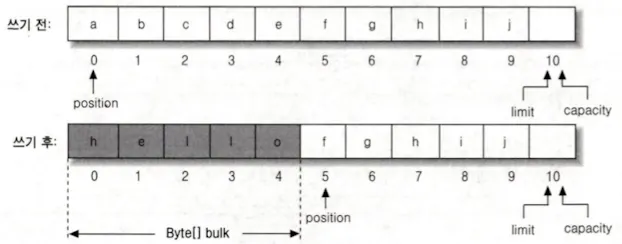
실제로 사용한 코드
public static long toLong(byte[] value) {
int pad = Long.BYTES - value.length;
byte[] data = null;
if (pad > 0) {
data = new byte[Long.BYTES];
System.arraycopy(value, 0, data, 0, value.length);
} else {
data = value;
}
ByteBuffer buf = ByteBuffer.wrap(data);
return buf.getLong();
}
Java
복사
Byte의 배열을 입력받아 Long으로 반환하는 코드이다.
여기서 보면 ByteBuffer의 wrap 이라는 함수를 볼 수 있다.
public static ByteBuffer wrap(byte[] array) {
return wrap(array, 0, array.length);
}
public static ByteBuffer wrap(byte[] array, int offset, int length) {
try {
return new HeapByteBuffer(array, offset, length);
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}
Java
복사
HeapByteBuffer 는 ByteBuffer 를 상속하였다. 즉, 앞서 살핀 코드들이 모두 존재한다.
다시말해 배열을 받아 Buffer를 만드는 것과 같다.
위 toLong 의 테스트 코드는 아래와 같다.
@Test
void positiveLongNumber() {
byte[] bytes = new byte[] {100};
// = 01100100 00000000 00000000 00000000 00000000 00000000 00000000 00000000
// = 64 00 00 00 00 00 00 00
assertThat(Bytes.toLong(bytes)).isEqualTo(7205759403792793600L);
}
Java
복사
100을 2진수로 변경하면 와 같다.
Long은 8byte 자료구조이므로 하나의 Long을 선언하면 64bit의 공간을 얻는다.
별다른 옵션을 주지 않았기 때문에 BIG_ENDIAN 이 사용된다.
따라서 100이 있는 첫 8비트를 포함해 나머지 8비트씩 7개는 아래와 같이 셋팅된다.
01100100 00000000 00000000 00000000 00000000 00000000 00000000 00000000
Java
복사
이 값을 16진수로 나타내면 아래와 같다.
64 00 00 00 00 00 00 00
Java
복사
그리고 이 값을 10진수로 계산하면 아래와 같다.
7205759403792793600L
Java
복사
2진수 → 10진수 계산은 아래와 같다.
