


컨테이너를 모니터링하고 실패하면 다시 시작하는 방법을 배울 것이다. 컨트롤러가 파드를 관리하지 않는 한 새로운 컨트롤러로 대체 되지 않는다. Replica set 으로 pod 를 관리하면 반드시 n 개의 pod 가 실행됨을 보장하는데 이에 대해서 자세히 다룬다.
4.1 파드를 안정적으로 유지하기
컨테이너 주 프로세스에 crash 가 발생하면 kublet 은 컨테이너를 다시 시작한다
crash 가 발생한 container 는 자동으로 다시 시작하고, OOM 와 같은 GC 문제에 의한 오류의 경우 process 를 죽이고 다시 실행한다.
하지만 무한 루프와 같은 application 문제로 인한 오류는 해결해주지 못하기 때문에 모니터링 도구가 필요하다
Introducing liveness probes
k8s 는 probe 를 통해 container 가 살아 있는지 3가지 메커니즘으로 확인할 수 있다.
1.
지정한 IP, port 로 HTTP GET 을 보내어 2xx, 3xx 인지 확인한다
•
오류 응답 코드이면 실패로 간주한다.
2.
TCP 소켓 probe 는 container 의 지정된 port 에 TCP 연결을 시도한다.
•
연결되면 이면 성공
3.
Exec 는 명령의 종료 상태 코드가 0인지 확인한다.
HTTP 기반 liveness probe 생성 (Creating an HTTP-based liveness probe)
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luksa/kubia-unhealthy # 실패를 반환할 container 이미지
name: kubia
livenessProbe:
httpGet:
path: / # probe 가 요청해야 하는 경로
port: 8080 # probe 가 연결해야 하는 포트
YAML
복사
livenessProbe 를 통해서 정의한다.
예제에는 문제가 있는 container 이미지를 사용해 실패하면 재시작 하는지 확인한다
동작 중인 liveness probe 확인
kubectl get po kubia-liveness
YAML
복사

RESTARTS 는 pod 가 몇번 재실행 되었는지 반환한다
kubectl describe 로 컨테이너가 다시 시작된 이유를 파악할 수 있다.-
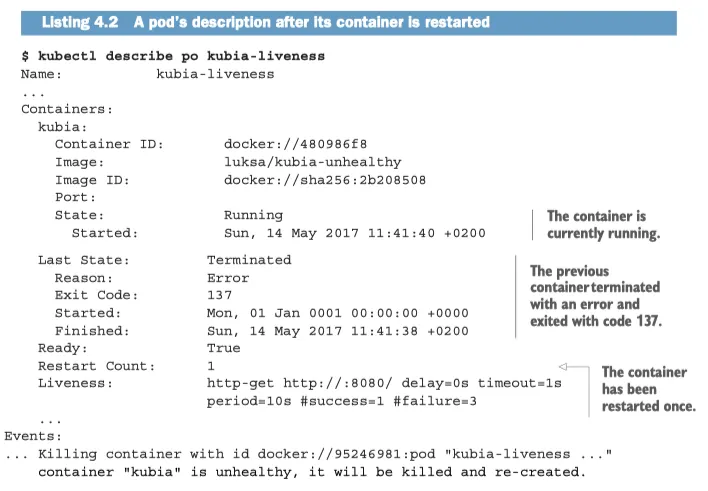
•
Restart Count 를 확인해보면 이전에 컨테이너가 몇번 다시 실행된 것인지 확인할 수 있다.
•
Exit Code 는 137 인데 의 결과이다.
◦
x 는 9인데 9는 SIGKILL 이며 프로세스가 강제로 종료됐음을 의미한다.
Liveness probe 추가 속성 설정 (Configuring additional properties of the liveness probe)

•
delay = 0s 는 container 가 시작된 후 바로 probe 가 시작된다는 것을 의미한다.
•
timeout = 1s 이므로 컨테이너는 1초 안에 응답해야 한다.
•
period = 10s 컨테이너가 10초마다 probe 를 수행한다.
•
failure=3 3번 연속 실패 하면 container 는 재실행 된다.
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luksa/kubia-unhealthy
name: kubia
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 15
YAML
복사
initialDelaySeconds 를 통해 초기 15초간은 probe 가 확인을 안하도록 할 수 있다.
이런 설정을 해두지 않으면 app 이 실행되자 마자 restart 가 1인 경우가 발생할 수 있다.
종료코드가 137 또는 143인 경우 이 가능성을 의심해 봐야 하낟.
효과적인 liveness probe 생성 (Creating effective liveness probes)
liveness probe 가 확인해야 할 사항
위의 예제는 서버가 단순이 응답하느냐 아니냐를 검사한다. 여기에 health check 와 같이 내부의 구성 요소들이 살아 있는지 확인하는 API 를 연동하면 체크가 더 효율적이게 된다.
그런데 DB 가 살아 있는지 와 같은 application 의 범위를 벗어난 component 를 확인하는 것은 좋지 않다.
DB가 죽었는데 web server pod 를 다시 실행한다고 해서 달라질 것이 없다.
probe를 가볍게 유지하기(KEEPING PROBES LIGHT)
probe는 너무 무겁고 많은 resource 를 소비해서는 안된다. 이것은 container 의 속도를 느려지게 만드는 것이다.
책의 후반에선 container 가 사용하는 CPU 와 같은 resource 의 제한을 설정하는 방법도 다루게 된다.
Probe 에 재시도 루프를 구현하지 마라 (DON’T BOTHER IMPLEMENTING RETRY LOOPS IN YOUR PROBES)
probe 의 실패 임계값을 1로 설정하더라도 실패를 한번 했다고 간주하기 보단 이미 여러번 재시도를 했다.
따라서 probe 에 자체적인 재시도 loop 를 구현하는 것은 헛수고 이다.
라이브니스 프로브 요약 (LIVENESS PROBE WRAP-UP)
k8s 는 probe 를 통해 container 를 재시작해 container 가 계속 재실행 하도록 한다는 점을 이해했다.
이 작업은 pod 를 호스팅 하는 node 의 kublet 에서 수행한다.
그러나, node 자체에 crash가 발생한 경우 pod 를 재시작 해야하는 것은 controller 의 몫이다.
4.2 ReplicationController 소개
replication controller 는 k8s의 resource 로 항상 pod 가 실행되도록 보장한다.
node 가 사라지거나 node 에서 pod 가 제거된 경우, replication controller 는 사라진 파드를 감지하고 교체하여 파드를 생성한다.
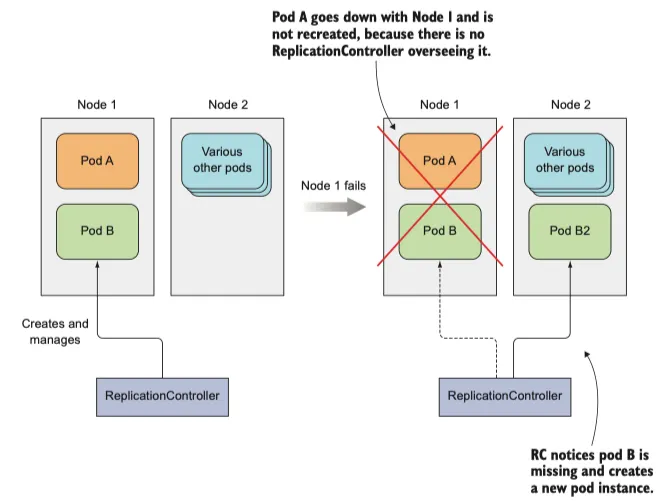
node 가 실패하면 replication controller 가 관리하는 pod 만 다시 생성한다.
위 그림에서 replication controller 는 하나의 파드만 관리하지만 일반적으로 여러 pod 를 관리한다.
replication controller 의 동작
실행 중인 pod 목록을 지속적으로 모니터링 하고, 특정 "type"의 실제 파드 수가 의도하는 수와 일치하는지 항상 확인한다.
만약 더 많이 실행된 다면 초과본을 제거한다.
의도한 개수 보다 더 많은 pod 가 실행되는 경우는 다음과 같다.
•
누간가 같은 유형의 pod 를 수동으로 만든다
•
누군가 기존의 파드 type 을 변경한다
•
누군가 의도하는 pod 수를 줄인다.
replication controller 는 label selector 와 일치하는 pod 세트에 작동한다
컨트롤러 조정 루프 소개
정확한 수의 파드가 항상 label selector 와 일치하는지 확인하는 것이다.
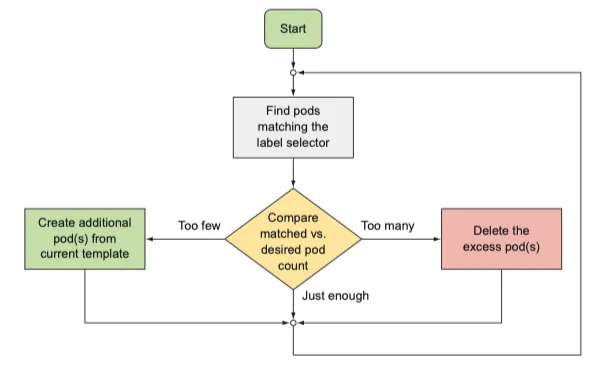
replication controller 의 조정 루프
replication controller 의 3가지 요소 이해
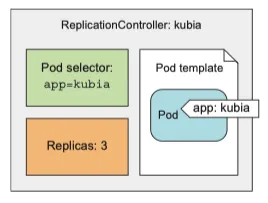
3가지 핵심 요소
•
label selector: controller 의 범위안에 있는 파드를 결정한다.
•
replica count: 실행할 pod의 의도하는 수
•
pod template: 새로운 pod replica 를 만들 때 사용한다.
replica count 만 기존 파드에 영향을 미친다.
컨트롤러의 label selector 또는 pod template 변경의 영향 이해
•
label selector 와 pod template 을 변경해도 기본 pod 에 영향을 미치지 않는다
•
label selector 를 변경하면 기존 파드가 replication controller 의 범위를 벗어나므로 controller 가 해당 pod 에 대한 관리를 중지한다.
•
pod를 생성한 후에는 실제 "contents(container image, 환경 변수 등등)" 에 신경을 쓰지 않는다
replication controller 사용 시 이점
•
기존 pod 가 사라지면 새 pod 를 시작해 pod가 항상 실행되도록 한다.
•
cluster node 에 장애가 발생하면 해당 node 에서 실행 중인 모든 pod 에 관한 교체 복제본이 생성된다. (재배치가 아니라 재생성)
•
수동 혹은 자동으로 scale out 을 자유롭게 할 수 있다.
Replication controller 생성
apiVersion: v1
kind: ReplicationController # RC의 manifest 정의
metadata:
name: kubia
spec:
replicas: 3
selector:
app: kubia # 관리하는 pod 선택
template: # 새 pod 에 사용할 pod template
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
YAML
복사
위 template 은 다음과 같이 해석된다.
replica controller
1.
app:kubia 라는 label 을 갖는 pod 를 관리한다.
2.
pod 의 instance 는 3개이다.
template
1.
이 template 으로 생성되는 pod 의 label 은 app:kubia 이다.
2.
8080 port 를 사용한다.
3.
만약 label 이 다르다면 pod 는 무한정 생성된다. 반드시 controller 와 pod 의 label 을 동일하게 하자
replication controller 작동 확인
kubectl get pods
YAML
복사

삭제된 파드에 관한 replication controller의 반응 확인
kubectl delete pod kubia-53thy
YAML
복사

삭제와 생성이 동시에 일어나고 있다.
replication controller 정보 얻기
kubectl get rc
YAML
복사

kubectl describe rc kubia
YAML
복사
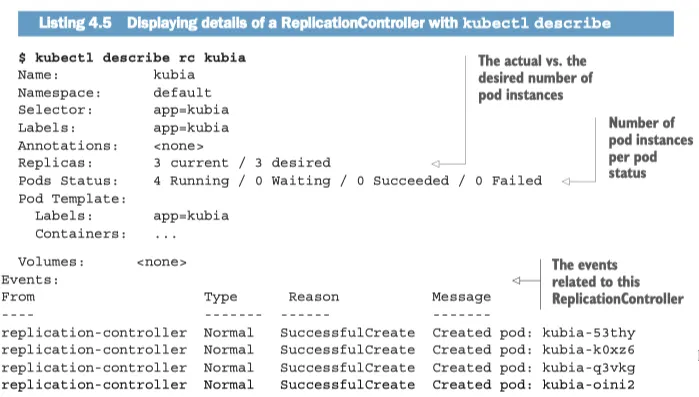
종료중인 것으로 간주되는 pod 가 있기 때문에 current, desired 는 동일하다.
컨트롤러가 새로운 pod 를 생성한 원인 정확히 이해하기
controller 가 새 교체 pod 를 만들어 pod 삭제에 대응한다
이것은 삭제에 대한 대응이 아니라 결과적인 상태(부족한 pod 의 수)에 대응하는 것이다.
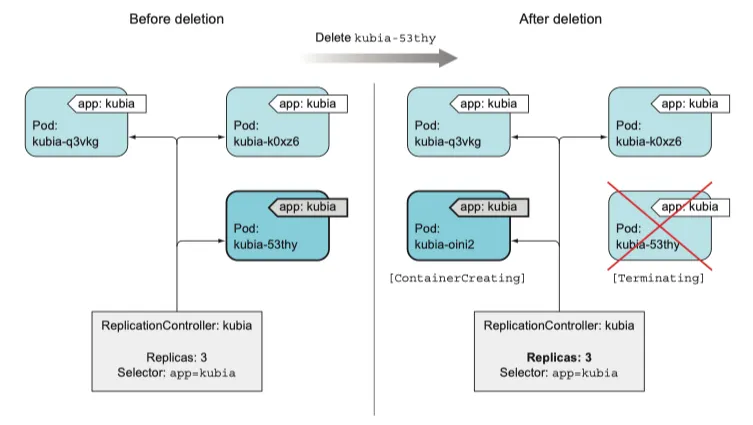
pod 가 사라지면 replication controller 는 pod 의 수가 부족함을 인지하여 새 pod 를 생성한다.
노드 장애 대응 (RESPONDING TO A NODE FAILURE)
수동으로 삭제된 pod 가 새로 실행 되는 것은 그리 큰 일이 아니다.
k8s 는 여러 node중 장애가 발생하여 문제가 된 node 에서 실행 중인 pod 를 자동으로 다른 node 로 migration 한다.
책에서는 gcp cloud 의 예제를 사용하여 실험한다.

gcp 로 접근하여 하나의 node 의 network 를 중단한다.

노드 network 가 연결돼 있지 않기 때문에 Not Ready 상태이다.
즉시 pod 를 조회하면 k8s 가 pod 를 다시 scheduling 하기 전에 잠시 대기한다. node 가 몇 분 동안 접속할 수 없는 상태로 유지될 경우 해당 node 에 스케쥴 된 pod 는 상태를 알 수 없음 (Unknown) 으로 변경된다.
그렇다면 replication controller 는 즉시 새 pod 를 기동할 것이다.

kubia-dmdck 는 AGE 가 5초인 것으로 확인되어 새로 생성된 pod 임을 알 수 있다.
즉, replication controller 는 시스템의 실제 상태를 의도하는 상태로 만드는 작업을 다시 수행했다.
replication controller 의 범위 안팎으로 pod 이동하기
replication controller 가 pod 를 관리하는 대상은 오로지 label selector 에 달려있다. 이 label selector 와 일치하는 pod 만을 관리한다.
만약 pod 의 label 을 변경해 replication controller 와 일치하지 않는다면 해당 pod 는 수동으로 만든 pod 와 같다. 이 파드에 문제가 생기면 수동으로 대응해야 한다.
그러나 pod 의 label 을 변경하면 pod 가 하나 사라진 것을 replication controller 가 감지하고 사라진 pod 를 대체하기 위해 새로운 pod 를 기동함을 명시하라
다음의 실험을 통해 정확히 살펴보자
Replication controller 가 관리하는 pod 에 label 을 추가
kublet label pod kubi-dmdck type=special
kublet get pods --show-labels
YAML
복사
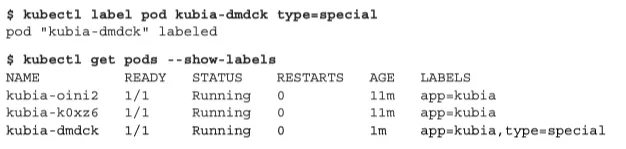
pod 에 새로운 label 을 추가했다.
아직까진 달라진 것이 없다 RC 가 관리하는 pod 에 소속되기 때문이다.
kubectl label pod kubia-dmdck app=foo --overwrite
YAML
복사
하지만 새로운 app=foo 로 overwrite 를 하게 된다면 label이 변경되기 때문에 관리 범위에서 벗어난다.
--overwrite 가 없다면 label 은 변경되지 않는다. 실수로 label 을 바꾸지 않도록 하기 위함이다.

pod 는 4개가 된다.
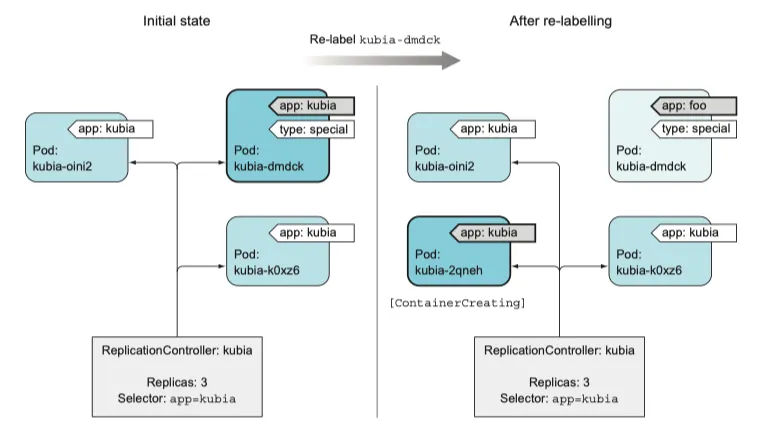
label 을 변경해 RC 범위에서 pod 를 제거했다.
label 이 app=kubia 에서 app=foo 로 변경하면 replication controller 가 더 이상 해당 pod 를 관리하지 않는다. pod kubia-dmdck 는 이제 독자적인 pod 가 되었으며, 수동으로 삭제해야 한다.
controller 에서 pod를 제거하는 실제 사례
현업에서 특정 pod 에 문제가 생긴경우 replication controller 의 범위에서 제거하고, 직접 접근하여 여러가지 실험을 해볼 수 있다.
실험이 종료되고 원인을 찾거나 해야 할 일이 끝나면 pod 를 제거하면 된다.
Replication controller 의 label selector 변경
pod 의 label 을 변경하는 대신 replication controller 의 selector 를 수정하면 어떻게 될까?
답
pod template 변경
template 을 수정하는 것은 쿠키 커터를 다른 것으로 교체하는것과 같다.
잘라낼 쿠키에만 영향을 줄 뿐, 잘라낸 쿠키는 아무런 영향을 미치지 않는다.
기존 파드를 수정하려면 해당 pod 를 삭제하고 replication controller 가 새 template 기반으로 새 파드로 교체하도록 해야한다.
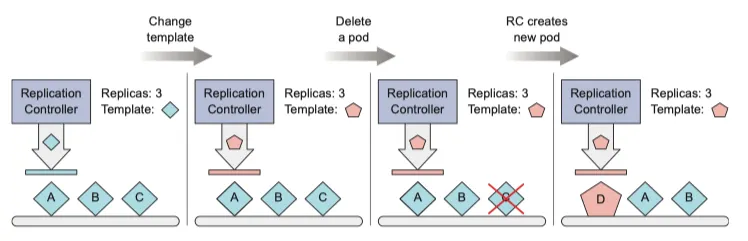
새로 생성된 pod 에만 영향을 미치며 기존 pod 는 영향을 받지 않는다.
다음 명령으로 replication controller 를 편집할 수 있다.
kubectl edit rc kubia
YAML
복사
반환된 yml 파일을 수정하고 저장하면 기존 pod 는 변경이 없고 임의로 한 pod 를 삭제하여 새로운 pod 가 생기면 그 pod 부터 변경된 내용이 반영된다.
수평 pod scaling
replicas 필드 값을 변경하기만 하면 된다.
변경된 값이 더 크면 새로운 pod 가 실행되고, 적다면 기존 pod 가 삭제될 것이다.
Replication controller scale up 하기
기존 3개를 10개로 조정할 것이다.
kubectl scale rc kubia --replicas=10
YAML
복사
이 방법 말고 edit 을 이용할 수 있다.
Replication controller 의 정의를 편집해 scaling 하기
kubectl edit rc kubia
YAML
복사
text 편집기에서 spec.replicas 필드를 찾아 값을 10으로 변경한다.

저장하고 편집기를 닫으면 replication controller 가 갱신되어 즉시 10개로 확장된다.
kubectl get rc
YAML
복사

kubectl scale 명령으로 scale down 하기
kubectl rc kubia --replicas=3
YAML
복사
마찬가지로 편집기에서도 수정할 수 있다.
스케일링에 대한 선언적 접근 방법 이해
x 개의 instance 가 실행되도록 한다.
와 같은 정의를 입력하는 것이다.
이 선언적 접근 방식을 통해 k8s cluster 와 쉽게 상호작용할 수 있다.
Replication controller 삭제
kubectl delete 를 통해 replication controller 를 삭제하면 pod 도 삭제된다.
그러나 replication controller 로 생성한 pod 는 필수적인 부분이 아니며 관리만 받기 때문에 controller 만 삭제하고 pod 는 실행 상태로 둘 수도 있다.
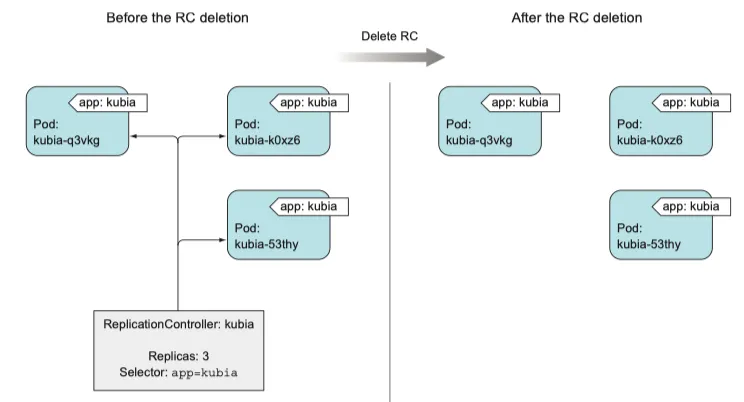
—cascade=false 옵션으로 pod 까지 삭제되지 않도록 한다.
kubectl delete rc kubia --cascasde=false
YAML
복사
replication controller 를 replica set 으로 바꾸기로 결정한 경우에도 이 방법은 유용하다
4.3 Replication controller 대신 Replica Set 사용하기
replica set 은 차세대 replication controller 로 거의 비슷하기 때문에 완전히 대체할 수 있다.
replica set 과 replication 의 비교
replicat set 은 좀 더 풍부한 표현식을 사용하는 pod selector 를 갖고 있다.
replica set 의 selector 는
•
특정 label 이 없는 pod
•
label 과 상관없이 특정 key 를 갖는 pod
즉 여러 label 을 하나의 그룹으로 매칭시킬 수 있다.
Replica set 정의하기
apiVersion: apps/v1beta2 # 소속된 그룹이 바뀜
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia # RC와 유사한 matchLabel 을 사용한다.
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
YAML
복사
resource 생성에 적절한 apiVersion 을 지정해야 한다.
차이점은 selector 에 있다. 바로 selector 아래에 label을 명시하는 대신 matchLabels 아래에 지정한다.
이미 기존에 동일한 label 의 pod 가 구동중이기 때문에 딱히 변화는 없다.
Replica set 생성 및 검사
kubectl create 명령을 사용해 yaml 파일로 replica set 을 생성하라
그 다음 kubectl describe 를 통해 검사할 수 있다.


Replica set 의 더욱 표적적인 label selector 사용하기
apiVersion: apps/v1beta2
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchExpressions:
- key: app # pod 의 키는 app 이다.
operator: In
values:
- kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
YAML
복사
•
in 은 label 의 값이 지정된 값 중 하나와 일치해야 한다.
•
NotIn 은 label 값이 지정된 값과 일치하지 않아야 한다
•
Exists 는 pod 에 지정된 label 을이 포함돼야 한다(값은 중요하지 않음)
◦
단 value 를 지정해선 안된다.
•
DoesNotExist 는 pod 에 지정된 key 를 가진 label 이 포함돼 있지 않아야 한다.
matchLabels 와 matchExpressions 를 모두 지정하면, selector 가 pod 를 매칭하기 위해서 모든 label 이 일치하고, 모든 표현식이 true 가 돼야 한다.
replica set 정리
kubectl delete rs kubia
YAML
복사
replica set 을 삭제하면 모든 pod 가 삭제된다.
4.4 데몬셋을 사용해 각 node 에서 정확히 한 개의 pod 실행하기
RC, RS 모두 cluster 내 어딘가에서 pod 가 실행되길 원하지만, cluster 의 모든 node 에 1개의 pod 가 각각 실행되길 원할 때 daemon set 을 사용할 수 있다.
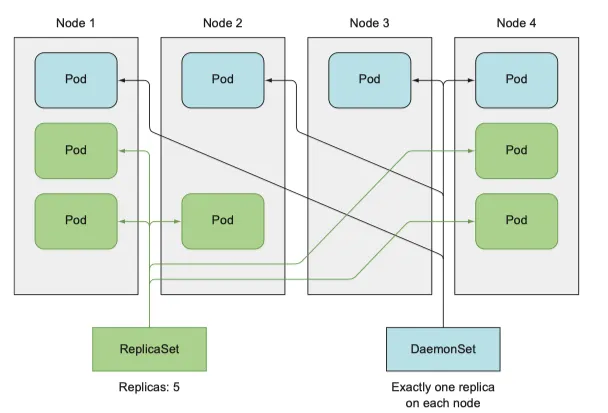
로그 수집기, 모니터링이 이에 해당하며, kube-proxy 가 해당한다
daemon set 으로 모든 노드에 pod 실행하기
•
target node 가 지정돼 있고, scheduler 를 건너뛰는 것을 제외하면 RC, RS 와 유사하다
•
복제본 수라는 개념이 없다 대신 node 수에 의존한다
•
새 node 가 cluster 에 추가되면 daemon set은 즉시 새 pod instance 를 새 node 에 배포한다
daemon set 을 사용해 특정 node 에서만 pod 실행하기
pod template 에서 node-Selector 속성을 이용하면 특정한 node 에만 pod 를 실행할 수 있다.
예제를 사용한 daemon set 설명
SSD 를 갖는 node에서 실행해야 하는 ssd-monitor 라는 데몬이 있다고 가정하자
이런 모든 node 에 disk=ssd 라는 label 을 추가하여 다음과 같이 node selector 를 사용해 daemon set 을 작성한다
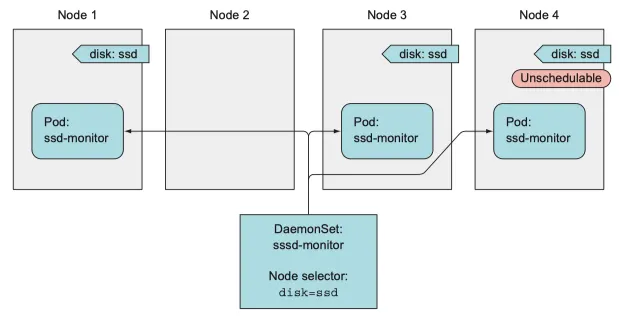
node selector 를 갖는 데몬셋을 사용해 특정 노드만 파드 배포
데몬셋 yaml 정의 생성
5초 마다 표준 출력으로 "SSD OK" 를 출력하는 process 를 실행하는 데몬셋이다.
apiVersion: apps/v1beta2
kind: DaemonSet
metadata:
name: ssd-monitor
spec:
selector:
matchLabels:
app: ssd-monitor
template:
metadata:
labels:
app: ssd-monitor
spec:
nodeSelector:
disk: ssd
containers:
- name: main
image: luksa/ssd-monitor
YAML
복사
이 pod 는 disk=ssd 에서만 실행된다.
데몬셋 생성
kubectl create -f ssd-monitor-daemonset.yaml
YAML
복사
데몬셋을 생성한다
kubectl get ds
YAML
복사
데몬셋을 보자

0이 이상하다 pod 목록을 조회한다

node 에 disk=ssd 를 추가하는것이 누락되었다.
필요한 label 을 node 에 추가하기
kubectl get node
YAML
복사

kubectl label node minikube disk=ssd
YAML
복사
disk=ssd label 을 node 중 하나에 추가한다
이제 데몬셋이 생성 된다.
노드에서 label 제거하기
node 에 label 을 disk=hdd 로 변경해보자
kubectl label node minikube disk=hdd --overwrite
YAML
복사

변경 사항이 반영되었다.
해당하는 pod 는 당연히 삭제될 것이다.
완료 가능한 단일 task를 수행하는 pod실행 (Running pods that perform a single completable task)
지금까지는 계속 실행하는 pod 에 관한 이야기만 했다.
하지만 작업이 완료된 후 종료되어야 하는 경우가 있다.
잡 리소스
•
이러한 기능은 k8s 가 job 이라는 resource 에서 제공하며 실행중인 process 가 성공적으로 완료되면 container 를 다시 시작하지 않는다.
◦
pod 가 완료된 것으로 간주된다.
•
node 에 장애가 발생한다면 RS, RC와 같이 다른 node 로 스케쥴링 된다.
•
process 자체에 장애가 발생한 경우 job 에서 container 를 다시 시작할 것인지 설정할 수 있다.
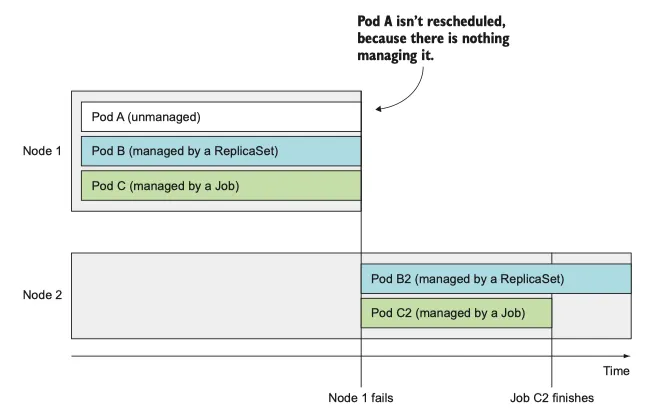
•
job 은 제대로 완료되는 것이 중요한 임시 작업에 유용하다
job resource 정의
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
template: # pod selector 를 지정하지 않는다.
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure # 잡은 기본 재시작 정책을 사용할 수 없다.
containers:
- name: main
image: luksa/batch-job
YAML
복사
이 job 은 120초 동안 실행된 후 종료되는 process 를 호출한다.
job 은 무한정 실행하지 않으므로 기본 정책 사용이 불가능하다 따라서 restartPolicy 는 OnFailure 나 Never 로 설정해야 한다.
pod 를 실행한 job 보기
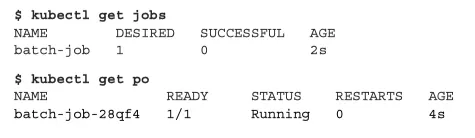
2분이 지나면 pod 가 더 이상 목록에 표시되지 않기 때문에 --show-all (또는 -a)을 사용해야 한다.
kubectl get po -a
YAML
복사

pod 가 삭제되지 않는 이유는 해당 pod 의 로그를 검사할 수 있게 하기 위해서 이다.

kubectl get job
YAML
복사

작업이 성공적으로 완료된 것으로 표시되는데 yes, no 가 아닌 desired 에 숫자로 나타낸다 무엇을 의미할까
job 에서 여러 pod instance 실행하기
job 은 2개 이상의 pod instance 를 생성해 순차 혹은 병렬로 실행하도록 구성할 수 있다.
apiVersion: batch/v1
kind: Job
metadata:
name: multi-completion-batch-job
spec:
completions: 5 # 5개 파드를 순차적으로 실행한다.
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
YAML
복사
이 job 은 5개 pod를 실행한다.
만약 pod 중 하나가 실패하면 job 이 새 pod 를 생성하므로 job 이 전체적으로 5개 이상의 pod 를 생성할 수 있다.
병렬로 job pod 실행하기
apiVersion: batch/v1
kind: Job
metadata:
name: multi-completion-batch-job
spec:
completions: 5 # 5개 pod 를 성공적으로 완료해야 한다
parallelism: 2 # 2개 까지 병렬로 실행할 수 있다.
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
YAML
복사

2개 생성하여 병렬로 실행한다. 이 중 하나가 성공하면 5개 pod 가 성공적으로 완료될 때 까지 job 이 다음 pod 를 실행한다.
job 스케일링
job 이 실행되는 동안 parallelism 속성을 변경할 수 있다.
kubectl scale job multi-completion-batch-job --replica 3
YAML
복사
2 → 3 으로 증가 된다.
Job pod 가 완료되는 데 걸리는 시간 제한하기
pod 스펙에 activeDeadlineSeconds 속성을 설정하면 pod 의 실행 시간을 제한할 수 있다.
4.6 Job을 주기적으로 또는 한 번 실행되도록 스케쥴링 하기
linux, unix OS 에서 cron 작업과 같은 것도 k8s 가 제공한다 이것을 cronJob 이라 한다
cron job 생성하기
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: batch-job-every-fifteen-minutes
spec:
schedule: "0,15,30,45 * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
YAML
복사
스케쥴 설정하기
스케쥴 왼쪽에서 오른쪽으로 5개 항목을 가지고 있다.
•
분
•
시
•
일
•
월
•
요일
15분 마다 job 을 실행하므로 "0,15,30,45 * * * *" 이고, 매달 첫째 날에 30분 마다 실행하고 싶다면
0,30 * 1 * * 로 설정해야 한다.
스케쥴된 job 의 실행 방법 이해
job 이나 pod 가 상대적으로 늦게 생성되고 실행될 수 있다.
예정된 시간을 너무 초과해 시작돼서는 안된다는 엄격한 요구 사항을 갖는 경우도 있다.
startingDeadlineSeconds 필드를 이용해 데드라인을 설정할 수 있다.
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: batch-job-every-fifteen-minutes
spec:
schedule: "0,15,30,45 * * * *"
startingDeadlineSecond: 15
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
YAML
복사
