

다루는 내용
•
CPU 사용률 기반 pod auto scaling
•
사용자 정의 matric 기반 pod auto scaling
•
pod 의 scale up 이 불가능한 이유 이해
•
auto horizontal scaling of cluster node
k8s 은 replica 값을 늘려 수동으로 확장할 수 있지만, 이러한 경우 예상치 못하게 트래픽이 늘어나는 것은 대응할 수 없다. 물론 부하가 예측된다면 문제가 없지만, 개발자가 수동으로 개입하여 이러한 트래픽 증가를 대응하는 것은 이상적이지 않다.
k8s 은 모니터링을 수행하면서 CPU, matric 을 확인하여 자동으로 대응하는 것이 가능하다
이러한 auto scaling 은 1.6 → 1.7 에서 rewritten 되어 인터넷에서 찾은 정보가 옛날 정보일 수 있음으로 유의해야 한다.
Horizontal pod autoscaling
•
수평 파드 확장 (Horizontal Pod Autoscaling) 은 auto scaling controller 에 의해 자동으로 pod 의 개수를 조정하는 것을 말한다.
•
HPA(HorizontalPodAutoscaler) 리소스를 작성해 HPA 에 설정된 값으로 metric 값이 만족되는 pod 의 개수를 계산한다
•
이 대상에 포함되면 replicas 필드 값을 조절한다
Understanding the autoscaling process
auto-scaling process 는 3단계로 나눈다
•
확장 가능한 resource object 에서 관리하는 모든 pod metric 을 가져온다
•
metric 을 지정한 목표 값과 같거나 가깝도록 하기 위해 필요한 pod 수를 계산한다
•
확장 가능한 resource 의 replicas 필드를 갱신한다
각 단계를 살펴본다
Obtaining Pod metrics

pod 에서 HPA 로의 메트릭 흐름
•
auto scaler 는 pod 에서 직접 metric 을 가져오는게 아니라 다른 source 에서 가져온다
•
kublete 에서 실행되는 cAdvisor 가 metric 을 수집한다
•
수집된 metric 은 cluster 전역 구성 요소인 Heapster 에 의해 집계된다.
•
auto-scaler 는 heaper 에 REST 로 질의하여 pod metric 을 가져온다
이 뜻은 Heapster 를 실행시켜야 한다는 의미이고, minikube 를 사용했다면 heapster 가 이미 cluster 에 활성화 되어 있다.
만약 heapster 에 질의해보고 싶다면 kube-system namespace 에서 찾아볼 수 있다.

오토스케일러가 metric 을 얻는 방법의 변경사항
1.6 이전에는 HPA 가 힙스터에서 직접 메트릭을 가져왔다.
1.8 에서는 auto-scaler 가 집계된 버젼 API 를 통해 값을 가져온다
이 기능은 --horizontal-pod-autoscaler-use-rest-clients=true 옵션을 주고 실행해야 하지만 1.9 부터는 default 이다.
Core API 는 metric 자체를 노출하지 않는다. 1.7 부터 k8s 는 다중 API 서버를 등록하고 하나의 API 서버로 표시할 수 있다.
Calculating the required Number of pods
auto-scaler 는 스케일링 대상이 되는 resource(deployment, replicaset, replicationController, stateful set) 에 속한 pod 의 모든 metric 을 가지고 있으면, 이 매트릭을 사용해 replica 수를 파악할 수 있다.
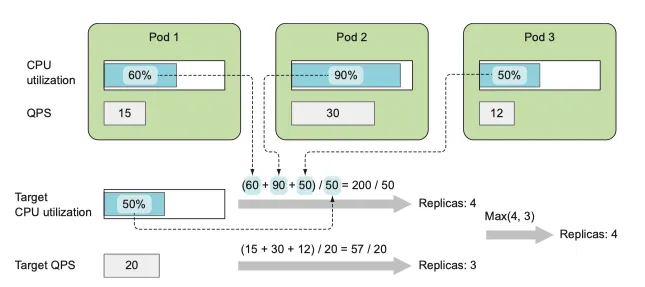
두 메트릭을 이용해 필요한 replica 수 계산
•
모든 replica 의 평균 값을 이용해 지정한 목표와 가깝게 하는 숫자를 찾아낸다
◦
입력은 pod metric set
◦
출력은 정수
•
오토 스케일링에 여러 pod metric을 기반으로 하는 경우 각 metric 의 replica 수를 개별적으로 계산한 뒤 가장 높은 값을 취한다
•
단일 매트릭을 고려하도록 설정되어 있다면, 모든 pod 의 metric 을 더한 뒤 HPA 리소스에 정의된 목표 값으로 나눈 값을 그 다음으로 큰 정수로 반올림 하여 구한다
•
실제 계산은 metric 값이 불안정한 상태에서 빠르게 변할 때 auto-scaler 가 같이 요동치지 않도록 하기 때문에 상당히 복잡하다
Updating the desired replica count on the scaled resource
(레플리카 수 갱신)

수평적 pod auto-scaler 는 서브 리소스만 수정한다.
•
스케일링된 resource object 의 replica 개수 필드를 원하는 값으로 갱신한다
•
replica set controller 가 추가 파드를 시작하거나 초과한 pod 를 삭제하도록 한다
◦
replicas 가 변경되는 것을 감지하여 수행됨
현재 노출되어 replica 숫자가 변경될 수 있는 resource 는 다음과 같다
•
deployment
•
replica set
•
replication controller
•
stateful set
전체 오토스케일링 과정 이해
지금까지 auto-scaling 을 하는 3 step 을 살펴보았는데 이제 전체를 한번에 보도록 하자
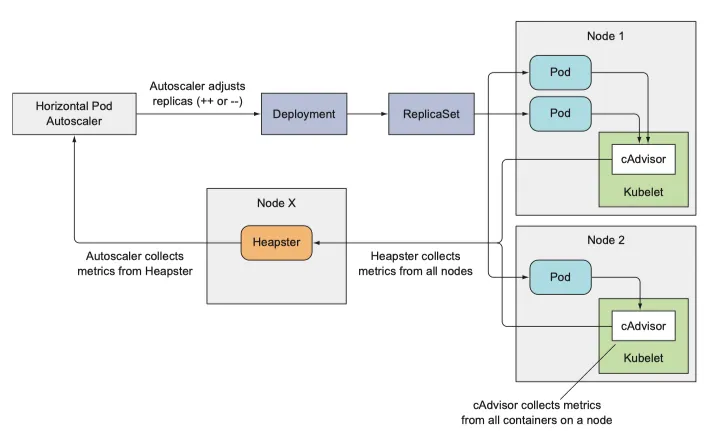
오토 스케일러가 메트릭을 얻어 대상 deployment 를 재조정하는 모습
•
pod → cAdvisor
•
cAdvisor → Heapster → HPA
•
HPA → replicas 필드 조정
CPU 사용률 기반 스케일링
•
auto scaling 에서 가장 중요한 metric 은 프로세스가 소비하는 CPU 사용률 이다.
•
100%에 도달하면 요구에 대응할 수 없어 scale-up 혹은 scale-out 이 필요하다
CPU 사용률은 불안정하기 때문에 CPU가 완전히 바쁜 상태에 도달하기 전에 scale-out 을 수행하는 것이 좋다
여기서 우리는 Horizontal scale out 을 다루기 때문에 scale-out(pod 개수 증가)에 대해 살펴본다
container 내부에서 실행되는 process 는 container resource 요청을 통해 요구한 CPU 사용량을 보장받는다
하지만, 다른 프로세스가 해당 node 에서 cpu 를 모두 사용하게 될 수도 있다.
CPU usage 80% 라고 할때, node 의 80% 인지, pod가 보장받은 CPU의 80%인지, 리소스 제한을 통해 파드에 설정된 엄격한 제한의 80%인지 명확하지 않다 → communication
auto-scaling 에 한해서는 파드가 보장받은 사용률이 가장 중요하다
•
auto-scaler 는 pod 의 실제 CPU 사용량과 CPU 요청량을 비교한다
•
이때 auto-scaling 이 필요한 pod 는 auto-scaler 가 CPU 사용률을 결정하기 위해 LimitRange 오브젝트를 통해 CPU 요청을 설정한다
CPU 사용량을 기반으로 HPA 생성
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: luksa/kubia:v1
name: nodejs
resources:
requests:
cpu: 100m
YAML
복사
CPU 요청을 설정한 deployment, 최신 버젼에 맞도록 수정했다.
여기에 scale-out 을 활성화 하기 위한 HPA를 생성하고, 이 deployment를 가리키도록 한다
yaml manifest 를 준비할 수도 있지만, kubectl 명령어로 쉽게 해보자
kubectl autoscale deployment kubia --cpu-percent=30 --min=1 --max=5
YAML
복사
HPA 오브젝트를 생성하고 kubia deployment 를 스케일링 대상으로 설정한다
•
cpu 목표 사용률 30%
•
최소, 최대 replica 수 설정
auto-scaler 는 이 deployment 의 pod 들의 CPU usage 를 30% 대로 유지하기 위해 replica 수를 1~5개 로 늘리거나 줄이게 된다.
이제 HPA manifest 를 정의해보자
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler # auto scaling 그룹에 속해있다.
metadata:
creationTimestamp: "2021-09-11T03:00:39Z"
name: kubia # 이름을 갖는데 deployment 와 이름이 동일하지 않아도 된다.
namespace: default
resourceVersion: "156864"
uid: 53b17117-52ce-4d81-9ace-0e5c187693ba
spec: #30%를 유지하기 위한 auto scaling 규칙
maxReplicas: 5 # 최대
metrics:
- resource:
name: cpu
targetAverageUtilization: 30
type: Resource
minReplicas: 1 # 최소
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kubia
status: # 오토 스케일링 현재 상태
conditions:
- lastTransitionTime: "2021-09-11T03:00:55Z"
message: the HPA controller was able to get the target's current scale
reason: SucceededGetScale
status: "True"
type: AbleToScale
- lastTransitionTime: "2021-09-11T03:00:55Z"
message: 'the HPA was unable to compute the replica count: failed to get cpu utilization:
unable to get metrics for resource cpu: unable to fetch metrics from resource
metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)'
reason: FailedGetResourceMetric
status: "False"
type: ScalingActive
currentMetrics: null
currentReplicas: 3
desiredReplicas: 0
YAML
복사
이 명령어로 불러들였다.
HPA 리소스는 여러 버젼이 존재하는데 여기서는 최신인 autoscaling/v2beta1 을 사용
이전 버전은 autoscaling/v1 이다.
최초 auto-scaling event 보기
cAdviosr 가 CPU metric 을 가져와 heapster 에 저장하기 까지 시간이 걸린다
그 사이에 HPA resource 를 kubectl get 명령으로 표시하면 TARGETS 은 unknown 이 반환된다.

아무런 요청이 없는 3개 파드는 30% 이하를 유지하기 때문에 시간이 지나면 replica 는 1개만 남는다
auto-scaler 는 deployment 에서 replica 수만 조정한다
replicaset controller 는 두개의 초과 파드를 삭제하고 하나의 pod 만 남긴다
•
아직까지 변경은 없다.
•
hpa 는 왜 안나올까?
Name: kubia
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sat, 11 Sep 2021 12:00:39 +0900
Reference: Deployment/kubia
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): <unknown> / 30%
Min replicas: 1
Max replicas: 5
Deployment pods: 3 current / 0 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededGetScale the HPA controller was able to get the target's current scale
ScalingActive False FailedGetResourceMetric the HPA was unable to compute the replica count: failed to get cpu utilization: unable to get metrics for resource cpu: unable to fetch metrics from resource metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedComputeMetricsReplicas 11m (x12 over 13m) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: unable to get metrics for resource cpu: unable to fetch metrics from resource metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)
Warning FailedGetResourceMetric 3m48s (x41 over 13m) horizontal-pod-autoscaler failed to get cpu utilization: unable to get metrics for resource cpu: unable to fetch metrics from resource metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)
YAML
복사
어 나는 api 호출이 안된다고 나오네?? ㅠㅠ
실제 describe 살펴보기
E0911 04:00:47.218516 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.49.2:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.49.2 because it doesn't contain any IP SANs" node="minikube"
I0911 04:00:48.278010 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
I0911 04:00:58.277799 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
E0911 04:01:02.210808 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.49.2:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.49.2 because it doesn't contain any IP SANs" node="minikube"
I0911 04:01:08.277088 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
E0911 04:01:17.213880 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.49.2:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.49.2 because it doesn't contain any IP SANs" node="minikube"
I0911 04:01:18.278189 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
I0911 04:01:28.278269 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
E0911 04:01:32.212100 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.49.2:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.49.2 because it doesn't contain any IP SANs" node="minikube"
I0911 04:01:38.278637 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
YAML
복사
metric server 를 설치해도 이런 로그가... ㅠㅠ
마지막 부분에 있는 테이블을 보면 모든 metric 보다 낮기 때문에 하나의 replica 만 남기도록 재조정했다.
scale up 일으키기
첫 번째 re-scale 을 목격했다. CPU 사용량이 증가하면 auto-scaler 가 이를 감지해 추가 파드를 시작하는 것을 보자
먼저 pod 는 서비스를 통해 노출시킨다 가장 쉬운 방법은 kubectl expose 이다
kubectl expose deployment kubia --port=80 --target-port=8080
YAML
복사
요청을 보내고 deployment 에 무슨일이 일어나는지 보자
watch -n 1 kubectl get hpa,deployment
YAML
복사
osx 를 사용한다면
•
주기적으로 watch 를 사용하거나
•
kubectl —watch 옵션과 함께 사용하라
•
brew install watch 도 가능
다음 명령을 다른 터미널에서 실행한다
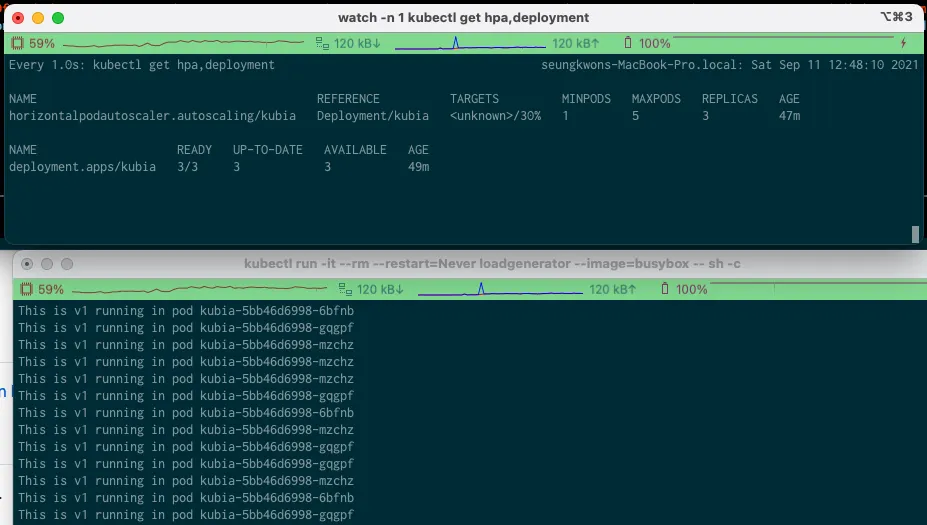
kubectl run -it --rm --restart=Never loadgenerator --image=busybox -- sh -c "while true; do wget -O - -q http://kubia.default; done"
YAML
복사
--rm : 파드가 종료된 후 삭제한다
restart=Never kubectl run 명령이 deployment 오브젝트를 통해 관리되는 pod 를 생성하는 대신, 관리되지 않는 pod를 직접 만들도록 한다

ctrl+c 로 명령을 멈추면 loadgenerator 가 제거된다.
현재 metric 수집이 안되지만, 책에서는 1개의 pod 로만 요청을 받아 점점 pod 가 증가된다고 한다

만약 cpu 사용률이 30%가 안된다면 부하 생성기를 더 실행하는 방법이 있다.
책에서는 CPU가 108%까지 올라갔다고 한다(그래서 replica 는 4개까지 증가한다)
container CPU 사용률은 container 의 실제 CPU 사용량을 요청한 CPU 값으로 나눈 것이다.
즉, 최소 사용량을 통해 정의하기 때문에 container 가 요청한 CPU 보다 더 많은 CPU를 소비할 수 있어 100%를 넘는것이 가능하다
여기서 108% 때문에 replica 는 4개까지 증가했다고 하는데 4는 어떻게 산정된 숫자일까?
이 된다. 소수점에서 반올림 하면 4가 된다.
108은 현재 올라간 CPU 사용률, 30은 required 사용률이다
이때 4개로 auto-scaling 되면 CPU 사용률은 27% 근처일 것으로 예상된다.
최대 스케일링 비율 이해
CPU는 초기에 사용량이 더 크기 때문에 초기는 150%까지 될 수도 있다.
하지만, 4개까지만 확장되었다.
한 틱에 늘어나는 개수
•
한 번의 확장 단계에서 추가할 수 있는 replica 수는 제한되어 있다.
•
두 개를 초과하는 replica 가 존재할 경우 최대 두 배의 replica 를 생성할 수 있다.
늘어나는 시기
•
현재는 지난 3분 동안 아무런 re-scaling 이 없다면 scale-up 이 일어나도록 되어있다.
•
scale-down 의 경우 5분 간격으로 조금 더 적게 일어난다
이 제한을 기억한다면, metric 은 re-scale 작업이 필요한 수치임에도 re-scaling 이 일어나지 않음이 납득될 것이다
기존 HPA 오브젝트에서 목표 metric 값 변경
현재 30% 인 CPU 사용률은 실제로 낮은 값이다 이것을 60% 까지 올려보자
kubectl edit 명령으로 HPA 리소스를 편집할 수 있다.
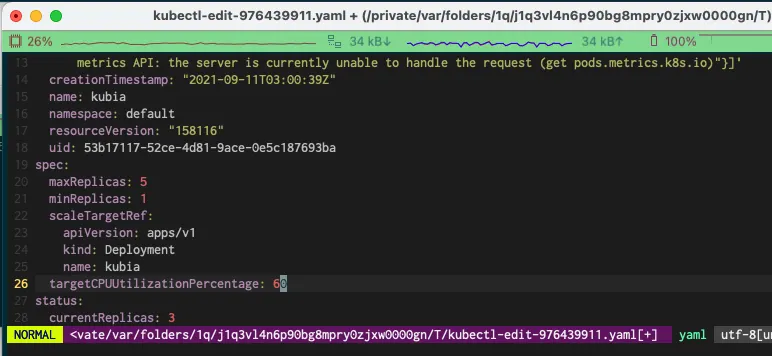
kubectl edit hpa
YAML
복사
describe 의 결과를 보면
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: "2021-09-11T03:00:39Z"
name: kubia
namespace: default
resourceVersion: "159708"
uid: 53b17117-52ce-4d81-9ace-0e5c187693ba
spec:
maxReplicas: 5
metrics:
- resource:
name: cpu
targetAverageUtilization: 60 # 60으로 늘어났다
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kubia
...
YAML
복사
메모리 소비량에 기반을 둔 스케일링
CPU 사용량에 기반한 auto-scaling 보다 메모리 기반이 훨씬 어렵다
•
scale-up 후에 오래된 pod 는 메모리를 해제하는 것이 필요하다
◦
이 작업은 system 이 아닌 application 에서 수행되어야 한다.
•
만약 application 이 이전 pod 와 같은 메모리를 사용하면 auto-scaler 는 다시 scale-up을 한다
•
이 반복 작업은 HPA resource 에 설정된 최대 pod 수에 도달할 때까지 계속 진행된다.
memory 기반 auto-scaling 은 k8s 1.8 버젼에서 처음 소개 됐고, CPU 기반과 똑같이 설정할 수 있다.
독자들이 살펴보라고 남겨둔다. (별로 추천하지 않는듯)
기타 그리고 사용자 정의 metric 기반 스케일링
cpu 기반은 쉽지만 메모리 기반은 어렵고 여러 문제 때문에 auto-scaling SIG(Special Interest Group) 은 오토 스케일러를 완전히 다시 설계했다.
여기서는 완전한 예제를 실행하기 보단 auto-scaler 가 다른 metric 소스를 사용하도록 설정하는 방법을 보여준다
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: "2021-09-11T03:00:39Z"
name: kubia
namespace: default
resourceVersion: "159708"
uid: 53b17117-52ce-4d81-9ace-0e5c187693ba
spec:
maxReplicas: 5
metrics:
- resource:
name: cpu # 사용률을 모니터링 할 리소스
targetAverageUtilization: 30 # 해당 리소스의 목표 사용률
type: Resource # metric 유형
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kubia
YAML
복사
보다시피 metric 필드에서 하나 이상의 metric 을 정의할 수 있다. 여기선 3가지 유형이 있다.
•
resource
•
pod
•
object
resource metric 유형 이해
resource 유형은 auto-scaling 결정을 container resource 요청 항목등의 resource metric 으로 하는데
지금까지 살펴본 것이다
pod metric 유형
pod 와 관련된 다른 metric 을 참조하는데 사용한다
•
QPS(초당 질의 수)
•
broker queue 의 사이즈 (메세지 개수)
◦
브로커의 경우 늘리면 감소하는 것은 불가능해 진다
QPS를 사용하기 원한다면 metric 필드 안에 항목을 추가하는 것이 필요하다
spec:
metrics:
- resource:
name: cpu # 사용률을 모니터링 할 리소스
targetAverageUtilization: 30 # 해당 리소스의 목표 사용률
type: Resource # metric 유형
- resource:
metricName: qps # metric 이름
targetAverageValue: 100 # 목표 평균값
type: Pods # pod metric 정의
YAML
복사
모든 파드는 QPS 가 100을 유지하도록 설정한다
오브젝트 metric 유형 이해
object metric 유형은 auto-scaler 가 pod 를 확장할 때 pod 에 직접 관련되지 않은 metric 을 기반으로 하도록 만든다
예를 들면, ingress 의 metric 을 이용할 수도 있다. (QPS, 요청 대기 시간등 등 완전히 다른 것일 수 있다)
spec:
maxReplicas: 5
metrics:
- type: Object # metric 유형
resource:
metricName: latencyMilles
target:
apiVersion: extensions/v1beta1
kind: Ingress
name: frontend
targetValue: 20
scaleTargetRef: # auto scaler 가 확장할 수 있는 확장 가능한 resource
apiVersion: apps/v1
kind: Deployment
name: kubia
YAML
복사
다른 object 의 metric 참조
•
latencyMills metric 을 사용하도록 설정되어 있다
•
목표는 20
•
목표 값 보다 높이 올라가면 kubia deployment 의 resource 를 확장한다
auto-scaling에 적합한 metric 결정
모든 값이 auto-scaling 기반으로 사용하기에 적합하진 않다.
앞서 memory 기반과 auto-scaling 과 같이 적합하지 않은 경우도 있다.
접합한 값은 pod 가 n 개 증가한다면 n 만큼 비례하며 metric 이 감속하는 것이다.
QPS의 경우 1000을 target 으로 한다면 pod 가 1개일때 1000을 모두 받지만 2개의 pod 가 되면 각각 500씩 받는데 이러한 것이 auto-scale 에 적합한 metric 이 된다.
replica 를 0으로 감소
현재 minReplicas 값은 0이 될 수 없다. 따라서 auto-scaler 는 pod 를 0을로 감소시키지 않는다.
0으로 축소하면 h/w 사용률이 크게 높아질 수 있다. 몇 시간, 며칠에 한번 요청을 받는 서비스를 항상 실행시켜 다른 pod 가 사용할 resource 를 소비하는 것이 합리적이지 않다.
그러나 이것은 언제가 추가된 기능이다.
수직적(Vertical) 파드 auto-scaling
모든 application 이 수평적 확장이 가능한 것이 아니다.
필요에 따라 CPU, memory 를 확장하는 방식으로 vertical auto-scaling 이 필요할 수 있다.
저자는 이 책의 집필을 시작할때 집필이 마칠때쯤 vertical auto-scaling 이 추가될 것이라고 생각했지만, 현재 까지도 없다고 한다.
현재는 기존의 존재하는 pod 의 vertical 확장은 불가능하다 manifest를 통해 수정하기 때문이다.
resource 요청 자동 설정
•
container 가 CPU, memory 요청을 명시적으로 정의하지 않았을 때 설정한다
•
initialResources 라는 플러그인을 통해 제공된다.
•
과거 resource 사용량 데이터를 살펴보고 요청 값을 적절하게 설정
수평적 클러스터 노드 확장
pod instance 를 생성하다가 더 이상 파드를 추가할 수 없을 경우 어떻게 해야할까?
단순히 pod instance를 만드는 데 국한된 것은 아니다.
이 경우 기존 pod 중 몇 개를 삭제하거나 pod가 사용하는 자원을 줄이거나 새로운 노드 추가가 필요하다.
노드 추가
•
on-premise 환경의 경우 새로운 machine 을 추가하고 k8s 일원으로 받아들여야 하며
•
cloud infra 의 경우 API를 호출하여 노드를 추가할 수 잇다.
•
k8s 는 추가적인 node 가 필요하면 추가 노드를 cloud provider 에게 요청하는 기능이 있다
cluster auto-scaler
노드에 resource 가 부족해서 scaling 을 할 수 없는 파드를 발견하면 추가 노드를 자동으로 공급한다
cloud infrastructure 에 추가 노드 요청
스케쥴러가 새로운 pod 를 존재하는 node 에서 생성할수 없다면, cluster auto-scaler 가 provider 에게 요청하는데 요청에 앞서
1.
auto-scaler가기존 노드에 스케쥴링 할수 없는 파드를 확인한다
2.
auto-scaler가 어떤 노드 유형이 해당 파드에 맞을지 확인한다
•
여러 유형이 가능하다면 그 중 설정 가능한 노드를 선택한다
3.
auto-scaler 가 선택한 노드 그룹에 scale-up 한다
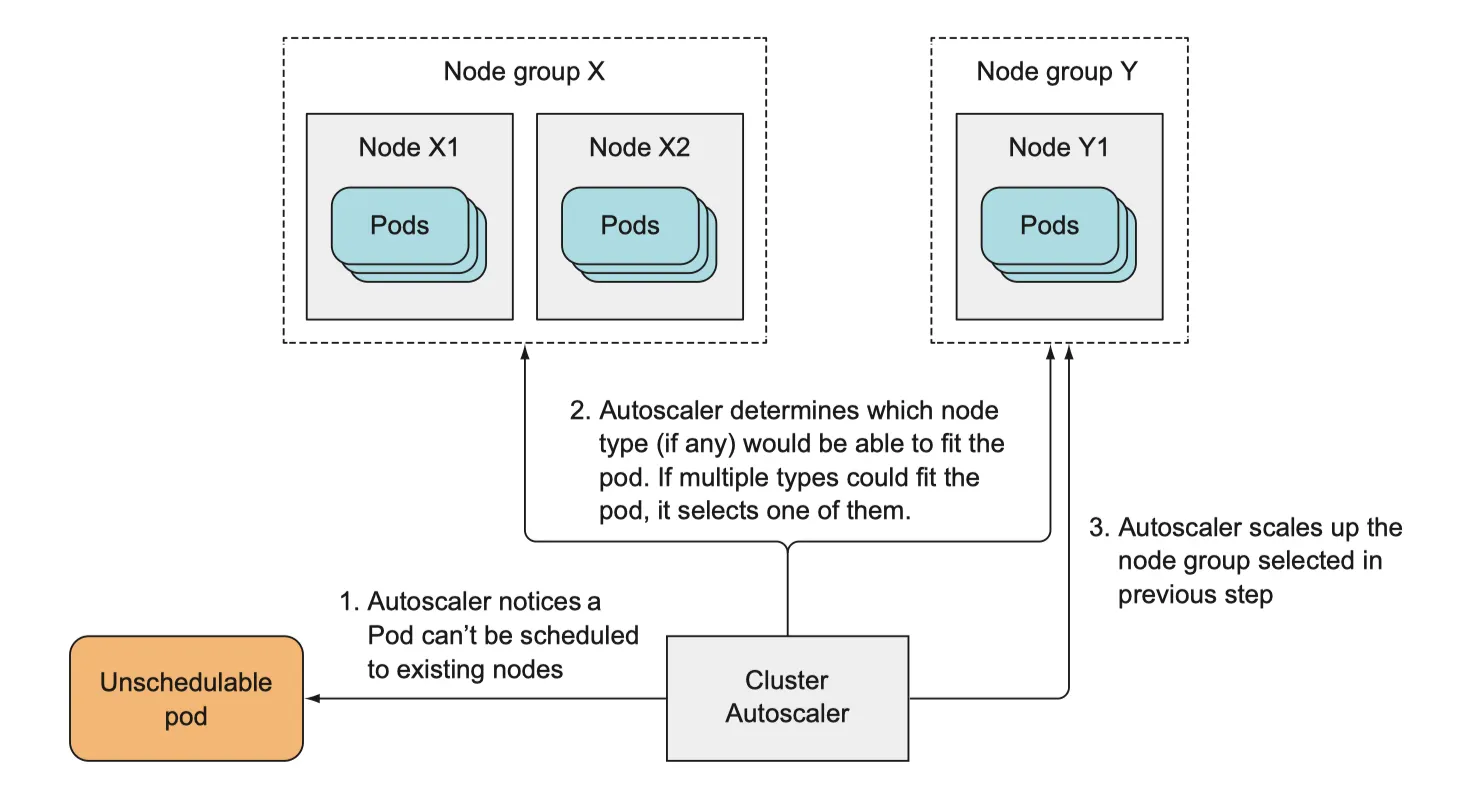
새 노드가 시작되면 kubelet API 서버에 노드 리소스를 만들어 등록한다. 그때부터 k8s 의 일원이 된다
노드 종료
즉, scale up 된 노드가 필요하지 않다면 회수하여 자원을 확보해야 한다.
특정 노드에서 실행중인 모든 pod의 CPU, memory가 50% 미만이면 해당 node 는 필요하지 않은 것으로 간주한다
만약 system pod가 node 에서 실행 중이라면 해당 노드는 종료될 수 없다.
그 외에도 서비스가 종료될 여지가 있는 pod 가 실행중이면 node 는 종료되지 않는다(local 저장소를 가진 파드)
node 에서 실행중인 pod 가 다른 노드로 다시 스케쥴링 될 수 있는 경우, 그런 pod 만 존재할때 node 종료가 가능하다
cluster auto-scaler 활성화
cluster auto-scaler 는 다음 cloud provider 에서 사용할 수 있다.
•
GKE
•
GCE
•
AWS
•
Azure
auto-scaler 를 실행하는 방법은 provider 가 무엇이냐에 따라 다르다
cluster scale down 동안 서비스 중단 제한
node 가 예기치 않게 실패한다면 pod 는 사용 불가 상태가 된지만, cluster auto-scaler 나 system 관리자로 인해 이뤄지는 상황이라면 추가 기능을 통해 pod가 종료되지 않게 만들 수 있다
•
quorum(정족수) 기반의 경우 특정 pod 개수는 반드시 보장되어야 한다.
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: kubia-pdb
spec:
minAvailable: 3 # 몇개의 파드를 항상 사용하도록 보장하는가
selector:
matchLabels: # 이 버짓이 적용될 label selector
app: kubia
YAML
복사
minAvailable 은 절대값이 아닌 % 도 사용할 수 있다.
이 resource에 의해 정의되면 정해진 숫자 이하로 떨어지지 않는다
