

애플리케이션은 시간이 지나면서 점점 변한다. 이 변화에 DB의 변화도 포함되고 column, field 가 추가되거나 삭제되며, data type이 변경되기도 한다.
이러한 DB 관점의 변경은 바로바로 적용된다. 하지만, application의 코드는 대체로 바로 적용되지 않는다.
application code 가 바로 적용되지 않는 이유
•
code 의 update 방식은 rolling update(stage rollout) 으로 갱신된다.
•
client 의 경우 사용자에게 달려있다. 종종 업데이트를 하지 않는 유저도 있기 때문이다.
이러한 이슈에도 불구하고 변경된 데이터에 시스템이 원활하게 실행되려면 양방향으로 호환성을 유지해야 한다.
•
호환성
◦
하위 호환성
▪
새로운 코드는 예전 코드가 기록한 데이터를 읽을 수 있어야 한다.
▪
새로운 코드는 기존 데이터에 대해 알기 때문에 큰 문제가 없을 수 있다.
◦
상위 호환성
▪
예전 코드는 새로운 코드가 기록한 데이터를 읽을 수 있어야 한다.
▪
새 버전의 코드에 의해 추가된 것을 무시할 수 있어야 하므로 더 어렵다.
▪
우리같은 back end 개발자들은 상위 호환성을 고려해야할까? 아무래도 우리 상황에선 생소한 개념인것 같다 (계속 햇갈림 ㅠ)
데이터 부호화 형식 - Formats for encoding Data
1.
프로그램은 보통 최소 두가지 형태로 표현된 데이터를 사용해 동작한다.
•
메모리 객체(object), 구조체(struct), list, array, hash table, tree
•
이러한 데이터 구조는 CPU 에서 효율적으로 접근하고 조작할 수 있도록 (포인터를 이용해) 최적화 된다.
2.
파일에 쓰거나 네트워크로 전송할때 json 과 같은 타입으로 encoding (부호화) 해야한다.
•
pointer 는 다른 프로세스가 이해할 수 없다.
•
바이트열은 메모리에서 사용하는 데이터 구조와 상당히 다르다
서로 다른 두 타입을 메모리에서 byte로 변경하는 것을 부호화(encoding, serialization or marshalling)이라 하고, 반대를 decoding(parsing, deserialization, unmarshalling) 이라 한다.

직렬화 라는 단어가 더 직관적일지라도 transaction 맥락에서도 사용되기 때문에 단어의 중복을 피하기 위해 여기서 사용하지 않는다.
언어별 형식 Language-Specific Formats
언어에서 인코딩을 위한 기능이 제공된다. java.io.Serializable
쉽게 인메모리 객체를 저장하고 복원하지만, 심각한 문제점이 많다.
•
다른 언어에서 표현된 데이터를 읽는것은 시스템 통합에 방해가 되기 때문에 각 시스템으로 전송할때 부호화를 수행한다.
•
데이터를 복원하기 위해 복호화 프로세스는 임의의 class를 instance화 할수 있어야 한다. 그런데 이는 보안 문제에 연관되기도 하는데 임의의 인스턴스를 생성하여 원격으로 특정 코드를 실행시킬 수 있기 때문이다.
◦
CWE-502: Deserialization of Untrusted Data

▪
인스턴스 생성에 어떠한 제약이 없다면 공격자가 어떠한 공격을 코드에 심어 실행시킬 수 있다.
◦
What Do WebLogic, WebSphere, JBoss, Jenkins, OpenNMS, and Your Application Have in Common? This Vulnerability.

구체적인 예시를 들어 설명하는데 바이트 코드에 추가 코드를 삽입하여 deserialization 과정에서 특정 코드를 실행하도록 만든다.
•
데이터 버젼 관리를 가끔 무시한다. 부호화 library 에서 상위, 하위 호환을 고려하지 않아 문제가 되기도 한다.
•
효율성을 등한시 하는 경우가 있는데 대표적인 예가 java의 serializable 이다.
Json과 XML, 이진 변형 (Json, XML, and Binary Variants)
JSON과 XML을 경쟁자이며 둘다 text 형식으로 압도적으로 인기가 좋다.
xml은 장황하고 복잡하다 비판받고, JSON은 그에 비해 단순하다 또한, 강력하지 않지만 CSV도 있다. 다음은 피상적 문법 외에 차이점과 문제점을 나열한다.
•
수와 숫자에 대한 모호함이 있다.("15", 15를 구분하지 못하는 문제)
◦
부동 소수점을을 구별하지 않고 정밀도를 지정하지 않는다.
•
이 넘어가면 부동 소수점 문제가 발생한다. (twitter는 이 문제를 해결하기 위해 64bit 숫자를 사용한다)
◦
XML 도 스키마가 있지만 구현이 난해하며 일반적이지 않다
•
XML, JSON은 unicode를 잘 지원한다. 그러나 binary variants 를 지원하지 않는다.
◦
binary variant 는 매우 유용하기 때문에 base64로 encoding 하여 전송하여 이 문제를 해결한다.
◦
하지만 정공법이 아니고 데이터 크기가 33% 증가한다.
•
CSV는 스키마가 없기 때문에 좋지만, 그렇기 때문에 매우 모호하고 이 모호함을 application 에서 해결해야 한다.
이진 부호화 Binary Encoding
조직내에서만 사용하는 데이터라면 최소공통분보 부호화 형식(lowest-common-denominator encoding format)을 사용해야 한다는 부담감이 덜하다. json, xml과 비교해 더 적은 공간, 더 간결하고 더 빠른 파싱인데 data set이 적다면 별 의미가 없지만, terabyte 급이 된다면 이야기가 달라진다.
Json도 이진 형식과 비교하면 더 많은 공간을 사용한다. 이러한 관점이 json(message pack, BSON, BJSON, BISON, smile) 등으로 사용 가능한 이진 부호화 개발이 되었다.(하지만 json 만큼 사용되진 않음)
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
JSON
복사
계속해서 이 json을 예시로 사용하며 4-1 예시로 명명한다.
json을 이진 부호화 한다고 해도 객체의 필드 이름을 포함해야 한다.
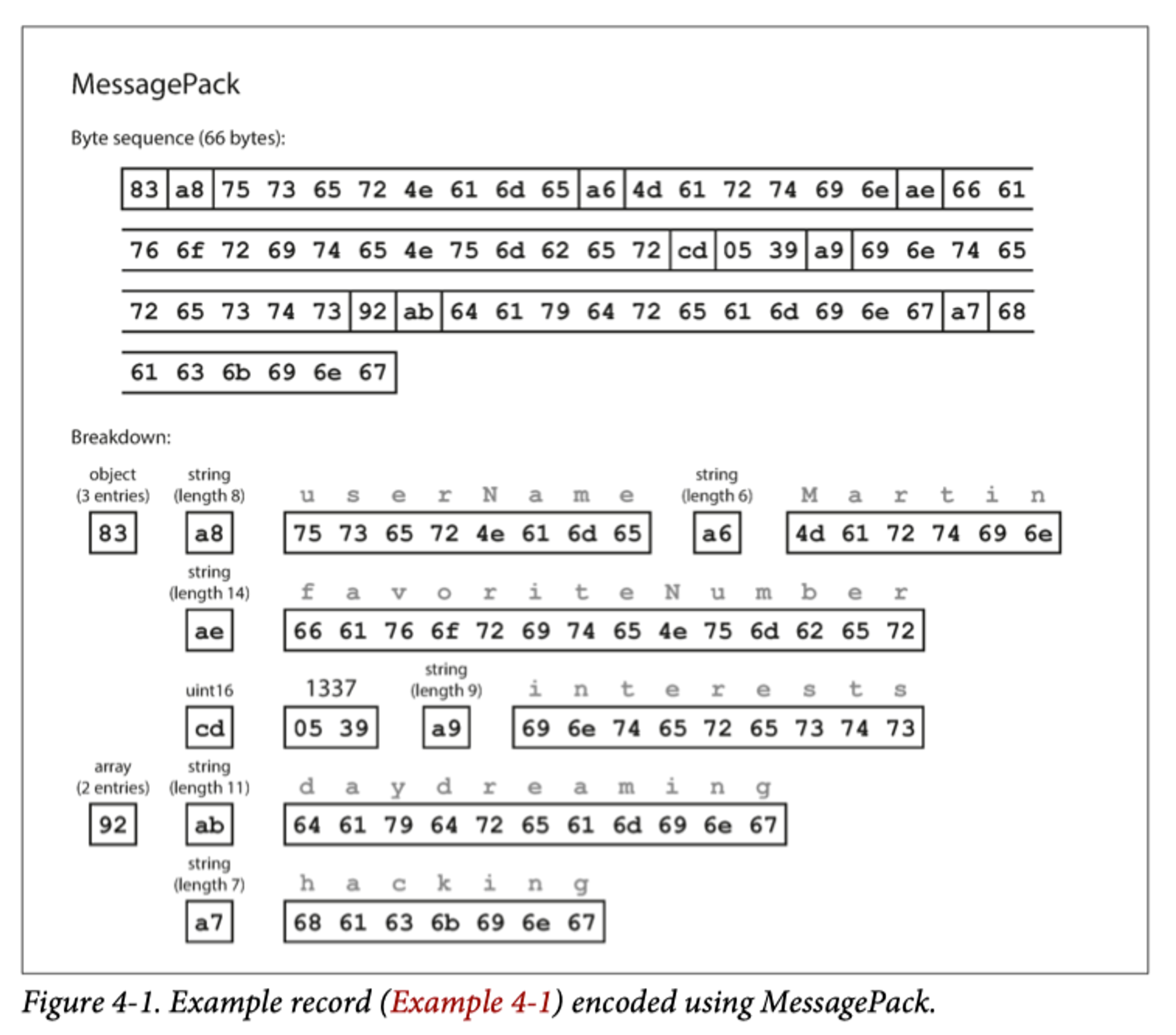
위의 json 데이터를 message pack 으로 부호화 했다.
한 칸 = 1 Byte, Message pack 에 대한 설명
1.
첫 필드 0x83은 3개의 필드를 가진 객체라는 뜻이다.
•
3개 필드: 0x03
•
객체: 0x80
•
객체가 15개 넘는 필드를 가지고 있어 4bit에 맞지 않는 경우 다른 타입의 지시자를 얻어 필드 수를 2개로 나누거나 숫자를 4byte로 부호화 한다
2.
0xa8은 이어지는 내용이 8byte 길이의 문자열 이라는 뜻이다
•
0x08 → 8 byte : username
•
0xa0 → fixed string
3.
그 다음 8byte는 "userName" 에 해당하는 ascii 값이다.(앞에서 8byte임을 명시했기 때문에 종료 위치를 표시할 필요가 없다)
4.
다음 7 byte는 0xa6 이 붙어 Martin 6글자 문자열을 encoding 한다.

5.
cd → uint16
•
16 bit 숫자를 0xcd로 명시한다
uint 16 stores a 16-bit big-endian unsigned integer
+--------+--------+--------+
| 0xcd |ZZZZZZZZ|ZZZZZZZZ|
+--------+--------+--------+
Plain Text
복사
•
uint 32 → 0xce, unit 64 → 0xcf
•
sign 8 → 0xd0, sign 16 → 0xd1
절약된 공간을 보면 이진 부호화인 경우 66byte 이고, json은 81byte 이다.
이 차이가 가독성을 해칠만큼 가치 있는것인지 확실하지 않다.
스리프트와 프로토콜 버퍼 Thrift and Protocol Buffers
아파치의 thrift와 protocol buffer를 줄여 protobuf 라 하는데 이 원리를 이용한 이진 부호화 library 이다.
스리프트와 프로토콜 버퍼 모두 데이터를 정의하는 스키마가 필요하다.
struct Person {
1: required String userName,
2: optional i64 favoriteNumber,
3: optional list<String> interests
}
YAML
복사
thrift interface definition language IDL로 스키마를 기술한다.
message Person {
required string username = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
YAML
복사
protocol buffer 의 스키마
이 두 가지를 이진 부호화로 본다면 다음과 같으며 thrift 부터 살펴보자
thrift는 이진 부호화 방식이 binary protocol 과 compact protocol 두가지로 표시한다
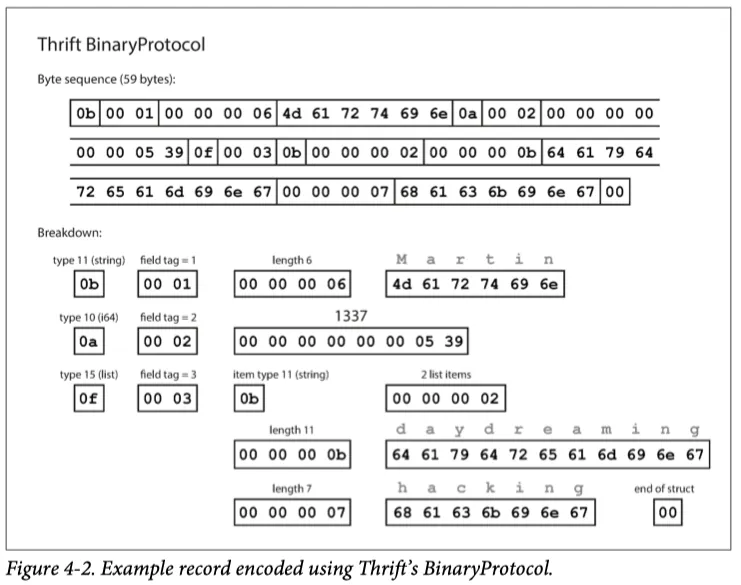
binary protocol - thrift의 binary protocol 스키마로 부호화된 모습
•
타입(string, int, list) 주석이 있고 필요한 경우 길이 표시가 있다.
•
데이터에 나타난 문자열은 이전과 동일하게 ascii 또는 UTF-8로 부호화 한다.
•
Message pack 과 차이점은 field 이름이 포함되지 않고 field tag 를 포함한다
◦
이 숫자는 schema에 명시된 숫자이다.
thrift의 compact protocol 이다. 34 byte 밖에 안된다!
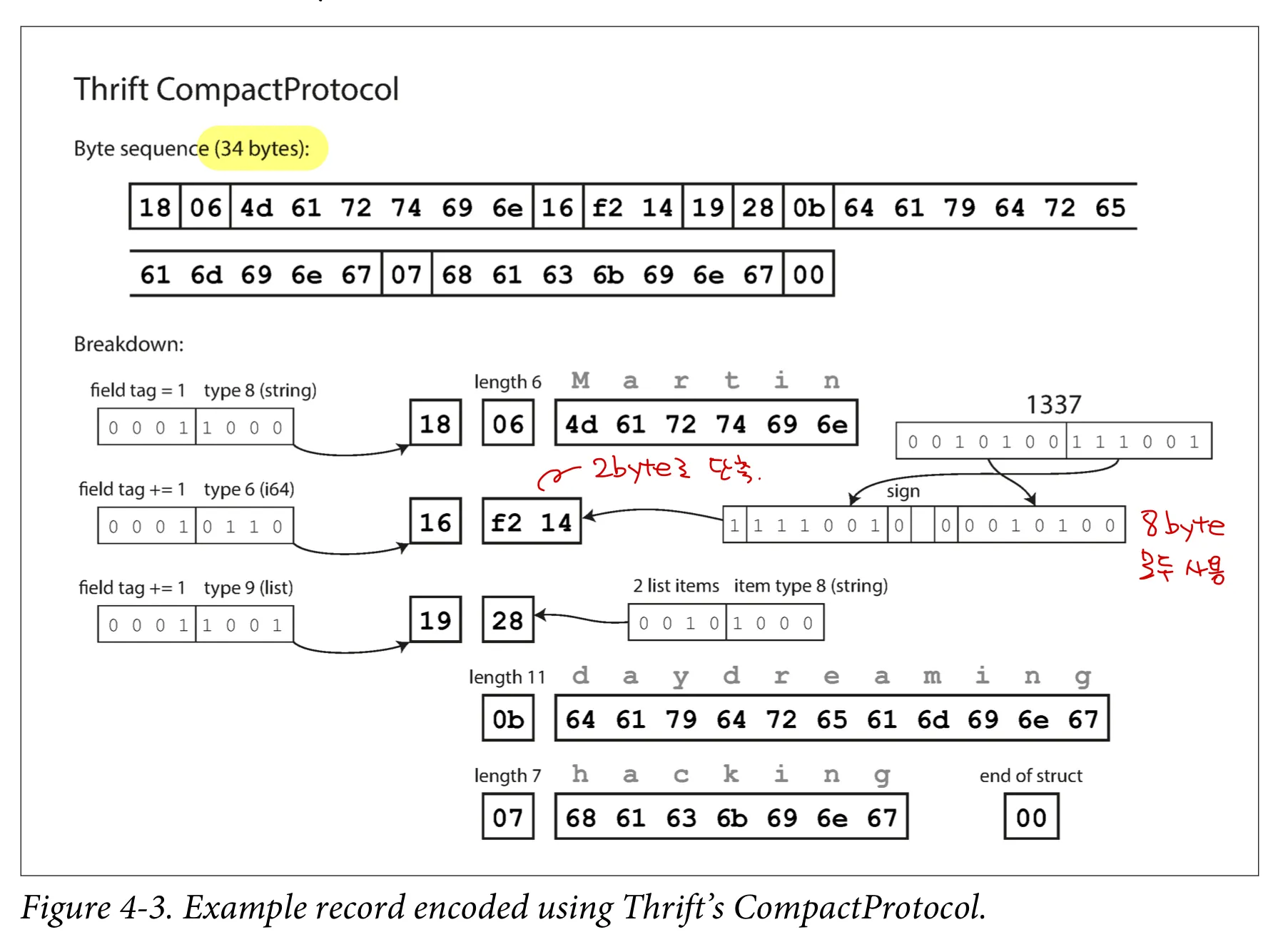
•
필드 타입과 태그 숫자를 단일 byte로 줄였다.
•
숫자는 2byte로 부호화 한다 (만약 더 큰 수이면 그만큼 더 많은 byte를 사용한다)
마지막으로 protocol buffer는 다음과 같이 변경된다.
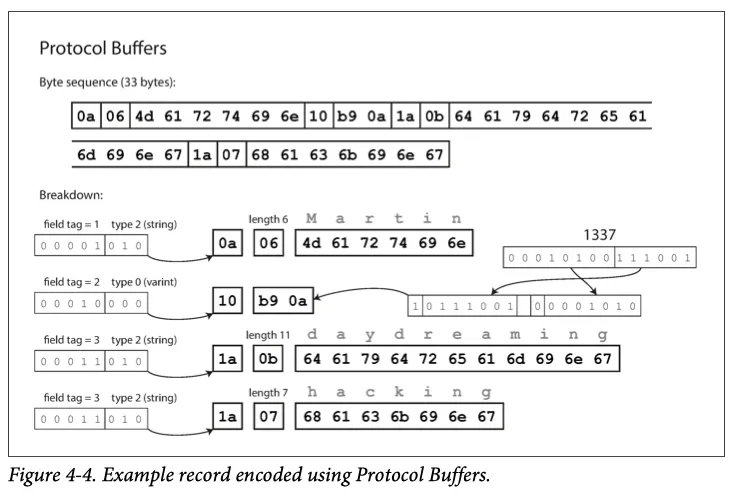
저장 방식이 다르지만 compact protocol 과 매우 비슷하고 33 byte로 만든다
필드 태그와 스키마의 발전 Field tags and schema evolution
스키마의 발전이 한국어로 봤을땐 스키마 자체가 어떠한 발전을 이룬것 같지만, 책에서 의미하는 뜻은 데이터가 변경되어 스키마도 이에 따라 변경이 동반됨을 의미한다.
호환성에 대해 다시 보고 오자
데이터에 새로운 필드가 추가되거나 변경되었을때 어떻게 thrift 와 protocol buffer 의 스키마에 반영할까?
스키마를 살펴보면
1.
encoding 된 record 는 그저 부호화된 필드의 연결이다.
2.
data type 은 주석(annotation)으로 달고, 필드는 태그 숫자로 식별한다
•
필드가 숫자 태그를 이용해 연결되기 때문에 이름을 바꾸는건 얼마든지 바꿀 수 있다.
3.
필드 태그(숫자)의 변경은 모든 부호화된 데이터를 인식할 수 없게 만들기 때문에 변경이 불가능하다
•
하지만 새로운 필드 태그를 추가하는 것은 가능하다
•
상위 호환성 (예전 코드는 현재 데이터를 읽을 수 있어야 한다)
◦
새로운 코드로 기록한 데이터를 읽으려 할 때 인식할 수 있는 tag 번호인지만 확인하여 인식이 안되면 자연스럽게 무시한다
•
하위 호환성 (지금 코드는 예전 코드로 생성한 데이터를 읽어야 한다)
◦
최초 배포 후에는 required 로 field를 추가할 수 없다. (그럼 예전 코드로 생성한 데이터를 읽을 수 없다)
◦
optional field 만 삭제할 수 있다.
데이터 타입과 스키마 발전 Datatypes and schema evolution
field의 data type을 변경하는 것은 어떨까?
변경이야 가능하지만, 값이 달라질 수 있다. 하위 호환은 문제 없지만, 상위 호환 개념으로 오면 문제가 발생한다.
•
32 bit 정수를 사용하던 field 를 64bit으로 바꾸면 새로운 코드는 이전 데이터를 읽을 때 앞에 이진수에 0을 채우면 된다.
•
하지만 상위호환은 32 bit를 읽는 코드로 64bit 데이터를 읽을경우 잘려 정확한 데이터가 아니게 된다.
•
protocol buffer 의 repeated 필드는 예외적으로 optional 을 repeated 로 변경해도 문제가 없다
◦
필드 데이터가 없는 경우 size 0 인 list로 인식하도록 상위호환이 된다.
아브로 Avro
아파치 아브로[20]는 앞선 이진 부호화 형식의 한 종류인데 하둡에서 thrift 가 적합하지 않아 2009년 하둡의 하위 프로젝트로 시작되었다.
스키마는 IDL과 json 두가지가 있다.
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
YAML
복사
{
"type": "record",
"name": "Person",
"fields": [
{
"name": "userName",
"type": "string"
},
{
"name": "favoriteNumber",
"type": [
"null",
"long"
],
"default": null
},
{
"name": "interests",
"type": {
"type": "array",
"items": "string"
}
}
]
}
YAML
복사
앞선 이진 부호호와 다른점은 tag 번호가 없다.
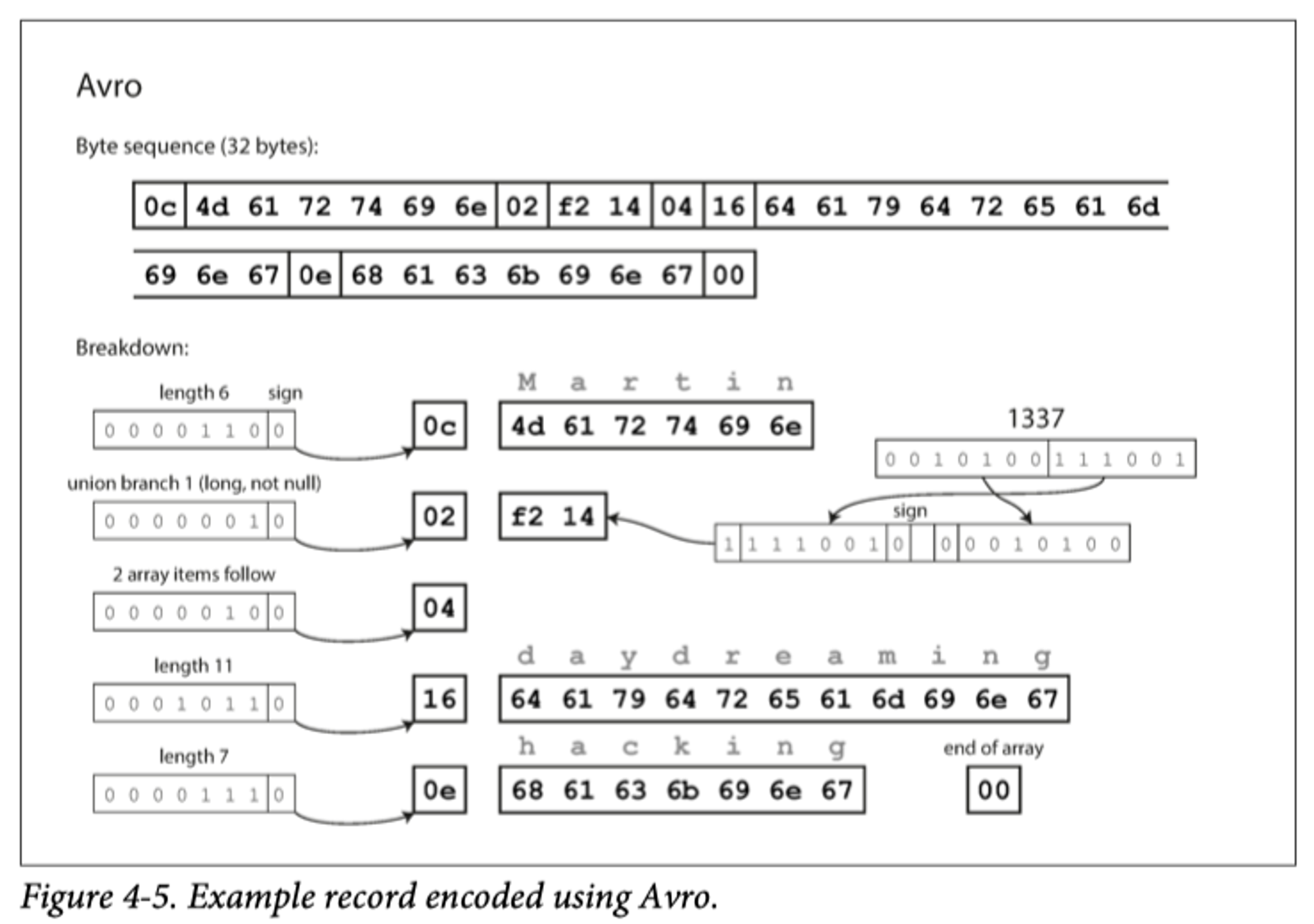
•
부호화는 단순히 연결된 값으로 구성된다.
•
문자열은 길이 다음에 UTF-8 byte 가 이어지지만, 문자열임을 알려주는 정보가 없다.
•
아브로를 사용해 parsing 하려면 schema를 먼저 읽고 각 필드의 데이터 타입을 기억해야 한다
◦
정확히 같은 스키마를 사용해야 하며 쓰는곳과 읽는곳의 스키마가 다르면 복호화가 일치하지 않는다
쓰기 스키마와 읽기 스키마 The writer's schema and the reader's schema
•
쓰기 스키마
◦
파일, db, network 를 통해 전송 목적으로 부호화하기 위해 schema 버젼을 사용해 데이터를 부호화한다
◦
application 에 이 스키마를 포함할 수 있다.
•
읽기 스키마
◦
file, db, network 에서 읽은 데이터를 복호화할때 특정 스키마로 복호화를 기대한다.
◦
application 코드는 이 스키마에 의존한다.
◦
복호화 코드는 application 이 빌드하는 동안 스키마에서 생성된다.
아브로의 핵심
•
읽기 스키마와 쓰기 스키마가 일치하지 않아도 되는 것이며 단지 호환 가능하면 된다.
◦
복호화 할때 두 스키마를 함께 보고 쓰기 스키마에서 읽기 스키마로 데이터를 변환해 그 차이를 해소한다.
•
읽기 스키마와 쓰기 스키마의 필드 순서가 달라도 상관없다.
•
쓰기 스키마엔 있는데 읽기 스키마에 없다면 그 필드는 skip 한다.
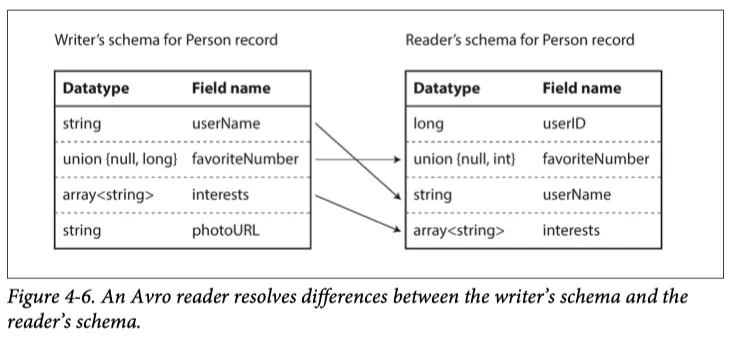
avro 스키마는 읽을 때 필드의 순서가 달라도 문제 없다. 복호화 할때 두 스키마를 비교해 이 차이를 극복한다.
만약 두 스키마가 일치하지 않아도 읽기 스키마에 선언된 기본값을 사용해 채울 수 있다.
스키마 발전 규칙
•
상위 호환(지금 데이터를 후에도 읽을 수 있다.)
◦
새로운 버젼의 쓰기 스키마와 예전 버전의 읽기 스키마를 가질 수 있다.
◦
필드 이름 변경 불가
•
하위 호환(예전 데이터를 지금도 읽을 수 있다)
◦
새로운 버젼의 읽기 스키마와 예전 버젼의 쓰기 스키마를 가질 수 있다.
◦
필드 이름 변경을 추적할 수 있기 때문에 필드 이름 변경 가능
이러한 호환성을 유치하기 위해 default 가 있는 필드만 추가 삭제가 가능하다
만약 예전 스키마에 없는 값이 읽기 스키마에 있으면 기본값으로 대체가 가능하다
avro 는 null 이 기본값으로 허용되지 않으며, null을 기본값으로 가지려면 union type 을 사용해야 한다.
protocol buffer, thrift 처럼 optional, required 와 같은 개념을 가지지 않지만, 기본값으로 이를 극복한다.
따라서 avro 는 data type을 변경하는 것도 가능하다.
필드 이름은 변경이 가능하지만, 조금 까다롭다.(대신 읽기 스키마는 별칭을 가지고 이 별칭으로 매핑을 할 수 있다)
그러면 쓰기 스키마는 무엇인가? But what is the writer's schema?
어떻게 읽기 스키마는 특정 쓰기 스키마와 매핑이 될까? 어떤 쓰기 스키마를 사용했음을 알게될까? 모든 record에 이것을 저장할 수 없다. 그러면 절약한 공간이 줄어들어 굳이 이진 부호화를 선택할 이유가 없어진다.
avro는 상황에 따라 다르다.
•
많은 레코드가 있는 대용량 파일
◦
하둡을 사용한다는 가정하에서, 하둡은 모두 동일한 스키마로 수백만개 record를 포함하는 파일을 저장하는 용도이기 때문에 동일한 스키마의 영향을 받는다
•
개별적으로 기록된 record 를 가진 DB
◦
다양한 쓰기 스키마가 서로 다른 시점에 사용되었을 수 있다.
◦
쓰기 스키마가 변경되어 record 시작 부분에 스키마 버젼이 명시된다.
•
network 연결을 통해 record 전송
◦
network 에 스키마 버젼 합의를 할 수 있다.
◦
RPC 프로토콜이 이 처럼 동작한다
동적 생성 스키마 Dynamically generated schemas
tag 번호가 없다는 점이 동적 생성 스키마에 더 친숙하다 → 태그 번호를 바꾸는것이 불가능했다.
•
RDB 스키마에서 avro 스키마를 쉽게 생성할 수 있다.
•
RDB의 테이블이 변경되어 스키마가 달라져야 하면 alter table 이 실행될 때 avro 스키마를 새로 생성하거나, 삭제한다.
•
이렇게 갱신된 쓰기 스키마는 필드 이름으로 mapping 되었기 때문에 read 스키마와 매칭이 가능하다
반면 thrift, protocol buffer 는 필드 태그를 수동으로 할당해야 한다. (자동으로 할 수 있지만, 이전에 사용하던 필드 태그가 할당되지 않도록 조심해야 한다.)
아브로는 스키마가 동적으로 변경될 가능성을 고려하여 설계되었다.
코드 생성과 동적 타입 언어
•
thrift, protocol buffer 는 코드 생성에 의존한다.
◦
java, c 와 같은 compile 언어에 유용하다. 컴파일 단계가 있고, 이때 생성되는 코드를 schema 를 확정하기 때문이다.
◦
코드 생성: 스키마를 사용해 데이터를 변경하는 코드를 만들어낸다.
◦
코드 생성 시점이 compile 이기 때문에 스키마가 변경되면 compile을 다시 해야 하므로 스키마 변경에 장애물이 된다.
•
python, ruby 같은 동적 타입 언어는 compile time 이 없어 코드를 생성하는것이 중요하지 않다.
◦
avro 는 이러한 점에서 compile 언어, interpreter 언어를 선택하여 사용할 수 있어 코드 생성을 선택적으로 제공한다.(하지만, 코드 생성을 안해도 됨)
◦
avro는 동적 타입 언어에 thrift, protocol buffer 에 비해 더 효율적으로 적용할 수 있다.
RDB에서 스키마를 추출해 container 파일로 만들때도 파일을 열어 json 을 보는것 같이 데이터를 볼 수 있다.
스키마의 장점 The Merits of Schemas
1.
xml 이나 json 이 제공하는 스키마 보다 훨씬 간단하다
2.
유효성 검사 규칙 적용이 가능하다 (정규 표현식, 숫자의 범위 등)
이러한 부호화 기반의 idea 는 새로운 기술이 아니다 1984년 ASN.1 프로토콜에 이와 비슷한 개념이 사용되었다. ASN.1 은 심지어 SSL 인증서를 부호화 하기 위해 여전히 사용되고 있다.
또한 스키마를 이용한 부호화를 data system 측에서 직접 구현하는 것도 많다.
Json, xml, csv 가 널리 사용되지만, schema를 기반으로 한 이진 부호화 또한 가능한 선택이다.
이진 부호화가 좋은 속성이 많다.
•
부호화된 데이터는 필드 이름을 생략할 수 있어, data 크기가 json 에 비해 작을 수 있다.
•
스키마는 유용한 문서화 형식이다.
◦
복호화에도 필요하므로 스키마는 최신 상태로 유지가 되어 문서화에 사용되면 최신 데이터 타입을 반영할 수 있다.
•
schema database 를 사용한다면 상위 호환, 하위 호환을 확인할 수 있다.
•
정적 type 언어 사용자에게 schema 에서 코드를 생성하는 기능은 compile 시점에 타입 체크가 된다.
메모리를 공유하지 않는 하나의 process 에서 다른 process로 데이터를 전달하는 보편적인 방법을 알아보며 이때 사용할 부호화 방법과 상위, 하위 호환성에 대해서 알아보았다.
상, 하위 호환성은 한 번에 모든것을 변경할 필요 없이 시스템의 다양한 부분을 독립적으로 업그레이드 하는데 필요한 기능이다.
데이터 플로 모드 Modes of Dataflow
메모리를 공유하지 않는 하나의 process 에서 다른 process로 데이터를 전달하는 보편적인 방법을 알아본다.
•
DB를 통해
•
서비스 호출을 통해
•
비동기 메세지 전달을 통해
데이터 베이스를 통한 데이터 플로 Dataflow Through Databases
•
DB에 기록하는 프로세스는 encoding
•
DB에서 읽는 process 는 decoding
단일 프로세스만 DB에 접속하면
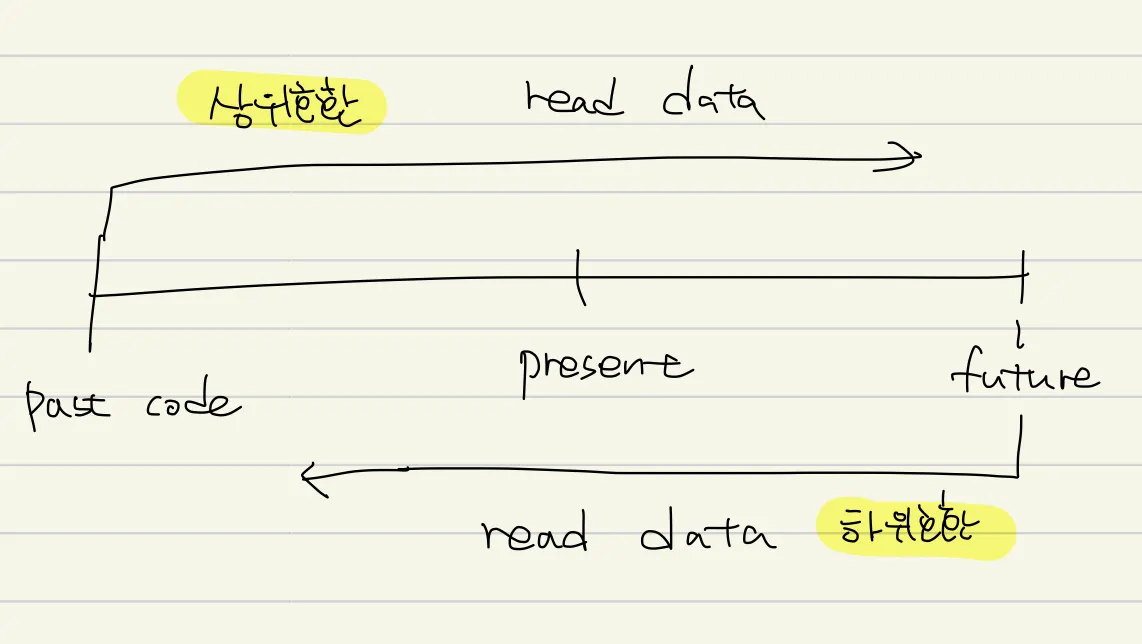
DB에 저장하는 일은 미래의 자신에게 메세지를 보내는것이다.
따라서 하위 호환성이 필요하다 → 미래의 코드가 지금 저장한 데이터를 읽을 수 있어야 한다
다양한 프로세스가 DB에 접근한다면
•
가장 흔한 방식으로 application 이거나 서비스일 수 있다.
•
순회식으로 배포를 한다면 새로운 버젼을 배포하는 몇몇 instance 는 예전 코드로 데이터를 저장하고 갱신중일 것이다.
◦
상위 호환성이 필요해진다. 새로운 코드로 저장한 데이터를 예전 코드가 읽을 수 있다.
◦
새로운 코드가 저장한 데이터를 예전 코드가 갱신한다면 어떨까? 이때 바람직한 예시는 예전 코드가 모르는 field의 경우 삭제되지 않고 유지되는 것이다.
•
부호화는 모르는 필드를 건들이지 않지만, DB 관점에서는 유실될 수 있다.
◦
알지 못하는 필드를 DB에서 복호화 하고, 다시 부호화 하는 과정에서 유실될 수 있다.
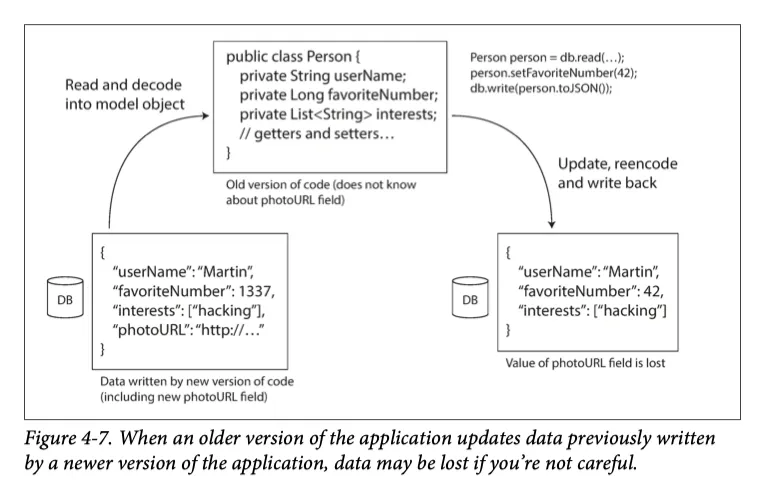
옛날 버젼의 코드가 update 쿼리를 실행하면서 새로운 버젼 코드로 생성된 특정 필드가 제거되었다
이러한 문제는 대처가 어렵지 않다. 다만 유실이 발생할 수 있다는 것을 인지하기만 하면 된다.
다양한 시점에 기록된 다양한 값 Different values written at different times
DB는 언제나 데이터를 갱신할 수 있다. 이 데이터는 5년전 데이터일 수도 있고, 5ms 전에 기록됐을 수 있다. DB에 별다른 기능을 실행시키지 않는다면 원래 부호화 그대로 유지되어 있을 것이다.
→ 데이터가 코드보다 더 오래산다 data outlives code
data를 새로운 스키마를 통해 rewrite 할수 있지만(migration) 이것은 비용이 매우 큰 작업이다.
통상적으로 RDB는 스키마 변경시 새로운 필드를 null을 기본값으로 갖는 새로운 칼럼을 추가한다.(linked in 에서 사용하는 문서 db 에스프레소는 avro를 사용한다)
보관 저장소 Archival storage
백업 목적으로 data warehouse 에 적재하기 위해 DB snapshot 을 수시로 만든다고 가정하자
dump 된 데이터는 최신 스키마 하나를 사용해 부호화 한다 (저장은 여러 스키마로 수행되었더라도)
이런 타입은 avro 의 특징을 사용해 avro 객체 컨테이너 파일과 같은 형식이 적합하다
서비스를 통한 데이터 플로: REST와 RPC Dataflow through Services: REST and RPC
네트워크상 서버를 배치하는 방식
•
client와 server로 네트워크를 하고 서버는 network에 API를 공개하고 client는 요청을 만들어 서버에 접근할 수 있다. 이때 API를 서비스 라고 한다
•
웹은 HTML, CSS, JS, image 등을 제공하며 GET 요청을 통해 데이터를 받고 POST 요청을 통해 데이터를 전송한다
•
웹에서 웹 브라우저만 유일한 client는 아니다.
◦
XMLHttpRequest를 사용해 HTTP를 보내면 XMLHttpRequest가 client일 수 있다.
◦
모바일 앱, 데스크탑 앱 등등
•
서버 자체가 다른 서비스의 client 일 수 있다.
◦
이러한 방식을 SOA(Service-oriented architecture) 이것이 개선되어 MSA(Microservices architecture)라 불린다.
◦
MSA와 같이 대용량 application 의 기능 영역을 소규모 서비스로 나누는 데 사용한다.
서비스와 Database는 여러가지 측면에서 유사하다. 단, 차이는 service 는 비즈니스 로직에 기반하여 입출력을 제한하고, 정해진 입출력만 허용해 API를 공개한다. → 캡슐화
MSA, SOA의 목표는 서비스를 배포와 변경에 독립적으로 만들어 application의 유지보수를 더 쉽게 만드는데 있다. 즉 변경이 잦을것을 대응하기 위한 것이며 새로운 버젼 출시가 빠르기 때문에 API간 호환이 필요하다.
이 장의 핵심 내용이다.
웹 서비스
기본 protocol을 HTTP를 사용하며 이때 웹서비스라 한다.(하지만 웹 뿐만 아니라 다양한 상황에서도 사용된다)
→ 이 문장에서 의미하는 웹의 상황은 browser만 의미하는거 같다
다른 상황에서도 사용되는 예시
1.
HTTP요청을 보내는 client application (mobile앱, ajax) 에서 요청
2.
MSA, SOA 아키텍쳐 일부로 같은 조직의 다른 서비스에 요청하는 서비스
3.
백엔드간 시스템에서 데이터를 교환하는 일부 (신용카드 처리, 사용자 데이터를 제공하는 OAuth)
이런 웹 서비스에서 대중적인 방법은 REST와 SOAP가 있다.
REST
•
HTTP 토대 원칙
•
간단한 data type 을 강조한다
•
URL resource를 식별한다
•
캐시 제어, 인증, 콘텐츠 유형 협상을 다룬다
•
SOAP이 비해 인기있다.
SOAP
•
API 요청을 위한 XML 기반 프로토콜이다.
•
HTTP 상에서 일반적으로 사용하지만, HTTP와 독립적이며 HTTP 기능을 사용하지 않는다
◦
그 대신 WS-*라 하여 Web Service Framework 를 제공한다.
•
웹 서비스 기술언어 (Web Service Description Language) 또는 WSDL 이라 하는 XML 기반 언어를 사용해 기술한다.
•
사람이 읽을 수 없도록 설계되어 도구나 IDE에 크게 의존한다
기업은 RESTful API 를 통한 간단한 접근 방식을 선호한다
원격 프로시저 호출(RPC) 문제 The problems with remote procedure calls(RPCs)
•
웹 서비스는 network 상에서 API를 호출하는 여러 기술중 가장 최신의 형상일 뿐이다.
이러한 웹 서비스는 원격 프로시저 호출(Remote procedure call, RPC)의 아이디어를 기반으로 한다.
RPC 모델은 원격 network 서비스 요청을 같은 process 안에서 특정 method를 호출하는것 처럼 사용 가능하게 해준다. (이런 추상화를 location transparency 라 한다)
이 개념이 매우 편리해 보이지만, 로컬 함수 호출과 다르기 때문에 RPC 방식은 근본적인 결함이 있다.
•
로컬 함수의 경우 예외를 내거나, 값을 반환하지 않을 수 있다.
◦
네트워크는 timeout으로 결과가 없는것 처럼 만들 수 있지만, 무슨일이 일어났는지 알 방법이 없다.
◦
정말 요청을 제대로 보낸건지 아닌지를 구분하기도 어려워진다
•
실패한 네트워크 요청이 처리를 실행되지만, 응답만 유실된 경우일 수도 있다.
◦
이때 멱등성 idempotence을 적용하지 않는다면 재시도는 여러 작업이 중복 실행될 수 있다.
•
로컬 함수 호출에 비해 훨씬 시간이 많이 소요되고 그 소요시간을 예측할 수 없다.
•
로컬함수는 pointer를 효율적으로 전달할 수 있다. 네트워크 요청은 부호화 하여 매개변수로 보내야 한다.
◦
만약 큰 객체를 보내야 하는 상황이라면?
•
client와 서비스는 다른 언어로 구현할 수 있다. 따라서 RPC 프레임워크는 하나의 언어에서 다른 언어로 데이터 타입을 변환해야 한다.
이러한 한계와 문제가 있더라도 네트워크 통신을 로컬 함수처럼 사용하려는 수고는 비효율적인 것이 아니다.
RPC의 현재 방향 Current directions for RPC
이러한 문제에도 불구하고 RPC는 사라지지 않았으며, 지금까지 언급한 이진 부호화 위에 RPC 프레임워크가 개발되었다.
•
thrift, avro 는 RPC 지원 기능을 내장하고 있으며
•
gRPC는 protocol buffer를 이용해 RPC를 구현했다.
•
Finagle은 thrift를 사용하고 Rest.li는 HTTP 위에서 json을 사용한다.
•
차세대 framework는 로컬 함수 호출과 네트워크 요청이 다르다는 사실을 분명히 한다.
◦
Rest.li는 비동기 작업을 캡슐화 하기 위해 future promise를 사용한다
•
요청 라우팅에서 다루겠지만, service discovery 기능을 제공한다.
◦
client가 server를 찾을 수 있는 IP주소, port 번호 제공 기능
•
JSON 보다 이진 부호화 형식이 우수한 성능을 제공할수도 있다.
REST
•
웹 브라우저, 커맨드 라인 curl을 사용해 디버깅에 적합하다
•
다양한 도구(서버, 캐시 로드 밸런서, proxy, 방화벽, 모니터링, 디버깅 도구, 테스트 도구)가 있다.
데이터 부호화와 RPC의 발전 Data encoding and evolution for RPC
발전이 의미하는 것은 스키마가 변경되는 것을 의미한다.
발전성을 원한다면, RPC client와 서버를 독립적으로 변경하고 배포할 수 있어야 한다.
"모든 서버를 먼저 갱신하고 client를 갱신해도 문제가 없다"고 가정한다
•
RPC의 상하위 호환 속성은 사용된 모든 부호화로부터 상속된다.(모든 부호화의 상하위 호환 기능)
◦
thrift, gRPC, avro RPC는 각 부호화 형식의에 호환성 규칙이 있고, 이에 따라 발전이 가능하다
◦
SOAP 에서 요청과 응답은 XML 스키마로 지정된다. 발전은 가능하지만, 문제가 있다.
◦
RESTful API는 응답에 JSON을 사용한다(공식적인 스키마는 없음)
API 버젼 관리가 반드시 어떤 방식으로 동작해야 한다는 합의는 없으나, 일반적으로 HTTP Aceept 헤더에 버전 번호를 사용하는 방식이 일반적이다.
지금까지 하나의 프로세스에서 다른 프로세스로 전달하는 다양한 방식을 살펴봤다.
REST와 RPC는 하나의 프로세스가 다른 네트워크를 통해 다른 프로세스와 통신을 주고 받으며 빠른 응답을 기대하는 방식이다.
메세지 전달 데이터 플로 Message-Passing Dataflow
RPC와 DB간 비동기 메세지 전달 시스템을 살펴본다(asynchronous message-passing system)
이 시스템은 client 요청(메세지)를 낮은 지연시간으로 다른 프로세스에 전달한다는 점에서 RPC와 동일하다
메세지를 네트워크 연결로 전송하지 않고 임시로 message broker(message queue)나 message-oriented middleware 라는 중간 단계를 거쳐 전송한다는 점이 DB와 유사하다
Message broker를 사용했을때 장점(DB에 바로 데이터를 전송하거나 받아오는 것과 비교했을때)
•
수신자가 사용 불가능하거나 과부하 상태면 message broker는 buffer 역할을 하여 안정성이 향상된다
•
죽었던 process에 메세지를 다시 전달할 수 있어 메세지 유실을 예방한다
•
송신자가 수신자의 IP, port를 알 필요가 없다
•
하나의 메세지를 여러 수신자에게 전송할 수 있다.
•
논리적으로 송신자, 수신자가 분리된다. (누가 publish 하고, 누가 consume 하는지 몰라도 된다)
메세지 전달 통신은 단방향이다. 이 점이 RPC와 다르다.
송신 process는 message 응답을 기대하지 않으며, 응답을 전송하는거야 가능하지만, 보통 별도 채널에서 수행한다.
Message broker
최근에는 RabbitMQ, ActiveMQ, NATS, Apache Kafka 같은 오픈소스 구현이 대중화 됐다.(11장에서 다룸)
세부적인 시맨틱은 구현과 설정에 따라 다르지만, 일반적으로 다음과 같다.
1.
프로세스가 하나의 메세지 이름이 지정된 큐나 토픽으로 전송한다
2.
브로커는 해당 큐나 토픽을 소비자(구독자)에게 전달한다
3.
동일한 토픽에 여러 producer, consumer 가 있을 수 있다.
4.
토픽은 단방향 data flow 만 제공한다.
•
소비자 스스로 메세지를 다른 토픽으로 게시할 수 도 있고
•
원본 메세지 송신자가 소비하는 응답 큐로 게시할 수 있다.
5.
특정 data model을 강요하지 않는다. → 단점일 수도 있다.
6.
메세지는 모든 부호화 형식을 사용할 수 있도록 설계되어 있다.
선택한 부호화가 상하위 호환성을 모두 가지기만 한다면 message broker 에게 publisher 와 소비자를 변경해 임의의 순서로 배포할 유연성도 얻을 수 있다.
분산 액터 프래임워크 Distrubuted actor framework
actor model은 동시성을 위한 프로그래밍 모델이다.
•
thread(경쟁조건, 잠금, 교착 상태 와 관련된 문제)를 직접 처리하는 대신 로직이 actor에 캡슐화 된다.
•
액터는 로컬 상태를 가질 수 있고, 비동기 메세지의 송수신으로 다른 actor와 통신한다.
•
메세지 전달을 보장하지 않기 때문에 메세지 유실이 발생할 수 있다.
•
액터는 하나의 client나 entity를 나타낸다
•
한번에 하나의 메세지를 처리하는 방식으로 thread 에 대한 걱정을 하지 않아도 된다
분산 액터 프레임워크는 여러 node 간 application 확장에 사용하는데 송신자, 수신자가 같은 노드이건 아니건 관계없이 동일한 메세지 전달 구조를 사용한다.
만약 다른 노드이면 부호화되고 network를 통해 전송된다.
액터 모델은 메세지가 유실된다는 가정을 가지기 때문에 위치 투명성은 RPC 보다 actor 모델에 더 잘 동작한다(로컬과 원격 통신간 불일치를 줄여준다)
분산 액터 프레임워크는 순회식 upgrade를 수행을 원할때 메세지가 새로운 버젼을 수행하는 노드에서 예전 버젼을 수행하는 노드로 전송하거나 그 반대 경우도 있으므로 상하위 호환에 유의해야 한다.
정리
•
데이터 구조를 네트워크나 디스크 상의 이진 부호화 방법에 대해 살폈다.
◦
이진 부호화는 효율성뿐 아니라 application architecture 와 배포의 선택 사항에도 영향을 미친다.
•
순회식 upgrade 중이거나 다양한 버젼의 client가 있을땐 상하위 호환에 신경써야 한다.
◦
서비스에 끈김 현상이 없기 때문에 rolling update를 추천한다
◦
결함이 있는 경우 빠른 롤백이 가능하다
•
다양한 부호화 형식과 호환속성
◦
프로그래밍 언어에 특화된 부호화는 단일 프로그래밍 언어에만 적용된다.
▪
상하위 호환성을 제공하지 못하는 경우가 있다.
◦
JSON, XML, CSV 같은 텍스트 형식은 널리 사용된다.
▪
이들간 호환성은 data type 을 사용하는 방법에 달려 있어 스키마가 있으면 유용할 수 있으나 반대로 불편할 수 있다.
◦
thrift, protocol buffer, avro 같은 이진 스키마 기반은 짧은 길이로 부호화 되어 효율적이고, 정의된 상위 호환성과 하위 호환성이 있다면 효율적인 부호화가 된다.
◦
단, 이진 부호화는 사람이 읽을 수 있도록 하기위해 복호화 과정이 수반되어야 한다.
또한 데이터 부호화에 대한 시나리오 data flow mode
•
DB에 기록하는 프로세스가 부호화, 읽는 프로세스가 복호화
•
client 요청을 부호화 하고, 서버 요청을 복호화 하고, 응답을 부호화 하고, client가 부호화 한다
◦
RPC, REST API 가 이에 해당한다
•
송신자 부호화, 수신자 복호화 메세지를 서로 전송하는 비동기 전달(message broker, actor) 이 있다.
